Whether it pertains to the foods to buy when one is on a diet, the
items to take along to the beach on one’s day off or (perish the
thought) the belongings to save from one’s burning house, choice is
ubiquitous. We aim to determine from choices the criteria
individuals use when they select objects from among a set of
candidates. In order to do so we employ a mixture IRT (item-response
theory) model that capitalizes on the insights that objects are
chosen more often the better they meet the choice criteria and that
the use of different criteria is reflected in inter-individual
selection differences. The model is found to account for the
inter-individual selection differences for 10 ad hoc and goal-derived
categories. Its parameters can be related to selection criteria that
are frequently thought of in the context of these categories. These
results suggest that mixture IRT models allow one to infer from mere
choice behavior the criteria individuals used to select/discard
objects. Potential applications of mixture IRT models in other
judgment and decision making contexts are discussed.
On his website http://theburninghouse.com designer Foster
Huntington invites people to post a picture of the things they would
save from their house if it were to be on fire. About the project he
writes: “If your house was burning, what would you take with
you? It’s a conflict between what’s practical, valuable and
sentimental. What you would take reflects your interests, background
and priorities. Think of it as an interview condensed into one
question.” His introduction captures a number of intuitions about
how one would select objects to save from a fire: (i) Multiple
considerations will probably go into the decision. (ii) There are
likely to be important differences between individuals in the objects
they select. (iii) The selection of objects might reveal information
about an individual that is otherwise hard to obtain.
The pictures that respondents provide on the website appear to support
the above intuitions. An individual’s picture generally contains a set
of diverse objects, some of which are functional and some of which are
emotionally or financially valuable. Pictures by different individuals
contain different numbers of functional versus valuable objects and
tend to differ in the specific instantiations of valued objects. It is
certainly the case that the pictures provide a peek into the life of
the respondents, highlighting those objects they value the most. But
what can we infer from a specific set of objects about the
considerations that went into their selection? Do these choices of
material items convey anything about the purposes and desires of
individuals who face the loss of their furnishings? And are
individuals really as different as their seemingly idiosyncratic
choices might lead us to suspect, or do they reflect more general
inclinations that are shared by many?
These are the kinds of questions we would like to answer in this
paper. They pertain to the possibility of inferring latent criteria
from overt selection decisions and the nature of the inter-individual
selection differences. In what follows we will first introduce the
terminology that we will use in treating these questions. Then, we
will introduce the formal framework that will allow us to answer the
above questions. When finally we apply the framework to empirically
obtained selection data, the intuitions that Foster Huntington
formulated for the category of things you rescue from a
burning house will be shown to hold for many other categories as
well. We conclude the paper by discussing how the formal framework may
be employed to answer substantial questions in the judgment and
decision making literature.
2 Terminology
If one abstracts away from the unusual premise that a burning house is
involved, the above questions can be recognized as recurring ones in
the many disciplines of cognitive science that study human
judgments. They pertain to individual differences in the criteria that
are used, the number of criteria that are used, the order in which
they are considered, the weights that are attached to them, and the
manner a judgment is derived from them
(Juslin et al. [2003], Pachur and Bröder [2013], Van Ravenzwaaij et al. [2014]). What
differs between disciplines are the names for the criteria
(attributes, cues, dimensions, features, …) and the judgments
(categorization, choice, decision, induction, inference, selection,
…) that are employed. One example is categorization, where
individuals may rely on different apparent dimensions to
arrive at an externally defined correct classification
(Bartlema et al. [2014]) or abstract features
from their environment to arrive at a conventional classification
(Verheyen and Storms [2013]). Multi-attribute decision making is another
example. Depending on whether individuals rely upon objectifiable or
more subjective attributes, the problem of determining the criteria
individuals employ goes under the name probabilistic
inference or preferential choice
(Pachur and Bröder [2013], Söllner et al. [2014], Weber and Johnson [2009]).
In some disciplines the use of criteria is not the main topic of
interest, but considered to be merely indicative of that what
individuals strive for. Depending on the discipline these intended end
states are referred to as desires, goals, interests, or purposes
(Austin and Vancouver [1996], Graff [2000]). A case in point are so-called ad
hoc categories like things you rescue from a burning
house. Ad hoc categories are constructed on the fly to serve a
specific goal such as the minimization of financial loss or the
preservation of precious souvenirs (Barsalou [1985]). Selection is
important to attain a goal (Barsalou [1991], Barsalou [2003]). One needs
to identify those objects that are most instrumental to attain the
goal (Austin and Vancouver [1996], Förster et al. [2005]). In
the case of an individual whose house is on fire and is willing to
risk his life to minimize financial loss, this amounts to identifying
and carrying out the objects that are highest in monetary value in the
limited time s/he has available. Since this favors the selection of
objects with an extreme value on the relevant criterion, the criterion
is sometimes called an ideal
(Barsalou [1985], Lynch et al. [2000]). The extent to which an
object meets the choice criterion determines its idealness and
corresponding likelihood of being included in the category.
Regardless of whether the choice criteria are being retrieved from
memory, identified in the environment, or a combination of both
(Bröder and Schiffer [2003], Gigerenzer and Todd [1999]), the question of how to
confine the set of potential criteria pervades all described domains
(Glöckner and Betsch [2011], Marewski and Schooler [2011], Scheibehenne et al. [2013], Verheyen and Storms [2013]).
The question is perhaps most pressing for theories that adopt
constructs such as goals and would like to determine the particular
goals that drive individuals
(Austin and Vancouver [1996], Ford and Nichols [1987], Kuncel and Kuncel [1995]). By
definition goals are internally represented, private constructs that
one need not necessarily be able to verbalize or even consciously
experience. As a result, most of the research involves artificial
laboratory tasks with a limited number of salient criteria. This is
true both for categorization (Smits et al. [2002]) and
for multi-attribute decision making
(Lipshitz [2000]). Similarly, the research into goals has been
focusing on a limited set of specific goals
(Deci and Ryan [1985], Ryan [1992]). The modus operandi in the field has been
to look into goals that are salient in natural settings (e.g.,
Medin et al. [1996], Ratneshwar et al. [2001], Simon [1994])
or to experimentally induce them in laboratory settings (e.g.,
Förster et al. [2005], Jee and Wiley [2007], Locke and Latham [1990])
and to investigate whether individuals’ selection decisions differ as
a result of the known differences in goals.
Contrary to these customs, our approach will allow the criteria to be
uncovered from the selection decisions. We introduce a formal
framework that relates the overt decisions to latent constructs that
allow one to infer what considerations underlay the selection
decisions. This is established by positioning the candidate objects
along a dimension according to their likelihood of being
selected. Assuming that the objects that are chosen foremost are the
ones that best meet the choice criteria, it is only a matter of
interpreting the dimension to determine the considerations that went
into the selection decisions. If the choices were to pertain to an ad
hoc category such as things you rescue from a burning house
and the objects that are listed according to frequency of selection
were to follow the objects’ monetary value, it is likely that monetary
value was the ideal and minimization of financial loss was the goal
underlying the selection decisions.
The ability to organize objects according to the likelihood of
selection presumes individual differences in selection. If
everyone were to select the same objects, this would be an impossible
endeavour. We hypothesize that these individual differences come in
two kinds: differences in the criteria for selection and differences
in the standards that are imposed on these criteria. Both types of
individual differences are incorporated in so-called mixture IRT
(item-response theory) models
(Mislevy and Verhelst [1990], Rost [1990], Verheyen and Storms [2013]), a class of
models from the psychometric literature that are generally used to
identify differences among individuals in how they solve tests, both
with respect to strategy and ability. Before we turn to a discussion
of how we intend to use mixture IRT models to infer choice criteria,
we elaborate on the inter-individual selection differences we
presume. Since the empirical demonstration we offer will involve ad
hoc categories and goal-derived categories (i.e., ad hoc categories
that have become well-established in memory, for instance, through
frequent use; Barsalou [1985]), we will frame both the
discussion of these individual differences and the models in terms of
goals and ideals. The models can, however, just as well be applied to
situations in which one is interested in mere individual differences
in objective choice criteria, without reference to more remote
constructs.
3 Inter-individual selection differences
When it comes to satisfying a goal, it is important to acknowledge
that not all means are equivalent. If one’s goal is to minimize the
financial losses due to a fire, one is better off saving the
television from the flames than a stuffed animal. However, if one is
more intent on rescuing valuable souvenirs, a treasured stuffed animal
will be the better choice. Objects differ in their ability to fulfill
a particular goal (Barsalou [1991], Garbarino and Johnson [2001]) and people
are sensitive to these differences (Barsalou [1985]). In light of
these differences, selection serves an important function
(Barsalou [1991], Barsalou [2003]).
