Judgment and Decision Making, Vol. 10, No. 1, January 2015, pp. 86-96
Tailored proper scoring rules elicit decision weightsArthur Carvalho* |
Proper scoring rules are scoring methods that incentivize honest
reporting of subjective probabilities, where an agent strictly
maximizes his expected score by reporting his true belief. The
implicit assumption behind proper scoring rules is that agents are
risk neutral. Such an assumption is often unrealistic when agents
are human beings. Modern theories of choice under uncertainty based
on rank-dependent utilities assert that human beings weight
nonlinear utilities using decision weights, which are differences
between weighting functions applied to cumulative probabilities.
In this paper, I investigate the reporting behavior of an agent
with a rank-dependent utility when he is rewarded using a proper
scoring rule tailored to his utility function. I show that such an
agent misreports his true belief by reporting a vector of decision
weights. My findings thus highlight the risk of utilizing proper
scoring rules without prior knowledge about all the components that
drive an agent’s attitude towards uncertainty. On the positive
side, I discuss how tailored proper scoring rules can effectively
elicit weighting functions. Moreover, I show how to obtain an
agent’s true belief from his misreported belief once the weighting
functions are known.
Keywords: proper scoring rules, rank-dependent utility theory, weighting functions.
An agent’s assessment of the likelihood of a future event in which he has no stake may be of interest to others. For example, a financial investor may be interested in the probability a market expert assigns to the increase of a certain stock price. In the medical domain, a patient might want to know the likelihood of success of a treatment before deciding whether to undergo that treatment.
Strategic agents are not necessarily honest when reporting their beliefs. For example, Nakazono [2013] reported that governors of the Federal Open Market Committee tend to report forecasts close to the previous consensus, whereas non-governors tend to report forecasts far away from the previous consensus. Nakazono concluded that both governors and non-governors behave strategically.
In cases where agents behave strategically, a method to promote honest reporting is crucial. Proper scoring rules are traditional scoring methods that induce honest reporting of subjective probabilities, in a sense that an agent maximizes his expected score from a proper scoring rule by reporting his true belief (Winkler and Murphy [1968]). Hence, the implicit assumption behind proper scoring rules is that agents are risk neutral, i.e., that they behave so as to maximize their expected scores.
The assumption of risk-neutral behavior is hardly compelling when the underlying agents are human beings. Several violations of risk neutrality have been reported in the literature (Allais [1953],Holt and Laury [2002],Starmer [2000],Tversky and Kahneman [1992]). Winkler [1969] suggested an approach to tailor a proper scoring rule to an agent’s nonlinear utility function. Under Winkler’s approach, however, agents’ utilities are still weighted by their subjective probabilities.
As I elaborate later in this paper, reporting a belief under a proper scoring rule is equivalent to making a choice under uncertainty. Consequently, one can analyze an agent’s reporting behavior under different decision theories. Modern models of individual choices under uncertainty based on rank-dependent utilities assert that nonlinear utility functions are weighted by decision weights, instead of subjective probabilities (Quiggin [1982],Schmeidler [1989]). Decision weights are differences between weighting functions applied to cumulative probabilities. Thus, according to traditional rank-dependent models, an agent’s attitude towards uncertainty is driven by both a utility function and weighting functions.
In this paper, I investigate how an agent who makes decisions based on a rank-dependent utility reports his belief under a proper scoring rule tailored to his utility function. I show that such an agent misreports his true belief by reporting a vector of decision weights. Decision weights reflect a cognitive bias concerning how human beings deal with probabilities when making choices under uncertainty and, thus, they should not be taken as a measure of an agent’s true belief. Thus, my findings highlight the necessity of knowing all the components that drive an agent’s attitude towards uncertainty before appropriately using a proper scoring rule to elicit that agent’s belief.
On the positive side, I show how a proper scoring rule tailored to an agent’s utility function can effectively elicit that agent’s weighting functions. Moreover, I suggest recursive procedures to obtain the agent’s true belief once his weighting functions are known.
The task of inducing honest reporting of private information has been extensively studied in the fields of mechanism design and decision theory. My focus in this paper is on the elicitation of private information as subjective probabilities (beliefs) over uncertain outcomes.
Proper scoring rules provide a prominent technique to induce honest reporting of subjective probabilities. Proper scoring rules have been used in a variety of domains, e.g., when sharing rewards amongst a set of agents based on peer evaluations (Carvalho and Larson [2010],Carvalho and Larson [2011],Carvalho and Larson [2012]), when incentivizing agents to accurately estimate their own efforts to accomplish a task (Bacon et al. [2012]), to elicit opinions from policy makers regarding the occurrence of political and economic events (Tetlock [2005]), etc.