The example of things you rescue from a burning house allows
for the easy identification of two sources of individual
differences in the decision to include an object in the category or
not. First, individuals can have different goals when confronted with
their burning house. Some may want to minimize financial loss, while
others may want to preserve as many souvenirs as possible. Depending
on one’s goal, the properties that are desirable for objects to be
included will differ. Individuals intent on minimizing financial loss
will want to save objects of high financial value, while individuals
intent on preserving as many souvenirs as possible will want to save
objects of high emotional significance. These ideals determine the
relative likelihood with which objects will be selected. The
likelihood of selection increases with idealness. Among individuals
who want to preserve souvenirs, the likelihood of rescue will increase
with the emotional value of the object. The same objects will have a
different likelihood of being selected by individuals who want to
minimize financial loss. Among these individuals the likelihood of
rescue will increase with the financial value of the object.
Second, individuals that have a similar goal may impose different
standards for including objects in their selection
(Barsalou [1985], Barsalou [1991], Graff [2000]). While two individuals may
both be intent on minimizing the financial losses due to the fire, the
first may require objects to be at least $500 to risk her life for,
while the other may require them to be at least $1,000. Whether an
object will actually be included in the category things you
rescue from a burning house will thus also depend on the cut-off
for inclusion an individual imposes on the ideal. Put differently,
individuals may agree on how a particular property makes one object
more suitable to be included than another, but still differ in opinion
about the extent to which objects have to display the property to
actually be included. The higher the standard one imposes, the fewer
the objects that will be included.
4 The formal framework
To introduce the formal framework let us start off with a hypothetical
problem. Imagine that we present a group of people with a collection
of objects that are commonly found in houses and ask them to indicate
which of these objects they would save from their own house if it were
to be on fire. For every individual-object-combination we would then
obtain a decision Yio, either taking value 1 when individual
i decides that object o would be saved or taking
value 0 when i decides that o would not be
saved. Let us further assume that we know (i) all respondents to share
the same goal and (ii) any individual differences in selection
to be due to the use of different standards. Having only the selection
decisions Yio at one’s disposal, how could one identify the
contents of the goal that underlies all respondents’ decisions?
A straightforward manner to accomplish this would be to determine for
every object the proportion of individuals from the group who decided
to save it. Since we assumed our hypothetical individuals not to pick
out the same objects, but to select different numbers because of
differences in the standard they impose on the properties relevant to
their goal, objects are likely to differ considerably in selection
proportion. The proportion for every object can then be identified
with its idealness, provided the assumption holds that the objects
that are chosen foremost are the ones best able to satisfy the goal.
Arranging the objects according to the proportion of selection yields
a dimension of variation (i.e., the presumed ideal). Determining the
contents of this ideal involves the interpretation of the dimension.
It is clear in this hypothetical example that individuals’ response
patterns are informative. Notably, the responses of any individual
would follow a Guttman structure if they were listed in the order of
the objects’ frequency of selection (across individuals). A Guttman
structure with n entries consists of a series of k
zeros (not selected), followed by a series of n-k ones
(selected, e.g., {0,0,0,…,1,1}). The order of objects is
invariant across individuals, but the value of k may differ
between individuals (e.g., patterns {0,0,1,…,1,1} and
{0,1,1,…,1,1} would indicate that the first respondent
imposes a higher standard than the second respondent does). Such
patterns suggest that all individuals employ a common ideal to decide
whether to select an object or not, with a higher probability of being
selected, the higher an object’s idealness.
Real response patterns, however, rarely conform to this ideal scenario
(pun intended). As we already indicated in the introduction,
respondents do not necessarily share a common goal. Whenever goals
have been elicited with respect to a particular domain, several goals
usually exist, and their contents may be quite diverse
(Borkenau [1991], Loken and Ward [1990], Voorspoels et al. [2013]). One
would expect that individuals with different goals display different
selection behavior, as the objects that are considered ideal for one
goal are not necessarily those that are considered ideal for other
goals. Candidate objects would therefore have a different likelihood
of being selected depending on the goal of the individual who is
responsible for the selection. Our approach will therefore attempt to
identify a number of latent groups g among the individuals,
with the understanding that individuals within a group display
consistent selection behavior (i.e., share a similar goal) that is
different from the selection behavior of other groups (i.e., they have
different goals). That is, arranging the candidate objects according
to selection proportions is likely to yield a different order and
interpretation in different groups.
The purpose of the modeling exercise is to explain the systematicity
in the selection differences. Idiosyncratic response patterns are in
all likelihood not informative for our purpose. If one were to
accommodate any minor deviation with a new group with separate Guttman
pattern, this would likely result in an infeasible, uninformative
number of groups. We therefore argue for a probabilistic approach in
which it suffices that individuals’ response patterns tend
toward a Guttman pattern. It comes in the form of a mixture IRT
model (Mislevy and Verhelst [1990], Rost [1990]) that considers every
selection decision the outcome of a Bernoulli trial with the
probability of a positive decision derived as follows:
Pr(Yio=1)=
e αg(βgo−θi)
1+e αg(βgo−θi)
.
(1)
The model in Equation (1) uses the information that is
contained in the individuals’ response patterns to organize both
individuals and objects along a latent dimension, much like the
procedure that was outlined for our hypothetical example organized
objects along a (latent) dimension of variation. The main divergence
from the solution to the hypothetical problem is that the current
model allows for multiple dimensions of variation, one for each
subgroup of respondents the model infers from the data. We will take
these dimensions to represent the ideals that serve the respondents’
goals. For each group g of individuals the model organizes
the candidate objects along a dimension according to their likelihood
of being selected by that group. βgo indicates the position
of object o along the dimension for group g. Higher
values for βgo indicate objects that are more likely to be
selected. It is assumed that individuals in a group share the same
goal, and that the organization of the objects can thus be conceived
of as reflecting their idealness with respect to the goal. The better
an object is at satisfying the goal, the more likely it is to be
selected and consequently the higher its βgo estimate.
Groups with different goals will value different properties in
objects, which in turn will affect the relative likelihood with which
various objects are selected. The model therefore identifies subgroups
that require separate βo estimates. An object o that
is ideal for the goal of group g will often be selected by
the members of g, resulting in a high βgo
estimate. The same object might be anything but ideal to satisfy the
goal of a different group g’. As o will then not be
selected by the members of g’ the estimate of βg′o
will be low. That is, contrary to the single dimension of object
variation in our initial hypothetical example, there now are several
dimensions, one for each of the identified groups.
Individuals who share a similar goal may still differ regarding the
number of objects that make up their selection, depending on the
cut-offs for inclusion (or standards) they impose on the ideal that is
relevant with regard to their goal. They may select a large or small
number of objects, depending on whether they require objects to
possess the ideal property to a small or to a large extent,
respectively. Above, we identified the latent dimension with the ideal
and the positions of objects along the dimension with their
idealness. In a similar vein, individuals are awarded a position along
the dimension, indicating the idealness they require objects to
display in order to be selected. In Equation (1)
θi indicates the position of individual i along the
dimension for the group the individual is placed in. With the
positions of the objects fixed for all individuals that belong to the
same group, high θi estimates (i.e., high standards)
correspond to small selections, while low θi estimates
(i.e., low standards) correspond to large selections.
In a sense, θi acts as a threshold, separating objects that
are sufficiently able to fulfill individual i’s goal from
those that are not. However, it does not do so in a rigid
manner. Rather, in Equation (1) a selection decision is
considered the outcome of a Bernoulli trial, with the likelihood of
selection increasing with the extent an object surpasses the standard
θi and decreasing the more an object falls short of
it. Hence, an object to the right of the standard is not necessarily
selected, nor does an object to the left of the standard necessarily
remain unselected. It is the case, however, that an object is more
likely to be selected than not when it is positioned to the right of
the standard. The reverse holds for objects that are positioned to the
left of the standard. That is, across respondents the probability of
selection increases from left to right. The probabilistic nature of
the decisions accommodates the issue of the imperfect Guttman
patterns, in that it allows deviations for individual respondents to
occur.
A separate αg for each group determines the shape of the
response function that relates the unbounded extent to which an object
surpasses/falls short of the standard (βgo−θi) to the
probability of selection (bounded between 0 and 1). Unlike the
βgo’s and the θi’s, the αg’s in Equation
(1) can only take on positive values.
5 Demonstration
To demonstrate the merits of the formal framework we will apply it to
selection data for 10 ad hoc and goal-derived
categories. Although it has been acknowledged that there might exist
individual differences with respect to the goals that underlie these
categories (e.g., Barsalou [1991]), this has not been
empirically demonstrated. Therefore, these categories make for an
interesting test case. An analysis of the selection data with the
model in Equation (1) can elegantly test whether
individual differences in goals exist, by examining whether more than
one subgroup of respondents is identified.
In addition to determining the number of groups, we will try to infer
the contents of the corresponding ideals. The model infers ideals from
the selection data by awarding objects a position on one or more
dimensions (depending on the number of groups that are retained). We
will compare these βo’s to independently obtained measures of
idealness (i.e., judgments of the extent to which the objects satisfy
a number of ideals that were generated for the category). Earlier
studies have found that the representativeness of instances of ad hoc
and goal-derived categories increases with idealness (e.g.,
Barsalou [1985], Voorspoels et al. [2013]). These
studies treated all respondents alike, however, without regard to
possible individual differences. We will investigate whether this
relationship also holds in subgroups of respondents that are
identified from the data.
5.1 Materials
Categories and candidate objects were taken from
Voorspoels et al. [2010]b. They had 80 undergraduate
students generate instances of 10 different ad hoc and goal-derived
categories as part of a course requirement. For each category, 20 or
25 instances were selected for further study, spanning the range of
generation frequency for that category. Eight categories included 20
objects each (things to put in your car, things you
rescue from a burning house, things you use to bake an
apple pie, things you take to the beach, means of
transport between Brussels and London, properties and
actions that make you win the election, weapons used for
hunting, tools used when gardening) and two categories
included 25 each (things not to eat/drink when on a diet and
wedding gifts). Categories and objects are listed in the
Supplemental Materials. Throughout the text, we will employ an italic
typeface to denote categories and an italic capital typeface to denote
objects.
5.2 Ideal generation
The ideals were taken from
Voorspoels et al. [2013]. They had 25 undergraduate
students participate in an ideal generation task for course
credit. Each participant received a booklet containing a short
introduction and instructions to the task. For each of the 10
categories they were asked to generate characteristics or qualities
that members ideally display. (Only the category descriptions were
presented. No actual members were shown.) Participants could write
down up to seven characteristics for each
category. Voorspoels et al. [2013] considered ideals
that were generated more than three times for inclusion in an
idealness judgment task (see below). The resulting number of ideals
per category ranged from 3 to 13 (M=6). They are listed in
the Supplemental Materials. Throughout the text ideals will be printed
between triangular brackets in an italic typeface.
5.3 Idealness judgments
The idealness judgments were taken from
Voorspoels et al. [2013] as well. The degree to
which the objects in each category display an ideal property was
indicated by 216 undergraduate students in return for course
credit. Each participant judged the idealness of each object in an object set
relative to one ideal for five categories (a different ideal for each
category), yielding 15 participant judgments for each
ideal. Participants were instructed to indicate on a 7-point Likert
scale to what extent each object (i.e., the instances of the
category for which the ideal was generated) possessed the quality. The
estimated reliability of the judgments ranged from .71 to .98, with an
average of .89. The judgments were averaged across participants and
standardized using z-scores, resulting in a single score for each
object on each relevant ideal.
5.4 Category selection
The selection data were obtained for the purpose of this study. Two
hundred and fifty-four undergraduate students participated as part of
a course requirement. They were asked to carefully read through the
object set for each category and to select from the set the objects
they considered to belong to the category. It was emphasized that
there were no right or wrong answers, but that we were interested in
their personal opinions. Four different orders of category
administration were combined with two different orders of object
administration, resulting in eight different forms. These were
randomly distributed among participants.
6 Results
We present our findings in two sections. First, we will provide
details concerning the model-based analyses. This section comprises
inferences regarding the number of latent groups in the participant
sample, and the quality of data fit the model achieves. Both aspects
are evaluated solely on the basis of the object selection
data. Second, we will go a step further and evaluate whether the model
provides solutions that are interpretable, that is to say, whether the
dimensions of object variation that the model reveals can be related
to actual ideals that people conceive of in the particular contexts
under consideration.
6.1 Model analyses
6.1.1 Discovering latent groups
Each category’s selection data were analyzed separately using the
model in Equation (1). For every category solutions with
1, 2, 3, 4, and 5 latent subgroups were obtained. This was done using
WinBUGS (Lunn et al. [2000]) following the
procedures for the Bayesian estimation of mixture IRT models that were
outlined by Li et al. [2009]. (See Appendix A for WinBUGS
example code.) We followed Cho et al. [2013] in our
specification of the priors for the model parameters:
αg∼ Normal(0,1) and αg>0,g=1,…,G
βgo∼ Normal(0,1),g=1,…,G,o=1,...,O
θi| zi=g∼ Normal(µg,1),i=1,…,I,g=1,…,G
µg∼ Normal(0,1),g=1,…,G
(π1,...,πG)∼ Dirichlet(.5,...,.5)
zi∼ Categorical(π1,...,πG),i=1,…,I
with G the number of latent groups (1 to 5),
O the number of candidate objects (20 or 25, depending on the
category) and I the number of individuals (254 for each
category). µg is the mean group standard of group g. zi
is the latent variable that does the group assignment. Normal priors
were chosen for the distributions of βgo and θi
because this has been found to improve the stability of the estimation
process (Cho et al. [2013]). Latent group membership was
parameterized as a multinomially distributed random variable with
πg reflecting the probability of membership in subgroup
g. Both a Dirichlet prior and a Dirichlet process with
stick-breaking prior have been described as priors for the membership
probabilities. In a series of simulations Cho et al. [2013]
have established that the latter choice is not substantial. We ran 3
chains of 10,000 samples each, with a burn-in of 4,000 samples. The
chains were checked for convergence and label switching. All reported
values are posterior means, except for group membership which is based
on the posterior mode of zi.
To determine the suitable number of latent groups we relied on the
Bayesian Information Criterion (BIC, Schwarz [1978]) because of
extensive simulations by Li et al. [2009] that showed
that the BIC outperforms the AIC, the DIC, the pseudo-Bayes factor,
and posterior predictive model checks in terms of selecting the
generating mixture IRT model. (See Appendix B for additional
simulations.) The BIC provides an indication of the balance between
goodness-of-fit and model complexity for every solution. The solution
to be preferred is that with the lowest BIC. In accordance with the
procedure described by Li et al. [2009] every
αg, βgo, and µg was counted as a parameter,
along with all but one πg (because the different πg sum
to 1). This means that the number of parameters that enter the BIC
equals G×(O+3)−1.
Table 1: BIC values for five partitions of the selection data.
BIC
Category
1 group
2 groups
3 groups
4 groups
5 groups
car trinkets
3868
3861
3862
3976
4099
burning house
3981
3790
3882
4007
4133
diet ruiners
3762
3295
3440
3591
3743
wedding gifts
5971
5532
5375
5395
5485
pie necessities
3903
4013
4139
4265
4391
beach trinkets
2678
2785
2906
3014
3154
means of transport
4297
3909
3932
4047
4166
election strategies
2636
2690
2766
2868
2984
hunting weapons
4532
4425
4431
4537
4656
gardening tools
3314
3409
3381
3494
3600
Table 1 holds for every category five BIC values,
corresponding to five partitions of increasing complexity. For each
category the lowest BIC is set in bold typeface. There were four
categories for which the BIC indicated that a one-group solution was
to be preferred. This was the case for things you use to bake
an apple pie, things you take to the beach,
properties and actions that make you win the election and
tools used when gardening. For these categories the solution
that provided the best account of the selection data (taking into
account both fit and complexity) involved the extraction of a single
set of βo estimates for all 254 respondents. Any individual
selection differences were accounted for in terms of differences in
θi estimates.
For the remainder of the categories the BIC indicated that multiple
groups were to be discerned among the respondents. In the case of
things to put in your car, things you rescue from a
burning house, things not to eat/drink when on a diet,
means of transport between Brussels and London, and
weapons used for hunting the BIC suggested there were two
such groups. In the case of wedding gifts the BIC suggested
there were three. The individual selection differences in these
categories could not be accounted for merely by different θi
estimates. They also required the extraction of multiple sets of
βo estimates, one for each subgroup that was
discerned. Whenever multiple sets of βo estimates were
required to account for the selection data, this constituted evidence
that respondents employed different choice criteria.
6.1.2 Model fit
The BIC is a relative measure of fit. For a given data set it
indicates which model from of a set of candidate models is to be
preferred. The BIC is not an absolute measure of fit, however. It does
not indicate whether the preferred model adequately describes the data
it was fitted to. We used the posterior predictive distribution to see
whether this was the case. The posterior predictive distribution
represents the relative probability of different observable outcomes
after the model has been fitted to the data. It allows us to assess
whether the solutions the BIC prefers fit the selection data in
absolute terms.