A standard assumption when using proper scoring rules is that agents are risk neutral. Focusing on the quadratic scoring rule, Winkler and Murphy [1970] investigated the effects of nonlinear utilities on how agents report their beliefs. More precisely, for some specific utility functions, Winkler and Murphy [1970] showed that a risk-seeking agent reports a very sharp probability distribution, whereas a risk-averse agent reports a probability distribution close to the uniform distribution. Winkler [1969] discussed how any proper scoring rule can be adjusted to an agent’s nonlinear utility function, resulting in what I refer to in this paper as tailored proper scoring rules.
The aforementioned works are still within the expected utility theory framework. Modern theories of choice under uncertainty based on rank-dependent utilities assert that, aside from nonlinear utilities, probability sensitivity also plays a role in defining an agent’s attitude towards uncertainty (Quiggin [1982],Schmeidler [1989]). Focusing on binary outcomes, Offerman et al. [2009] discussed how to calibrate a posteriori beliefs reported under the quadratic scoring rule by agents who take decisions based on rank-dependent utilities. Kothiyal et al. [2011] extended the work by Offerman et al. [2009] to all positive proper scoring rules. Moreover, Kothiyal et al. [2011] briefly mentioned that agents with rank-dependent utilities report vectors of decision weights instead of their true beliefs for the specific case when their utility functions are linear.
I generalize the results of Kothiyal et al. [2011] to any proper scoring rule, any finite number of outcomes, and any strictly increasing utility function. More specifically, I show that, when the utility function of an agent who makes decisions based on a rank-dependent utility is known and incorporated into a proper scoring rule, the agent still misreports his belief by reporting a vector of decision weights. Such reporting behavior happens because probability sensitivity, which is defined in terms of weighting functions, plays a crucial role when an agent reports his belief under a proper scoring rule.
I also show how to elicit weighting functions using tailored proper scoring rules. A popular method for eliciting weighting functions was proposed by Abdellaoui [2000]. Abdellaoui’s method implicitly assumes that agents are honest when reporting indifferences between lotteries. My approach, on the other hand, is based on the reports of beliefs for events with known objective probabilities (decision under risk), and honest reporting maximizes an agent’s rank-dependent utility, thus resulting in a more reliable elicitation process.
Consider a set of exhaustive and mutually exclusive outcomes θ1, θ2, …, θn, for n ≥ 2. I assume that agents have beliefs (subjective probabilities) regarding the occurrence of the outcomes. Formally, an agent’s belief is the probability vector p = (p1, …, pn), where pk is his subjective probability regarding the occurrence of outcome θk. Agents are self-interested and, consequently, they are not necessarily honest when reporting their beliefs. Therefore, I distinguish between an agent’s true belief p, and his reported belief q = (q1, …, qn).
Proper scoring rules are traditional devices used to promote honest reporting of subjective probabilities (Winkler and Murphy [1968]). Formally, a scoring rule R(q, θx) is a function that provides a score for the reported belief q upon observing the outcome θx. Scores are somehow coupled with relevant incentives, be they social-psychological, such as praise or visibility, or material rewards through prizes or money. A scoring rule is called proper when an agent maximizes his expected score (according to his own beliefs) by reporting a belief q that corresponds to his true belief p (Winkler and Murphy [1968]). A strictly proper scoring rule means that an agent maximizes his expected score if and only if he reports q = p. The expected score of an agent for a real-valued scoring rule R(q, θx) is:
| Ep | ⎡ ⎣ | R(q, ·) | ⎤ ⎦ | = |
| pk R(q, θk) (1) |
The best known strictly proper scoring rules, together with their scoring ranges, are:
|
For the sake of illustration, consider a coin toss experiment with two outcomes (n=2): θ1 = ‶heads" and θ2 = ‶tails". Consider that an agent i has a true belief p = (0.4, 0.6). Assume that agent i reports the belief q = (q1, q2), which is rewarded according to the logarithmic scoring rule. Then, agent i’s expected score is Ep [ R(q, ·) ] = p1logq1 + p2logq2 = 0.4logq1 + 0.6logq2. In the future, if outcome θ1 is the observed outcome, then the score agent i receives is equal to logq1. Since the logarithmic scoring rule is a strictly proper scoring rule, agent i’s expected score is strictly maximized when he is honest, i.e., when q = p = (0.4, 0.6). To show this, note that Ep [ R(q, ·) ] = p1logq1 + p2logq2 = p1logq1 + (1−p1)log(1−q1). Since the resulting expected score is concave in q1, the value of q1 that maximizes agent i’s expected score can be found by taking the first-order derivative of Ep [ R(q, ·) ] with respect to q1, and equating the result to zero, i.e.:
| − |
| = 0 p1 = q1 |
Selten [1998] and Jose [2009] provided axiomatic characterizations of, respectively, the quadratic scoring rule and the spherical scoring rule in terms of desirable properties, e.g., sensitivity to small probability values, symmetry, etc. In a seminal work, Savage [1971] showed that any differentiable strictly convex function J(q) that is well-behaved at the endpoints of the scoring range can be used to generate a proper scoring rule. Formally:
| R(q, θx) = J(q) − | ⎛ ⎜ ⎜ ⎝ |
|
| × qk | ⎞ ⎟ ⎟ ⎠ | + |
|
For example, the logarithmic scoring rule can be derived from J(q) = ∑k=1n qklogqk:
|
I say that a scoring rule is positive when all the returned scores are nonnegative, i.e., R(q, θx) ≥ 0 for all x ∈ {1, …, n}. The spherical scoring rule is an example of a positive scoring rule. A negative scoring rule, on the other hand, returns only nonpositive scores, i.e., R(q, θx) ≤ 0 for all x ∈ {1, …, n}. The logarithmic scoring rule is an example of a negative scoring rule. Finally, a mixed scoring rule might return both positive and negative scores. The quadratic scoring rule is an example of a mixed scoring rule.