First, we consider the categories for which the BIC revealed only one
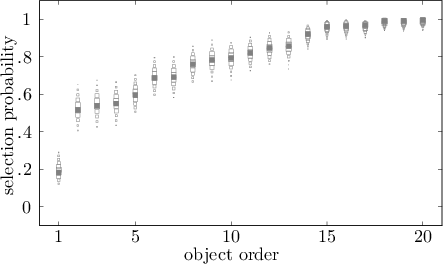
group. As an illustrative case, Figure 1
depicts the data and posterior predictive distributions for the
things you use to bake an apple pie category. For every
object it contains a filled gray square, representing the proportion
of respondents who selected it. The objects are ordered along the
horizontal axis in increasing order of selection to facilitate
inspection. Object 1 (MICROWAVE) is the object that was least
selected: less than 20% of respondents chose to include it in the
category. Object 20 (BAKING TIN) is the object that was most
selected: all respondents except one chose to include it. The
remaining objects are in between in terms of selection
proportion. Object 2 (LADLE), for instance, was chosen by
about half of the respondents. Object 3 (FOOD PROCESSOR) was
chosen somewhat more often, etc. Figure 1
also contains for every object outlines of squares, representing the
posterior predictive distribution for the corresponding selection
probability. The size of the squares’ outlines is proportional to the
posterior mass that was given to the various selection probabilities.
The posterior predictive distributions indicate that the one-group
model provided a decent fit to the selection data. The distributions
are centered on the objects’ selection proportions and drop off pretty
quickly from there. In this manner, they capture the relative
selection differences that exist between the objects: The posterior
predictive distributions follow the rising pattern that the empirical
data show.1 A
similar pattern was observed for the other one-group categories.
Figure 1: Posterior predictive distribution of the one-group model
for the things you use to bake an apple pie selection
data. Filled gray squares show per object the proportion of
respondents who selected it for inclusion in the category. Objects
are ordered along the horizontal axes according to the proportion
of selection. Outlines of squares represent the posterior
predictive distribution of selection decisions. The size of these
outlines is proportional to the posterior mass that is given to
the various selection
probabilities.
We now turn to the categories for which the framework identified two
or more latent participant groups. The results for the meanwhile
familiar category of things you rescue from a burning house
provide an exemplary case. The BIC indicated that a two-groups
solution was to be preferred for this category.
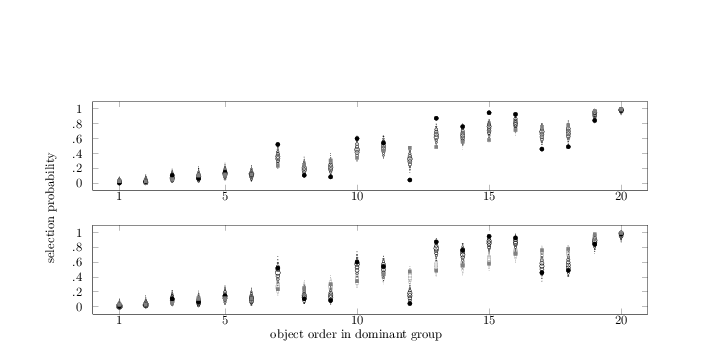
In Figure 2 the category’s 20
candidate objects are ordered along the horizontal axes according to
the selection proportion in the larger of the two
groups.2 For each object a
filled gray square represents the proportion of respondents from the
dominant group who selected it for inclusion in the category. A filled
black circle represents for each object the proportion of respondents
from the smaller group who selected it for inclusion. The two panels
in Figure 2 are identical with
respect to these data. Whether an object was likely to be selected or
not, depends on the subgroup. Objects 12 (LETTERS), 17
(PICTURES), and 18 (HEIRLOOMS), for instance, were
selected more often by members of the dominant group (gray squares)
than they were by members of the smaller group (black circles). The
reverse holds for objects 7 (CLOTHING), 13 (CAR
KEYS), and 15 (CELLULAR PHONE). These selection
differences support the division the BIC suggested.
Figure 2: Posterior predictive distribution of the one-group model
(upper panel) and the two-groups model (lower panel) for the
things you rescue from a burning house selection
data. Filled gray squares show per object the proportion of
respondents from the larger group who selected it for inclusion in
the category. Filled black circles show per object the proportion
of respondents from the smaller group who selected it for
inclusion in the category. Objects are ordered along the
horizontal axes according to the proportion of selection in the
larger group. Outlines of squares and circles represent the
posterior predictive distributions of selection decisions for the
larger and smaller group, respectively. The size of these outlines
is proportional to the posterior mass that is given to the various
selection probabilities.
The upper panel in Figure 2 shows the
posterior predictive distributions of selection probabilities that
result from the one-group model. The lower panel shows the posterior
predictive distributions that result from the two-groups model. For
every object the panels include a separate distribution for each
subgroup (square outlines for the larger group; circular outlines for
the smaller group). The size of the plot symbols is proportional to
the posterior mass given to the various selection probabilities.
Contrary to the one-group model, the two-groups model can
yield different model predictions due to separate βo
estimates for each group. In the lower panel of Figure
2 the posterior predictive
distributions for the two groups are quite different when this is
required. In the case of object 15 (CELLULAR PHONE), for
instance, a positive selection response is predicted for members of
the smaller group, while the members of the dominant group are deemed
undecided with the posterior predictive distribution centering on
.50. The posterior predictive distributions that are due to the
two-groups model (lower panel) are clearly different for the two
groups, while the posterior predictive distributions that are due to
the one-group model (upper panel) are not. Figure
2 thus shows that for things
you rescue from a burning house the two-groups model provides a
better fit to the selection data than the one-group model does and
that its extra complexity is justified.
The results for the things you rescue from a burning house
category are representative for things not to eat/drink when
on a diet, weapons used for hunting and means of
transport between Brussels and London. The respondents fall into
distinct groups, whose members employ different choice criteria. That
is, between groups different objects are likely to be selected for
inclusion in the category. The model is able to account for these
differences by extracting a separate set of βo estimates for
every group. Within each group, the individuals use the same choice
criteria. That is, by combining different θi estimates with
a single set of βo estimates for the individuals within a
group, the model is able to account for the subgroup’s selection
data. The categories things to put in your car and
wedding gifts are different in this respect. They warrant a
separate treatment.
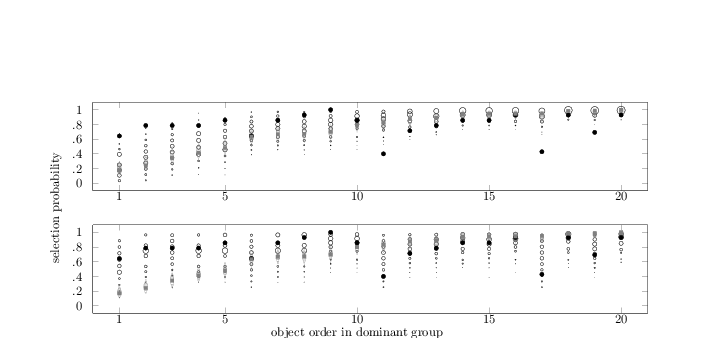
The BIC indicated that for things to put in your car
two-groups were to be discerned among the respondents. Figure
3 presents the corresponding selection
proportions in a similar manner as Figure
2 did. Both panels contain for every
object a gray square that represents the proportion of respondents
from the dominant group who selected the object and a black circle
that represents the proportion of respondents from the small group who
selected it. As before, objects are ordered along the horizontal axes
according to the selection proportion in the dominant group. This
allows for the identification of objects that were not as likely to be
selected in one group as they were in the other. Object 1
(DECK OF CARDS), for instance, was hardly selected by members
of the dominant group, but selected by the majority of the smaller
group members. Selection differences like these again support the
division the BIC suggested.
The inter-object selection proportions are pronounced in the dominant
group. The selection proportions start off small for objects like
DECK OF CARDS (object 1) for which the majority in the
dominant group agrees that they are not generally kept in cars. They
then gradually increase until high selection proportions are attained
for an object like PARKING DISC (object 20), which almost
everyone keeps in his or her car. The corresponding posterior
predictive distributions closely resemble those we saw in Figure
1 for things you use to bake an
apple pie and the lower panel of Figure
2 for things you rescue from
a burning house: The distributions follow the rising pattern that
the empirical data show, centered as they are on the objects’
selection proportions and dropping off rapidly from there. This is
true, both for the posterior predictive distributions that are due to
the two-groups model and the ones that are due to the one-group
model. The latter’s ability to account for the empirical data of the
dominant group is not that surprising given that the dominant group
comprises the vast majority of the respondents (91%) and as such
counts heavily towards the estimation of the model.