On a side note, I observe that proper scoring rules not only induce honest reporting of subjective probabilities, but they also measure the accuracy of reported beliefs, a task often called forecast verification. In particular, the more an agent moves probability mass to the observed outcome, the higher the agent’s score will be.
An implicit assumption in the definition of proper scoring rules is that agents are risk neutral, i.e., they report their beliefs so as to maximize their expected scores. Since q Ep [ R(q, ·) ] = p, a risk-neutral agent has to honestly report his belief under a proper scoring rule R in order to maximize his expected score. Regarding risk neutrality, Savage [1971] said the following in his seminal work about the theoretical foundations of proper scoring rules:
“This assumption is not altogether unobjectionable; for it may imply that the person’s utility function is linear in money. But such linearity assumptions are made almost throughout the present paper and are presumably tolerable if only moderate sums of money are involved.” (Savage [1971], page 791)
In other words, the function that represents the value that an agent derives from a score, called the utility function, is linear with respect to the range of the score used in conjunction with the scoring rule. Theoretically, an agent’s utility function is approximately linear when the stakes are low (Arrow [1971], page 100). In practice, however, human beings’ utility functions tend to become nonlinear when the stakes are high (Wakker [2010], §2).
Expected utility theory tackles some of the problems concerning risk neutrality by assuming that utility functions might be nonlinear. More specifically, the curvature of the utility function determines an agent’s attitude towards uncertainty, e.g., a convex utility function implies that the agent is risk seeking, whereas a concave utility function indicates that the agent is risk averse. Risk-neutral behavior arises only when the utility function is linear. Naturally, agents are assumed to behave so as to maximize their expected utilities.
In the context of proper scoring rules, an agent who behaves according to expected utility theory reports a belief q so that q = z Ep [ U( R(z, ·)) ], where U(·) is the agent’s utility function. Often in this setting, proper scoring rules are no longer proper, i.e., there are cases where z Ep [ U( R(z, ·)) ] ≠ p (Winkler and Murphy [1970]). Winkler [1969] discussed how the composite function S = U−1 ∘ R is a proper scoring rule under a strictly increasing utility function U. That is, the scoring rule S(q, θx) is tailored to the agent’s utility function. For example, consider the logarithmic scoring rule R(q, θx) = logqx , and a concave utility function U(y) = logy. Then, the tailored proper scoring rule1 is:
| S(q, θx) = U−1 | ⎛ ⎝ | R(q, θx) | ⎞ ⎠ | = elogqx = qx |
Clearly, tailored proper scoring rules subsume traditional proper scoring rules since the latter assume that utility functions are linear. In the following sections, I study the reporting behavior of agents under tailored proper scoring rules. Thus, an implicit assumption in my analysis is that an agent’s utility function is known a priori, for example, it was previously elicited using an approach such as the tradeoff method (Wakker and Deneffe [1996]). However, I make no assumptions on U, except that it is a strictly increasing function, which implies that there exists an inverse function U−1 defined over the range of the utility function U.
When selecting and reporting a probability vector q under a tailored proper scoring rule, an agent is essentially taking a decision under uncertainty, where the potential payoffs resulting from his choice are defined by S(q, θx), for x ∈ {1, …, n}. Consequently, an agent’s reporting behavior can be analyzed from the perspective of different decision theories under uncertainty.
Unarguably, expected utility theory represents a crucial advancement in decision theory under uncertainty. Expected utility theory suggests an elegant and simple way of combining subjective probabilities and payoffs into a single measure of value, which has a number of appealing theoretical properties. However, several violations of the premises of expected utility theory have been widely reported. Many of these violations, such as the common consequence effect and the common ratio effect, can be explained by models that take subjective attitudes to probability into account, such as rank-dependent models (Quiggin [1982],Schmeidler [1989]).
Rank-dependent models assert that both sensitivity to payoffs and sensitivity to probabilities generate deviations from risk neutrality. In particular, these models convert subjective probabilities into decision weights, and agents are assumed to take decisions so as to maximize their rank-dependent utilities (RDU). A possible interpretation of decision weights is that they represent a cognitive bias concerning how human beings deal with probability values when making choices under risk and uncertainty.
Rank-dependent models are amongst the most satisfactory decision theories under uncertainty (but, as discussed later, other models may be better still). Starmer [2000] and Camerer [2004] documented the superior predictive performance of rank-dependent models over expected utility theory for a range of phenomena, including the disposition effect, the equity premium puzzle, asymmetric price elasticities, the excess sensitivity of consumption to income, elasticities of labour supply and asset pricing, etc.
By construction, rank-dependent models can explain everything that expected utility theory can, but the converse is false. Under expected utility theory, an agent reports his true belief under a tailored proper scoring rule. In the next sections, I show that this is no longer the case under a rank-dependent model. In order to build intuition, I first introduce RDU in terms of lotteries, which are event-contingent payoffs. Thereafter, I extend the initial definition of RDU to tailored proper scoring rules and characterize how an underlying agent reports his belief.
Let l = [y1∶θ1, …, yn∶θn] denote a lottery which yields a payoff of yx ∈ ℜ if outcome θx occurs. Since one can always rearrange the outcomes, I assume without loss of generality that yn ≥ yn−1 ≥ … ≥ y1. Given that agents have beliefs over the occurrence of the outcomes, I can then represent a lottery as l = [y1∶ p1, …, yn∶ pn], which yields a payoff of yx ∈ ℜ with probability px.
A lottery is called positive when all payoffs are nonnegative, i.e., yn ≥ yn−1 ≥ … ≥ y1 ≥ 0. I denote a positive lottery by l+. A lottery is called negative when all payoffs are nonpositive, i.e., 0 ≥ yn ≥ yn−1 ≥ … ≥ y1. I denote a negative lottery by l−. Finally, a mixed lottery l± contains both positive and negative payoffs, i.e., yn ≥ yn−1 ≥ … ≥ yi ≥ 0 ≥ yi−1 ≥ … ≥ y1.
Focusing first on positive lotteries, rank-dependent models state that the value that a human being assigns to l+ is described according to his rank-dependent utility (RDU) (Quiggin [1982]):
| RDU | ⎛ ⎝ | l+ | ⎞ ⎠ | = |
| πk+ U(yk) (2) |
where:
| (3) |
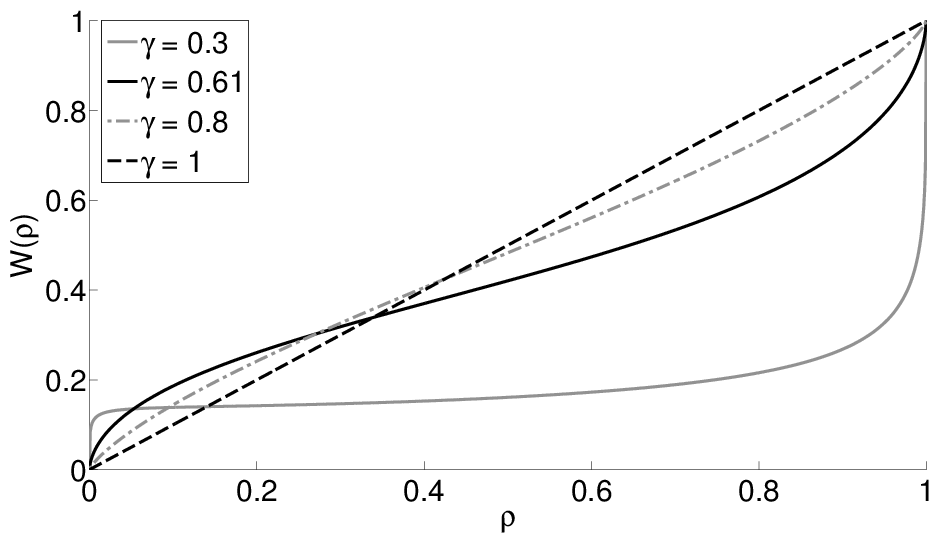
for k ∈ {1, …, n−1}. The function W+∶[0, 1] → [0,1], also known as the weighting function, is striclty increasing, and it satisfies W+(0) = 0 and W+(1) = 1. Henceforth, I drop the superscript whenever talking about weighting functions in general, and not only in the domain of gains. As suggested by Gonzalez and Wu [1999], the weighting functions model the “psychophysics of chance”, i.e., the way human beings subjectively distort probability values. Common findings suggest that the weighting function is a nonlinear transformation of the probability scale that overweights small probabilities and underweights moderate and high probabilities (Tversky and Kahneman [1992],Abdellaoui [2000]). In other words, the weighting function displays an inverse-S shape: it is concave near 0 and convex near 1. The weighting function proposed by Tversky and Kahneman [1992] is:
| W(ρ) = |
| (4) |
where γ ≥ 0.28 in order for W to be strictly increasing. For γ = 1, the weighting function in (4) becomes the identity function. Decreasing γ results in a more pronounced inverse-S shape. Figure 1 illustrates the weighting function in (4) for different values of γ.