While the two-groups model accounts well for the data of the dominant
group, it does not appear to fit the data of the smaller group. The
corresponding posterior predictive distributions are not centered on
the empirical selection proportions, nor are they very specific. For
the distributions that are due to the one-group model (upper panel),
this lack of fit might be attributed to the model’s inability to
account for pronounced between-group selection differences with a
single set of βo estimates, but this is hardly an explanation
for the two-groups model’s failure to fit the empirical data. After
all, the two-groups model’s estimation is intimately tied to the
identification of the two latent groups. The broad posterior
predictive distributions that are due to the two-groups model indicate
that the set of parameter estimates obtained for the smaller group
does not allow for predictions that closely mirror the group’s
selection data. The smaller group’s response patterns do not appear to
carry sufficient information to allow accurate prediction, perhaps
because there are few response patterns to go on (the smaller group is
only comprised of 9% of the respondents), there is little variability
in the response patterns (the objects’ selection proportions are
almost invariably high), or the variability that is contained in the
response patterns is not consistent (individuals decide to leave
different objects out of the selection).
Whatever the reason may be, the result is a division of the
respondents that entails the identification of one group of
individuals who behave consistently (the dominant group) and that of a
“rest” group of individuals who behave differently (the smaller
group). The βo estimates for this smaller group do not allow
one to specify what it means to be in this second group, besides not
being in the first, dominant group. Indeed, the BIC indicated that it
is beneficial (in terms of fit) to retain these individuals in a
separate group, but the posterior predictive distributions indicate
that the parameter estimates for that group are not a reliable source
to characterize its members. All that can be said about the
smaller group’s members is that their response patterns are so
different from those of the dominant group that it is not tenable to
assume they have the same origin. Note that the resulting division is
still a sensible one, as it is better to discern the individuals that
select objects in one way from those that do so differently (whatever
that may mean) than to treat all of them (erroneously) as behaving the
same way. (See Appendix B for a simulation study that supports this
interpretation.)
Figure 3: Posterior predictive distribution of the one-group model
(upper panel) and the two-groups model (lower panel) for the
things to put in your car selection data. Filled gray
squares show per object the proportion of respondents from the
larger group who selected it for inclusion in the category. Filled
black circles show per object the proportion of respondents from
the smaller group who selected it for inclusion in the
category. Items are ordered along the horizontal axes according to
the proportion of selection in the larger group. Outlines of
squares and circles represent the posterior predictive
distributions of selection decisions for the larger and smaller
group, respectively. The size of these outlines is proportional to
the posterior mass that is given to the various selection
probabilities.
A similar pattern was observed for wedding gifts: The BIC
indicated that three sets of βo estimates were to be
retained. The parameter estimates for the largest and the smallest
group suffered from the same problem as the parameter estimates for
the smaller group for the things to put in your car data
did. They were not very informative when it comes to identifying the
considerations that underlay the selection decisions of the
individuals in those groups. That is, it is just not the case that the
largest (smallest) and the intermediate group employed different
choice criteria. The members of the largest (smallest) group did not
employ the same choice criterion either, so there is no use in trying
to determine it. This conclusion, of course, has implications for
the analyses that follow. One should refrain from interpreting the
uninformative estimates through regression analyses.
6.2 Regression analyses
To attempt to infer which ideals were used by the respondents, we
regressed the βgo estimates upon the various idealness
judgments that were obtained for a category. The higher the estimate
for an object is, the higher its likelihood of being included in the
category. We therefore expect significant positive regression weights
for the ideals that are driving the selection decisions. The use of
regression analyses allows one to investigate whether more than one
ideal drives the selection decisions. To keep the analyses in line
with traditional correlational analyses, in which only the best ideal
is determined, we opted for a forward selection procedure with a
criterion of .05 to determine which ideals are included in the
regression equation. This way the ideal with the highest correlation
with the βgo estimates is always the first to be included
(provided that it is a significant predictor of the βgo
estimates).
In case a solution with multiple groups is retained for a category,
one can turn to the relation of the respective βgo estimates
with the idealness judgments to better understand how the subgroups
differ from one another. If individuals select objects with extreme
values on a relevant ideal in order to satisfy their goals, groups
with different goals are likely to select objects that have extreme
values on different ideals.
A separate regression analysis was conducted for all groups determined
in the previous section, except for the smallest one for
things to put in your car and the largest and the smallest
one for wedding gifts. Inspection of the posterior predictive
distributions for these groups indicated that the mean βgo
estimates were not sufficiently reliable to establish conclusions on
regarding the considerations that underlay the selection decisions of
the individuals who comprise the groups (see above). Table
2 holds the results of the regression analyses. For
every group it shows the R2 and the signs of the regression weights
for ideals with a p-value less than .05. Ideals that did not
contribute significantly are indicated by dots. The number of the
ideals refers to their order in the Supplemental Materials. The first
line in Table 2, for instance, conveys that five
ideals were withheld for things to put in your car of which
ideals 1 (<easy to store away>), 3 (<makes
travel more agreeable>) and 4 (<small>) did not
enter in the regression equation for the β1o estimates. The
contribution of ideal 2 (<guarantees safety>) was
significant and negative, while the contribution of ideal 5
(<useful>) was significant and positive.
Table 2: R2 and regression weights from the multiple regression
analyses with forward selection procedure. The signs of the
regression weights with a p-value less than .05 are displayed,
others are replaced by a dot.
Ideal
Category
Group
R2
1
2
3
4
5
6
7
8
9
10
11
12
13
car trinkets
group 1
.84
.
-
.
.
+
burning house
group 1
.97
.
+
.
.
.
.
.
.
+
burning house
group 2
.80
.
.
.
.
.
.
+
.
.
diet ruiners
group 1
.93
.
.
+
.
.
diet ruiners
group 2
.86
.
.
-
.
.
wedding gifts
group 2
.54
.
.
+
.
.
.
pie necessities
single
.63
+
.
.
.
beach trinkets
single
.72
+
+
.
+
.
.
means of transport
group 1
.85
.
+
.
.
means of transport
group 2
.59
.
.
+
.
election strategies
single
.89
+
.
.
hunting weapons
group 1
.92
.
-
.
.
.
+
.
.
+
.
.
.
.
hunting weapons
group 2
.87
.
.
.
.
.
+
.
.
.
.
.
.
.
gardening tools
single
.86
.
+
.
.
.
Table 2 shows that the externally obtained
idealness judgments account very well for the relative probability
with which objects are selected for inclusion in a category. Across
the 14 groups retained for interpretation, the squared correlation
between the βgo estimates and the best idealness judgments
averaged .81.
For several categories more than one ideal was driving the selection
decisions. This was the case for things to put in your car
(group 1), things you rescue from a burning house (group 1),
things you take to the beach, and weapons used for
hunting (group 1). Yet, the contribution of ideals over and above
the first dominant one, while statistically reliable, was generally
rather small, and for the majority of groups only one ideal
contributed significantly to the βgo estimates.
In two cases where multiple ideals entered the regression equation,
one ideal contributed negatively (contrary to our expectations). For
weapons used for hunting the regression analysis for the
large group indicated that three ideals (<easy to take with
you>, <light>, and <discreet>) yielded
a significant contribution. We presume that <discreet>
had a negative contribution because some weapons that are suited for
hunting are difficult to conceal (e.g., SPEAR, β=1.32),
while others that are less suited for hunting are easy to conceal
(e.g., ALARM GUN, β=-1.11). In the regression analysis
for things to put in your car both <useful> and
<guarantees safety> were significant predictors. Here the
negative contribution of <guarantees safety> probably
reflects the fact that many objects we keep in our car do not benefit
safety (e.g., COMPACT DISCS, β=1.30).
The results of the regression analyses support our assertion that, for
the four categories with two groups, the criteria that supposedly
governed the selection decisions differ from group to group. Either
different ideals predicted the βo estimates of the different
groups (<important> and <valuable>
vs. <necessary> in the case of things you rescue
from a burning house and <comfortable>
vs. <fast> in the case of means of transport
between Brussels and London). Or the regression analyses identified
ideals that contributed to one set of βo estimates, but not
to the other (<light> and <discreet> in the
case of weapons used for hunting). Or the βo
estimates of the different groups related to the same ideal in
opposing directions. This was the case for the <many
calories> ideal in the things not to eat/drink when on a
diet category.3
6.3 Conclusions and discussion
This paper started with a quote that was taken from
theburninghouse.com. It described a number of intuitions
regarding the decision which objects to save from one’s burning
house. The intuitions were intended to account for the diversity of
objects in the pictures that respondents uploaded to the website
of the belongings they would save. These intuitions were found to hold
across a variety of other ad hoc and goal-derived categories: (iii)
The selection decisions revealed information about the participants in
the shape of the ideals they used when making their choices. (ii) We
established considerable individual differences, both in the employed
ideals and the required idealness. (i) Across different groups, but
also within a single group, multiple considerations informed the
selection decisions. We discuss these findings below.