There are two crucial points regarding the rank-dependent utility in (2). First, as in the expected utility theory, the value that an agent derives from a payoff in a lottery is given by a strictly increasing utility function U∶ℜ→ ℜ. Second, instead of an individual probability value pk as in the expected utility theory, the weight of a utility U(yk) in (2) is the difference between two transformed ranks, W(pk+…+pn)− W(pk+1+…+pn), also called a decision weight. For a lottery l+, the rank of a payoff yk is the probability of l+ yielding a payoff better than yk, i.e., the rank of yk is equal to pk+1+pk+2+…+ pn. The weight of U(yk) is then the transformed marginal contribution of the individual probability pk to the total probability of receiving payoffs better than yk.
Under rank-dependent models, positive and negative lotteries might be evaluated differently. For a negative lottery l−, the rank-depend utility in (2) is now defined as:
| RDU | ⎛ ⎝ | l− | ⎞ ⎠ | = |
| πk− U(yk) |
where:
| (5) |
for k ∈{2, …, n}. While a decision weight πk+ denotes the marginal contribution of an individual probability value pk to the total probability of receiving better payoffs, a decision weight πk− denotes the marginal contribution of an individual probability value pk to the total probability of receiving worse payoffs, measured in terms of a weighting function W−∶[0, 1] → [0,1].
Finally, for a mixed lottery l±, where yn ≥ yn−1 ≥ … ≥ yi ≥ 0 ≥ yi−1 ≥ … ≥ y1, the rank-depend utility is now defined as:
| RDU | ⎛ ⎝ | l± | ⎞ ⎠ | = |
| πk− U(yk) + |
| πk+U(yk) |
Without loss of generality due to a possible rearrangement of outcomes, assume that the scores from a tailored proper scoring rule S are ordered, i.e., S(q, θn) ≥ S(q, θn−1) ≥ … ≥ S(q, θ1). I note that the scores from a tailored proper scoring rule can be stated in terms of a lottery: [S(q, θ1)∶ p1, …, S(q, θn)∶ pn]. Consequently, when reporting a belief q, an agent is essentially defining the payoffs of a lottery, where the associated probabilities are subjective probabilities. In other words, reporting a belief q is equivalent to choosing a lottery amongst a potentially infinite number of lotteries. This implies that an agent’s reporting behavior can be analyzed from the perspective of decision models such as rank-dependent models. For a positive, tailored proper scoring rule S(q, θx), the rank-dependent utility in (2) becomes:
| πk+ U | ⎛ ⎝ | S | ⎛ ⎝ | q, θk | ⎞ ⎠ | ⎞ ⎠ | (6) |
Similarly, the RDU for a negative, tailored proper scoring rule S(q, θx) is:
| πk− U | ⎛ ⎝ | S | ⎛ ⎝ | q, θk | ⎞ ⎠ | ⎞ ⎠ | (7) |
Finally, the RDU for a mixed, tailored proper scoring rule S(q, θx) is:
| πk− U | ⎛ ⎝ | S(q, θk) | ⎞ ⎠ | + |
| πk+ U | ⎛ ⎝ | S(q, θk) | ⎞ ⎠ | (8) |
From the above equations, one might expect that an agent who maximizes a rank-dependent utility will behave differently than an expected-utility maximizer and, consequently, will report a belief other than his true belief under a tailored proper scoring rule. I discuss this point in the following section.
The following propositions characterize how an agent who behaves to maximize a rank-dependent utility reports his belief under a tailored proper scoring rule. In short, my results indicate that such an agent reports a vector of decision weights, instead of his true belief.
Proof. I start by noting that U(S(q,θx)) = U(U−1(R(q,θx))) = R(q,θx), for some proper scoring rule R. If π+ = (π1+, π2+, …, πn+) is a probability vector, then ∑k=1n πk+ R(q,θk) = Eπ+ [ R(q, ·) ], as in equation (1), and, consequently, q ∑k=1n πk+ R(q,θk) = π+. Thus, I just need to prove that π+ = (π1+, …, πn+) is indeed a probability vector. From (3), I deduce that ∑k=1n πk+ = W+(∑k=1n pk) = 1. Since W+ is a strictly increasing function and its image is equal to [0, 1], then 0 ≤ πk+ ≤ 1, for all k ∈ {1, …, n}, thus completing the proof.
A similar result holds for negative, tailored proper scoring rules, as shown in Proposition 2.
Proof. Given that U(S(q,θx)) = R(q,θx), for some proper scoring rule R, if π− = (π1−, π2−, …, πn−) is a probability vector, then ∑k=1n πk− R(q,θk) = Eπ− [ R(q, ·) ], as in equation (1). Consequently, q ∑k=1n πk− R(q,θk) = π−. Thus, I just need to prove that π− = (π1−, …, πn−) is indeed a probability vector. From (5), I deduce that ∑k=1n πk− = W−(∑k=1n pk) = 1. Since W− is a strictly increasing function and its image is equal to [0, 1], then 0 ≤ πk− ≤ 1, for all k ∈ {1, …, n}, thus completing the proof.
Propositions 1 and 2 imply that positive and negative tailored proper scoring rules induce different reporting behavior whenever the weighting functions W+ and W− are different. In other words, a simple positive affine transformation of a proper scoring rule might induce different reporting behavior. I illustrate this point in Section 5.1. I show in the following proposition that mixed, tailored proper scoring rules induce agents to report decision weights as well when W+(ρ) + W−(1−ρ) = 1, for all ρ ∈ [0, 1].
Proof. If π±= (π1−, …, πi−1−, πi+, …, πn+) is a probability vector, then the result follows naturally because U(S(q,θx)) = R(q,θx), for some proper scoring rule R. Consequently, I just need to prove that π± is indeed a probability vector. From (3) and (5), I have that ∑k=1i−1 πk− + ∑k=in πk+ = W−(∑k=1i−1 pk) + W+(∑k=in pk) = 1, where the last equality follows from the assumption that W+(ρ) + W−(1−ρ) = 1 , for all ρ ∈ [0, 1]. Since both W+ and W− are strictly increasing functions and their images are equal to [0, 1], then 0 ≤ πj−, πk+ ≤ 1, for all j ∈ {1, …, i−1} and k ∈ {i, …, n}, thus completing the proof.
In this subsection, I illustrate the theoretical results proved in Propositions 1 and 2 by using the weighting function proposed by Tversky and Kahneman [1992] shown in (4). Tversky and Kahneman [1992] found that the best fit for their data happened when using W+ and W− as defined in (4) with parameter values equal to, respectively, γ = 0.61 and γ = 0.69.
Consider an agent with belief p = (0.2, 0.8) who behaves so as to maximize his rank-dependent utility. Under a positive, tailored proper scoring rule, Proposition 1 implies that the agent reports:
| q = (1 − W+(0.8), W+(0.8)) = (0.393, 0.607) |
Proposition 2 implies that the same agent reports:
| q = (W−(0.2), 1−W−(0.2)) = (0.257, 0.743) |
under a negative, tailored proper scoring rule. The deviation of the agent’s reported belief q from his true belief p according to the mean absolute error is equal to: 0.5×|1 − W+(0.8) − 0.2| + 0.5×|W+(0.8) − 0.8| = 0.193, for a positive, tailored proper scoring rule, and 0.5×|W−(0.2) − 0.2| + 0.5×|1−W−(0.2) − 0.8| = 0.057 for a negative, tailored proper scoring rule.
The above example illustrates that positive and negative tailored proper scoring rules might induce different reporting behavior whenever the weighting functions W+ and W− are not equal to each other. In particular, tailored proper scoring rules with positive scores seems to result in stronger deviations from honest reporting and, consequently, risk neutrality than with negative scores, a fact that is empirically plausible (Wakker [2010], page 264). Furthermore, the above example illustrates that agents overweight low probabilities by reporting probability values greater than their true beliefs, and they underweight high probabilities by reporting probability values less than their true beliefs.
The results from the previous section are negative in nature because they mean that RDU agents report biased beliefs under tailored proper scoring rules. On the positive side, I discuss in this section how tailored proper scoring rules can elicit weighting functions in a parameter-free manner.
My approach assumes that there are two exhaustive and mutually exclusive outcomes, σ1 and σ2, with known, objective probability values φ and 1 − φ. For example, σ1 and σ2 can be the outcomes “heads” and “tails” in an experiment where a biased coin with known Bernoulli distribution is tossed. An agent is then asked to report his belief µ = (µ, 1 − µ), for µ ∈ [0, 1].
Consider a proper scoring rule R(µ, σx), for x ∈ {1, 2}, defined as follows:
|
where R′ is a bounded proper scoring rule, i.e., a proper scoring rule where all the returned scores are real numbers, sgn is the sign function, and m is the maximum score returned by R′. Then, by construction, R(µ, σ2) ≥ R(µ, σ1) for any µ, which means that R is comonotonic (Kothiyal et al. [2011]). I now construct a tailored proper scoring rule to elicit µ, i.e., S(µ, σx) = U−1(R(µ, σx)). Since U−1 is strictly increasing, I then obtain S(µ, σ2) ≥ S(µ, σ1) for any µ, which implies that S also satisfies comonotonicity.
In previous sections, for ease of exposition and mathematical notation, I assumed that S(q, θn) ≥ S(q, θn−1) ≥ … ≥ S(q, θ1). I claimed that such an assumption is without loss of generality because the outcomes could always be rearranged a posteriori. In this section, however, I do not allow the outcomes to be rearranged and, by construction, S(µ, σ2) ≥ S(µ, σ1) for any belief µ. For example, in the aforementioned coin experiment, one agent will always receive higher scores if outcome σ2 = “tails” occurs than if outcome σ1 = “heads” occurs, no matter what the agent reports.