Goal-derived and ad hoc categories have vague
boundaries. Barsalou [1983] already pointed to this when he
observed that respondents do not agree about the objects that are to
be considered members of a particular ad hoc category. The current
results establish that it is unfortunate to denote divergences from
the majority opinion as inaccuracies, as is habitually done (e.g.,
Hough et al. [1997], Sandberg et al. [2012], Sebastian and Kiran [2007]). Rather,
these individual differences can be taken to reflect differences
of opinion as to which objects meet goal-relative criteria.
In some categories, these individual differences are best explained by
assuming that all respondents share the same goal but differ in the
standard they impose for inclusion (see also
Barsalou [1985], Barsalou [1991], Graff [2000]). That is, although they
agree on the properties that objects preferably have (i.e., the
ideal), they disagree about the extent to which objects have to
display these properties (i.e., the idealness) to be included. For
these categories a single dimension of object variation was retained
for the entire group of respondents. The only individual differences
required to account for the selection differences were differences in
θi, the cut-off for inclusion that is imposed on this
dimension. The positions of the objects along the single dimension of
object variation (i.e., the βo estimates) could reliably be
related to (external) idealness judgments (see also
Barsalou [1985], Lynch et al. [2000], Voorspoels et al. [2013]).
In other categories, a proper account of the individual differences
requires one to abandon the assumption that all respondents share the
same goal. Rather, one needs to recognize that there exist subgroups
of respondents with different goals. Within each of these subgroups,
respondents are still thought to differ with regard to the standard
they impose for inclusion. As before, this standard is goal-relative:
It pertains to an ideal that serves a particular goal. The contents of
the ideal, then, is no longer the same for two individuals when they
belong to separate subgroups. In order to account for the selection
differences that were observed for these categories, both
individual differences in βo and θi were
required. One dimension of object variation (i.e., a set of
βo estimates) was retained for each subgroup of
respondents. For every individual one θi estimate was
determined, indicating the cut-off for inclusion s/he imposed on one
of these dimensions (depending on the subgroup the individual belongs
to).
The results of the regression analyses suggested that different
criteria governed the selection of objects in the subgroups of
respondents identified by the model. Either the βo estimates
of the different groups related to the same ideal in opposing
directions; or different ideals correlated with the βo
estimates of the different groups; or the regression analyses
identified ideals that contributed to one set of βo
estimates, but not to the other. Note that the finding that sometimes
multiple ideals predicted a group’s βo estimates should not
be mistaken for a source of individual differences. The model analysis
identified the members of the group as using the same criteria when
selecting objects. A regression analysis deeming multiple ideals
significant hence suggests that all respondents within that
group consider all these ideals when selecting objects.
Other predictors of ad hoc and goal-derived category membership than
ideals have been considered in the past
(Barsalou [1985], Voorspoels et al. [2013]). We did not
include familiarity as a predictor because Barsalou already discarded
the variable as a predictor in his seminal 1985 paper. We did not
consider central tendency because both Barsalou [1985] and
Voorspoels et al. [2013] discarded the variable in
favor of ideals. Frequency of instantiation was not included as a
predictor because this was the variable that informed the inclusion of
candidate objects for
study. Barsalou [1991], Barsalou [2003], Barsalou [2010] has noted that
when instances of a previously uninstantiated category have to be
generated, there are yet other considerations that need to be
monitored. Not just any object makes for a genuine instantiation of
the category things you rescue from a burning house. Credible
instances have to meet particular constraints that reflect everyday
knowledge about the world. For this particular category, the objects
are to be generally found in houses and should be movable, for
instance. Our analyses of the selection data could not pick up these
kinds of considerations as all the candidate objects in the selection
task came from an exemplar generation task and therefore already
adhered to the necessary constraints.
7 General discussion
The premise of this paper is that object selection carries information
about the selection criteria that decision makers use. Assuming
that most selection criteria are not idiosyncratic, but shared by
several individuals, the relative frequency with which particular
objects are selected can be used to uncover the common criteria. An
object’s selection frequency is likely to reflect the extent to which
the object meets the choice criteria, with objects being selected more
frequently, the better they meet the choice criteria. From the
identification of the selection criteria, it tends to be a small step
to the identification of the end states individuals may have been
aiming for. For instance, if one observes an individual saving mostly
pricey objects from a house that is on fire, the inference that this
person’s main goal is to minimize financial losses tends to be
justified.
The challenge lies in the identification of individuals who use the
same criterion. A particular object might meet one criterion, but not
another. The above rationale will thus break down when
individuals employ different criteria, because the resulting selection
frequencies will reflect a mixture of criteria. The (common) criterion
one might infer from such an unreliable source, might not be employed
by any of the individuals making the selection decisions. One should
exercise care not to discard important individual differences in favor
of a nonsensical solution.
To this end we offered a treatment of individual differences in
selection data that allows us to infer the criteria that underlay the
selection decisions. It recognizes individual differences, both in the
criteria and in the extent to which objects are required to meet
them. Its usefulness was demonstrated in the context of 10 ad hoc and
goal-derived categories. It accounted well for the selection
differences that were found for these categories; it allowed for the
identification of individuals who used different criteria; and the
contents of these criteria could be substantiated. This suggests that
our contention about the two kinds of individual differences is a
viable one.
The distinction between within-group (standard) differences and
between-group (criteria) differences has been made in several
different contexts (e.g.,
Bonnefon et al. [2008], Lee and Wetzels [2010],Zeigenfuse and Lee [2009]). It
is tempting to think of this distinction as one involving continuous
(quantitative) versus discrete (qualitative) individual
differences. However, if one is willing to assume that all potential
criteria are originally available to individuals and the groups merely
differ regarding the criteria they do not attend or consider
important, the between-group differences may also be considered
continuous. The situation could then be conceived of as a distribution
of positive and zero weights across employed versus unattended or
irrelevant criteria, respectively (see Verheyen and Storms [2013],
for a discussion). The problem of distinguishing continuous
(quantitative) and discrete (qualitative) differences echoes the
debate in the decision making literature on the ability to
discriminate between single-process and multiple-strategy models
(Newell [2005], Newell and Bröder [2008]).
Irrespective of how the debate will be resolved, the two kinds of
individual differences can offer a fresh perspective on research that
attempts to relate external information about individuals to their
decision making. Examples pertain to the effects of personality
(Dewberry et al. [2013], Hilbig [2008]), affective state
(Hu et al. [2014], Scheibehenne and von Helversen [2015], Shevchenko et al. [2014]),
intelligence
(Bröder [2003], Bröder and Newell [2008], Mata et al. [2007]) and
expertise (Garcia-Retamero and Dhami [2009], Pachur and Marinello [2013]). It would
be straightforward to relate variables like these to criteria use
(group membership) and/or standard use (see
Maij-de Meij et al. [2008], Van den Noortgate and Paek [2004],
and Verheyen et al. [2011a], for
demonstrations). Alternatively, one could consider selection decisions
in various circumstances (e.g., Slovic [1995]) or at various
times (Hoeffler and Ariely [1999], Simon et al. [2008])
and look for (in)consistencies in criteria and/or standard use across
them (see Tuerlinckx et al. [2014], and
Verheyen et al. [2010], for demonstrations).
We believe the above examples testify to the potential of mixture IRT
models to answer substantial questions in a variety of judgment and
decision making contexts, particularly in those such as
multi-attribute decision making, where individual differences are
likely to exist in the sources of information that inform
decisions. We have presented one particular mixture IRT model. The
class of mixture IRT models includes many more, some of which can
incorporate guesses (Li et al. [2009]) or can accommodate
continuous outcome measures
(Maij-de Meij et al. [2008], Von Davier and Yamamoto [2004]) to
give just a few possibilities. The applications are thus by no
means limited to the choice situations that we have treated
here. Mixture IRT models add to the mixture models that are already
available in the decision making literature
(Lee [2014], Lee and Newell [2011], Scheibehenne et al. [2013], Van Ravenzwaaij et al. [2014]). An
important difference with the existing models is that the mixture IRT
models do not require one to confine the set of decision criteria
beforehand, but rather uncover them as latent sources of individual
differences. Selection between models with various numbers of inferred
criteria then offers a natural way of dealing with the question of how
many criteria comprise the set of actual alternatives
(Glöckner and Betsch [2011], Marewski and Schooler [2011], Scheibehenne et al. [2013]). The
main challenge for mixture IRT applications may lie in the (post
hoc) interpretation of the established latent criteria (but note that
a priori candidate interpretations can be made part of the modeling
endeavour and tested for suitability; see
Janssen et al. [2004], and
Verheyen et al. [2011]b).
8 Conclusion
In this paper we have demonstrated how one can infer from selection
decisions the considerations that preceded them. We have shown how,
from the choice for a specific set of objects, one can infer something
about the purposes and desires of the individuals making the
choices. We have learned that, despite pronounced selection
differences, individuals tend not to be so different after all. The
goals they pursue with their choices are generally shared by many
others. Perhaps most importantly, we think that even more can be
learned if the proposed approach to individual selection differences
is combined with other sources of information about the individuals
and is applied in other choice or judgment situations as well.
References
Adelman, J. S., Brown, G. D. A., and Quesada, J. F. ().
Contextual diversity not word frequency determines word naming and
lexical decision times.
Psychological Science.
[ bib ]
Adelson, B. (1985).
Comparing natural and abstract categories: A case study from computer
science.
Cognitive Science, 9:417--430.
[ bib ]
Ahn, W. (1998).
Why are different features central for natural kinds and artifacts?
The role of causal status in determining feature centrality.
Cognition, 69:135--178.
[ bib ]
Ahn and Lassaline [Ahn, W., Lassaline, M.E., 1995. Causal structure
in categorization.Proceedings of the Seventeenth Annual Conference
of the Cognitive Science Society, Pittsburgh,PA, pp. 521-526] recently
proposed a causal status hypothesis which states thatfeatures that
play a causal role in a relational structure are more central than
their effects.This hypothesis can account for previous research demonstrating
that compositional featuresare generally important for natural kinds
but functional features are generally important forartifacts. The
causal status hypothesis explains this category-feature interaction
effect in termsof differences in the causal status of compositional
and functional features between naturalkinds and artifacts. Experiments
1 and 2 examined real-life categories used in previousstudies, and
found positive correlations between the causal status of the features
and theircentrality across natural and artifactual kinds. Experiments
3 and 4 manipulated the causalstatus of compositional and functional
features in artificial categories, and showed that it wascausal status
rather than the interaction between the type of feature and the type
of categoryper se that accounted for feature centrality. The implications
of these results on the distinctionsbetween natural kinds and artifacts
are discussed.
Keywords: Feature Centrality
Ahn, W. (1999).
Effect of causal structure on category construction.
Mem.Cognit., 27(6):1008--1023.
[ bib |
www: ]
In four experiments, the question of how the causal structure of features
affects the creation of new categories was examined. Features of
exemplars to be sorted were related in a single causal chain (causal
chain), were caused by the same factor (common cause), or caused
the same effect (common effect). The results showed that people are
more likely to rely on common-cause or common-effect background knowledge
than on causal-chain background knowledge in category construction.
Such preferences suggest that the common-cause or the common-effect
structures are considered more natural conceptual structures
Keywords: Adult, Attention, Concept Formation, Female, Human, Knowledge, Male,
Problem Solving, Serial Learning, Support,U.S.Gov't,Non-P.H.S., Support,U.S.Gov't,P.H.S.
Ahn, W., Brewer, W., and Mooney, R. (1992).
Schema acquisition from a single example.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 18:391--412.
[ bib ]
Ahn, W., Gelman, S., Amsterlaw, J., Hohenstein, J., and Kalish, C. (2000a).
Causal status effect in children's categorization.
Cognition, 76(2):35--43.
[ bib |
www: ]
The current study examined the causal status effect (weighing cause
features more than effect features in categorization) in children.
Adults (Study 1) and 7-9-year-old children (Study 2) learned descriptions
of novel animals, in which one feature caused two other features.
When asked to determine which transfer item was more likely to be
an example of the animal they had learned, both adults and children
preferred an animal with a cause feature and an effect feature rather
than an animal with two effect features. This study is the first
direct demonstration of the causal status effect in children
Keywords: Adult, Association Learning, Child, Concept Formation, Causal status
effect
Ahn, W., Kalish, C., Gelman, S., Medin, D., Luhmann, C., Atran, S., Coley, J.,
and Shafto, P. (2001).
Why essences are essential in the psychology of concepts.
Cognition, 82(1):59--69.
[ bib |
www: ]
Keywords: Adult, Child, Essentialism
Ahn, W. and Kalish, C. W. (2000).
The role of mechanism beliefs in causal reasoning.
In Keil, F. and Wilson, R. A., editors, Explanation and
Cognition, chapter 8, pages 199 -- 226. MIT Press, Cambridge, MA.
[ bib ]
Ahn, W., Kalish, C. W., Medin, D. L., and Gelman, S. A. (1995).
The role of covariation versus mechanism information in causal
attribution.
Cognition, 54(3):299--352.
[ bib |
http ]
Traditional approaches to causal attribution propose that information
about covariation of factors is used to identify causes of events.
In contrast, we present a series of studies showing that people seek
out and prefer information about causal mechanisms rather than information
about covariation. Experiments 1, 2 and 3 asked subjects to indicate
the kind of information they would need for causal attribution. The
subjects tended to seek out information that would provide evidence
for or against hypotheses about underlying mechanisms. When asked
to provide causes, the subjects' descriptions were also based on
causal mechanisms. In Experiment 4, subjects received pieces of conflicting
evidence matching in covariation values but differing in whether
the evidence included some statement of a mechanism. The influence
of evidence was significantly stronger when it included mechanism
information. We conclude that people do not treat the task of causal
attribution as one of identifying a novel causal relationship between
arbitrary factors by relying solely on covariation information. Rather,
people attempt to seek out causal mechanisms in developing a causal
explanation for a specific event
Keywords: Explanation
Ahn, W., Kim, N., Lassaline, M., and Dennis, M. (2000b).
Causal status as a determinant of feature centrality.
Cognitive Psychology, 41(4):361--416.
[ bib |
www: ]
One of the major problems in categorization research is the lack of
systematic ways of constraining feature weights. We propose one method
of operationalizing feature centrality, a causal status hypothesis
which states that a cause feature is judged to be more central than
its effect feature in categorization. In Experiment 1, participants
learned a novel category with three characteristic features that
were causally related into a single causal chain and judged the likelihood
that new objects belong to the category. Likelihood ratings for items
missing the most fundamental cause were lower than those for items
missing the intermediate cause, which in turn were lower than those
for items missing the terminal effect. The causal status effect was
also obtained in goodness-of-exemplar judgments (Experiment 2) and
in free-sorting tasks (Experiment 3), but it was weaker in similarity
judgments than in categorization judgments (Experiment 4). Experiment
5 shows that the size of the causal status effect is moderated by
plausibility of causal relations, and Experiment 6 shows that effect
features can be useful in retrieving information about unknown causes.
We discuss the scope of the causal status effect and its implications
for categorization research
Ahn, W. and Kim, N. S. (2000).
The causal status effect in categorization: An overview.
In Keil, F. and Wilson, R., editors, Explanation and Cognition,
chapter 8, pages 23--65. MIT, Cambridge, MA.
[ bib ]
(from the chapter) This chapter discusses why some features of concepts
are more central than others. The authors begin with a review of
possible determinants of feature centrality, then focus on one important
determinant, the effects of causal background knowledge on feature
centrality. The different approaches to understanding feature centrality
(content-based, statistical, and theory-based) are addressed, then
a general introduction is made to the Causal Status hypothesis. The
authors present their rationale for predicting the causal status
effect and empirical results supporting the hypothesis under various
contexts. They describe previous categorization studies that can
be accounted for by this hypothesis, and discuss moderating factors
for the effect. Finally, they examine the potential consequences
of focusing only on causal relations among features in study the
effect of lay theories on feature centrality. (PsycINFO Database
Record (c) 2003 APA, all rights reserved)
Ahn, W., Marsh, J., Luhmann, C., and Lee, K. (2002).
Effect of theory-based feature correlations on typicality judgments.
Memory & Cognition, 30(1):107--118.
[ bib |
www: ]
In the present study, we examine what types of feature correlations
are salient in our conceptual representations. It was hypothesized
that of all possible feature pairs, those that are explicitly recognized
as correlated (i.e., explicit pairs) and affect typicality judgments
are the ones that are more likely theory based than are those that
are not explicitly recognized (i.e., implicit pairs). Real-world
categories and their properties, taken from Malt and Smith (1984),
were examined. We found that explicit pairs had a greater number
of asymmetric dependency relations (i.e., one feature depends on
the other feature, but not vice versa) and stronger dependency relations
than did implicit pairs, which were statistically correlated in the
environment but were not recognized as such. In addition, people
more often provided specific relation labels for explicit pairs than
for implicit pairs; these labels were most often causal relations.
Finally, typicality judgments were more affected when explicit correlations
were broken than when implicit correlations were broken. It is concluded
that in natural categories, feature correlations that are explicitly
represented and affect typicality judgments are the ones about which
people have theories
Ahn, W. and Medin, D. (1992).