First, consider the case where the resulting tailored proper scoring rule S is negative, i.e., 0 ≥ S(µ, σ2) ≥ S(µ, σ1). Proposition 2 implies that an agent who maximizes a rank-dependent utility reports the probability vector µ = (π1−, π2−) = (W−(φ), 1 − W−(φ)). In other words, I obtain the value of W− for the objective probability value φ. For a sufficiently dense set of objective probabilities, e.g., taking all values in the set {0, 0.05, 0.1, …, 0.95, 1 }, I obtain a parameter-free estimate of the weighting function W−.
Alternatively, if S is a positive tailored proper scoring rule, Proposition 1 says that an agent who maximizes a rank-dependent utility reports the probability vector µ = (π1+, π2+) = (1 − W+(1−φ), W+(1−φ)). Then, for a sufficiently dense set of objective probabilities, I obtain a parameter-free estimate of the weighting function W+.
Finally, if S is a mixed tailored proper scoring rule, Proposition 3 says that an agent who behaves so as to maximize a rank-dependent utility reports the probability vector µ = (π1−, π2+) = (W−(φ), W+(1−φ)), under the assumption that W−(φ) + W+(1−φ) =1. Then, for a sufficiently dense set of objective probabilities, I obtain a parameter-free estimate of both the weighting function W− and the weighting function W+.
It is noteworthy that without the comonotonicity property, π1− is always less than or equal to 0.5, and π2+ is always greater than or equal to 0.5 (Kothiyal et al. [2011]). Consequently, the weighting function W− could not be estimated for probability values greater than 0.5, whereas the weighting function W+ could not be estimated for probability values less than 0.5.
On a final note, I observe that traditional methods for eliciting weighting functions assume that agents report indifferences between lotteries honestly (Abdellaoui [2000]). Under my approach, on the other hand, it is in the best interest of an agent to report µ honestly since this maximizes his rank-dependent utility.
In Section 5, I showed how tailored proper scoring rules elicit vectors of decision weights from agents who behave so as to maximize a rank-dependent utility. In Section 6, I discussed how to use tailored proper scoring rules to elicit an agent’s weighting functions. A natural question that then arises regards how to combine these two results in order to obtain an agent’s true belief p when that agent reports a vector of decision weights. In the following subsections, I show how an agent’s true belief can be obtained by using simple recursive procedures. The proposed procedures are sound as long as S(q, θn) > S(q, θn−1) > … > S(q, θ1), i.e., when there are only inequalities in the scores from the tailored proper scoring rule. Otherwise, the underlying proper scoring rule might have to satisfy comonotonicity (Kothiyal et al. [2011]).
If a positive, tailored proper scoring rule is used in the elicitation process, then Proposition 1 says that the belief q = (q1, …, qn) = (π1+, …, πn+) is reported by a rank-dependent utility maximizer, which implies that:
|
Once W+ is known, the above system of equations can be solved by using backward substitution, i.e., by first computing pn, then substituting that into the next equation to find pn−1, and so on. Starting with the base case pn, I have pn = W+−1(qn). For pn−1, I have pn−1 = W+−1(qn−1 + qn) − pn. More generally, for all k ∈ {2, …, n−1}, I obtain pk by solving the equation pk = W+−1(∑x=kn qx) − ∑x=k+1n px. Finally, p1 = 1− ∑x=2n px.
If a negative, tailored proper scoring rule is used in the elicitation process, then Proposition 2 says that the belief q = (q1, …, qn) = (π1−, …, πn−) is reported by a rank-dependent utility maximizer, which implies that:
|
Once W− is known, the above system of equations can be solved by using forward substitution, i.e., by first computing p1, then substituting that into the next equation to find p2, and so on. Starting with the base case p1, I have p1 = W−−1(q1). For p2, I have p2 = W−−1(q1 + q2) − p1. More generally, for all k ∈ {2, …, n−1}, I obtain pk by solving the equation pk = W−−1(∑x=1k qx) − ∑x=1k−1 px. Finally, pn = 1− ∑x=1n−1 px.
Finally, if a mixed, tailored proper scoring rule is used in the elicitation process, then Proposition 3 says that the belief q = (q1, …, qn) = (π1−, …, πi−1−, πi+, …, πn+) is reported under the assumption that W+(ρ) + W−(1−ρ) = 1, for all ρ ∈ [0, 1], which implies that:
|
Once the weighting functions W+ and W− are known, the above system of equations can be solved by using forward and backward substitution, i.e., forward substitution can be used to obtain the values of p1, …, pi−1 as discussed in Section 7.2, whereas backward substitution can be used to obtain the values of pi, …, pn as discussed in Section 7.1.
Proper scoring rules are traditional devices to elicit beliefs over uncertain outcomes. As discussed in this paper, reporting a belief under a proper scoring rule is equivalent to making a decision under uncertainty. An implicit assumption when eliciting beliefs using proper scoring rules is that the underlying agents are risk neutral. Such an assumption is hardly compelling when the agents are human beings. Winkler [1969] suggested how to adapt proper scoring rules to expected utility theory by tailoring the proper scoring rule to an agent’s nonlinear utility function. Currently, there is overwhelming evidence that rank-dependent models are more accurate when describing and predicting human beings’ decisions under uncertainty than expected utility theory. In this paper, I characterized how an agent who maximizes a rank-dependent utility reports his belief under a tailored proper scoring rule. In particular, I found that such an agent misreports his true belief by reporting a vector of decision weights.
Decision weights can be seen as a cognitive bias concerning how human beings deal with probabilities and, thus, they should not be taken as a measure of an agent’s true belief. Hence, my findings highlight the necessity of knowing all the components that drive an agent’s attitude towards uncertainty before appropriately using a proper scoring rule to elicit that agent’s belief.
On the positive side, I showed how to elicit weighting functions using tailored proper scoring rules, and how to obtain an agent’s true belief from his misreported belief once his weighting functions are known. My work thus provides guidelines for appropriately using proper scoring rules under the empirically plausible assumption that agents behave so as to maximize rank-dependent utilities. The first step consists of eliciting the agent’s utility function, e.g., by using the tradeoff method proposed by Wakker and Deneffe [1996]. In the second step, the agent’s utility function is incorporated into a proper scoring rule, and the resulting tailored proper scoring rule is used to elicit the agent’s belief. In the third step, the agent’s weighting functions are elicited using tailored proper scoring rules, as described in Section 6. Finally, the agent’s true belief is obtained a posteriori from his misreported belief, as described in Section 7. This approach is rather general in a sense that it works for any strictly increasing utility function, any finite number of outcomes, and any proper scoring rule as long as the potential scores given a reported belief are all different from each other.
It is interesting to note that the analysis performed in this paper can be extended to other non-expected utility theories. For example, consider the rank-affected multiplicative weights (RAM) model by Birnbaum [1997],Birnbaum [2008]. For two outcomes, θ1 and θ2, and a positive, tailored proper scoring rule S(q, θx), where the outcomes are ordered such that S(q, θ2) ≥ S(q, θ1), the RAM model is:
| + |
| (9) |
Intuitively, the RAM model means that the value an agent assigns to a lottery is equal to a weighted average in which the weight associated with a payoff is a function of the probability associated with the underlying outcome and the rank of the payoff relative to other payoffs. Instead of his true belief p = (p1, p2), an agent who behaves so as to maximize the above function ends up reporting the following belief:
| q = | ⎛ ⎜ ⎜ ⎝ |
| , |
| ⎞ ⎟ ⎟ ⎠ |
For example, consider the true belief p = (0.2, 0.8) used in the numerical example in Section 5.1. Moreover, assume the parameter value γ = 0.7 in (9). In this setting, in order to maximize (9), an agent reports q = (0.431, 0.569). Note that the reported belief is different than (0.393, 0.607) and (0.257, 0.743), the beliefs reported under RDU for, respectively, a positive and a negative tailored proper scoring rules (see Section 5.1).
As can be seen from the above example, different decision theories might imply different reporting behavior under proper scoring rules. Consequently, the procedure to obtain an agent’s true belief from his reported belief is also dependent on the underlying decision theory. These points raise an important question: which decision theory is the “correct” theory when eliciting beliefs using proper scoring rules? Identifying the “best theory” naturally requires judgments about the relative importance of predictive accuracy, simplicity, tractability, theoretical properties, etc. Such judgments are often subjective in their nature. For example, one might argue that rank-dependent models have stronger axiomatic foundations in terms of preferences than the RAM model. Alternatively, the RAM model accounts for behavior that many rank-dependent models violate, such as coalescing and violations of stochastic dominance (Birnbaum [2008]).
Another example of such a trade-off concerns the Transfer of Attention Exchange (TAX) model by Birnbaum [1997]. Birnbaum [2008] documented the superior predictive performance of the TAX model over some rank-dependent models as well as the RAM model. The TAX model represents the utility of a lottery as a weighted average of the utilities of payoffs, where the weights depend on both the probabilities of the outcomes and the ranks of the payoffs. Unlike weights in rank-dependent models, those weights represent transfers of attention from branch to branch. In practice, this implies that the utility of each payoff is weighted by a nonlinear transformation of a subjective probability as well as “weight transfer” factors. Such factors make the problem of adapting proper scoring rules to the general TAX model quite challenging, a task that I have not been able to accomplish yet.
If one decides that predictive accuracy is the most relevant
criterion, then a whole new set of experiments might be required to
determine the most appropriate decision theory when using proper
scoring rules. As discussed in Section 4.2, the payoffs
of lotteries are defined by an agent’s reported belief when using
proper scoring rules. Consequently, agents have some control over
their payoffs. In practice, this fact might have some influence on the
way agents choose amongst different lotteries.
This file was generated by
bibtex2html 1.98.References
This document was translated from LATEX by HEVEA.