A two-stage model of category construction.
Cognitive Science, 16:81--121.
[ bib ]
Ahn, W., Novick, L., and Kim, N. (2003).
Understanding behavior makes it more normal.
Psychon.Bull.Rev., 10(3):746--752.
[ bib |
www: ]
Meehl (1973) has informally observed that clinicians will perceive
a patient as being more normal if they can understand the patient's
behaviors. In Experiment 1, undergraduate participants received descriptions
of 10 people, each with three characteristics (e.g., frequently suffers
from insomnia) taken from the Diagnostic and Statistical Manual of
Mental Disorders (American Psychiatric Association, 1994). When the
characteristics formed a plausible causal chain, adding a causal
explanation increased perceived normality; but when a causal chain
was implausible, perceived normality decreased. In Experiments 2
and 3, a negative life event (e.g., is very stressed out due to her
workload) was added as an explanation for the first characteristic
in a three-characteristic causal chain. Undergraduates, graduate
students in clinical psychology, and expert clinicians all reliably
perceived the patients as being more normal with these explanations
than without them, confirming Meehl's prediction
Keywords: Cognition, Human, Life Change Events, Social Behavior, Social Perception
Ajzen, I. and Fishbein, M. (1975).
A bayesian analysis of attribution processes.
Psychological Bulletin, 82:261--277.
[ bib ]
Akaike, H. (1973).
Information theory as an extension of the maximum likelihood
principle.
In Petrov, B. N. and Csaki, F., editors, Second International
Symposium on Information Theory, pages 267--281. Akademiai Kiado, Budapest.
[ bib ]
Allen, S. and Brooks, L. (1991).
Specializing the operation of an explicit rule.
Journal of Experimental Psychology: General, 120:3--19.
[ bib ]
Ameel, E. and Storms, G. (2006).
From prototypes to caricatures: Geometrical models for concept
typicality.
Journal of Memory & Language, 55:402--421.
[ bib ]
Ameel, E., Storms, G., and Malt, B. C. (2008).
Object naming and later lexical development: From baby bottle to beer
bottle.
Journal of Memory and Language, 58:262--285.
[ bib ]
Ameel, E., Storms, G., Malt, B. C., and Sloman, S. (2005).
How bilinguals solve the naming problem.
Journal of Memory and Language, 53:60--80.
[ bib ]
Andersen, E. B. (1973).
A goodness of fit test for the Rasch model.
Psychometrika, 38:123--140.
[ bib ]
Anderson, J. (1991).
The adaptive nature of human categorization.
Psychological Review, 98:409--429.
[ bib ]
Anderson, J. and Bower, G. (1973).
Human associative memory.
Winston.
[ bib ]
Anderson, J. and Murphy, G. (1986).
The psychology of concepts in a parallel system.
Physica, 22D:318--336.
[ bib ]
Anderson, R. and Ortony, A. (1975).
On putting apples into bottles--a problem of polysemy.
Cognitive Psychology, 7:167--180.
[ bib ]
Anglin, J. (1977).
Word, object and conceptual development.
W. W. Norton.
[ bib ]
Annett, M. (1959).
The classification of instances of four common class concepts by
children and adults.
British Journal of Educational Psychology, 29:223--236.
[ bib ]
Anscombe, G. E. M. (1957).
Intention.
Oxford: Basil Blackwell, 2nd edition.
[ bib ]
Apostle, H. (1980).
Aristotle's categories and propositions (de interpretatione).
Peripatetic Press.
[ bib ]
Armstrong, S., Gleitman, L., and Gleitman, H. (1983a).
What some concepts might not be.
Cognition, 13:263--308.
[ bib ]
Armstrong, S. L., Gleitman, L. R., and Gleitman, H. (1983b).
What some concepts might not be.
Cognition, 13:263--308.
[ bib ]
Ashby, F., Alfonso-Reese, L., Turken, A., and Waldron, E. (1998).
A neuropsychological theory of multiple systems in category learning.
Psychological Review, 105:442--481.
[ bib ]
Ashby, F. and Maddox, W. (1993a).
Relations between exemplar, prototype, and decision bound models of
categorization.
Journal of Mathematical Psychology, 37:372--400.
[ bib ]
Ashby, F. G. and Gott, R. E. (1988).
Decision rules in the perception and categorization of
multidimensional stimuli.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 14:33--53.
[ bib ]
Ashby, F. G. and Maddox, W. T. (1993b).
Relations between prototype, exemplar, and decision bound models of
categorization.
Journal of Mathematical Psychology, 37:372--400.
[ bib ]
Ashby, F. G. and Perrin, N. A. (1988).
Toward a unified theory of similarity and recognition.
Psychological Review, 95:124--150.
[ bib ]
Atran, S. (1998).
Folkbiology and the anthropology of science: Cognitive universals and
cultural particulars.
Behavioral and Brain Sciences, 21:547 -- 609.
[ bib ]
Atran, S., Estin, P, Coley, D, J., Medin, and L, D. (1997).
Generic species and basic levels: Essence and appearance in folk
biology.
Journal of Ethnobiology, 17(1):22 -- 45.
[ bib ]
Au, T. (1983).
Chinese and english counterfactuals: The sapir-whorf hypothesis
revisited.
Cognition, 15:155--187.
[ bib ]
Austin, J. T. and Vancouver, J. B. (1996).
Goal constructs in psychology: Structure, process, and content.
Psychological Bulletin, 120:338--375.
[ bib ]
Bailenson, J. N., Shum, M. S., Atran, S., Medin, D. L., and Coley, J. D.
(2002).
A bird's eye view: biological categorization and reasoning within and
across cultures.
Cognition, 84(1):1--53.
[ bib |
http ]
Many psychological studies of categorization and reasoning use undergraduates
to make claims about human conceptualization. Generalizability of
findings to other populations is often assumed but rarely tested.
Even when comparative studies are conducted, it may be challenging
to interpret differences. As a partial remedy, in the present studies
we adopt a 'triangulation strategy' to evaluate the ways expertise
and culturally different belief systems can lead to different ways
of conceptualizing the biological world. We use three groups (US
bird experts, US undergraduates, and ordinary Itza' Maya) and two
sets of birds (North American and Central American). Categorization
tasks show considerable similarity among the three groups' taxonomic
sorts, but also systematic differences. Notably, US expert categorization
is more similar to Itza' than to US novice categorization. The differences
are magnified on inductive reasoning tasks where only undergraduates
show patterns of judgment that are largely consistent with current
models of category-based taxonomic inference. The Maya commonly employ
causal and ecological reasoning rather than taxonomic reasoning.
Experts use a mixture of strategies (including causal and ecological
reasoning), only some of which current models explain. US and Itza'
informants differed markedly when reasoning about passerines (songbirds),
reflecting the somewhat different role that songbirds play in the
two cultures. The results call into question the importance of similarity-based
notions of typicality and central tendency in natural categorization
and reasoning. These findings also show that relative expertise leads
to a convergence of thought that transcends cultural boundaries and
shared experiences
Keywords: Human, Inference, Judgment
Baillargeon, R. (1998).
Infants' understanding of the physical world, pages 503--529.
Psychology Press.
[ bib ]
Baillargeon, R., Spelke, E., and Wasserman, S. (1985).
Object permanence in five-month-old infants.
Cognition, 20:191--208.
[ bib ]
Baker, F. and Kim, S. H. (2004).
Item response theory.
Marcel Dekker, New York, NY.
[ bib ]
Baldwin, D., Markman, E., and Melartin, R. (1993).
Infants' ability to draw inferences about nonobvious object
properties: Evidence from exploratory play.
Child Development, 64:711--728.
[ bib ]
Barnette, J. J. (2000).
Effects of stem and Likert response option reversals on survey
internal consistency: If you feel the need, there is a better alternative
to using those negatively worded stems.
Educational and Psychological Measurement, 60:361--370.
[ bib ]
Barr, R. and Caplan, L. (1987).
Category representations and their implications for category
structure.
Memory & Cognition, 15:397--418.
[ bib ]
Barrett, J. L. and Keil, F. C. (1996).
Conceptualizing a nonnatural entity: Anthropomorphism in god
concepts.
Cognitive Psychology, 31(3):219--247.
[ bib |
http ]
We investigate the problem of how nonnatural entities are represented
by examining university students' concepts of God, both professed
theological beliefs and concepts used in comprehension of narratives.
In three story processing tasks, subjects often used an anthropomorphic
God concept that is inconsistent with stated theological beliefs;
and drastically distorted the narratives without any awareness of
doing so. By heightening subjects' awareness of their theological
beliefs, we were able to manipulate the degree of anthropomorphization.
This tendency to anthropomorphize may be generalizable to other agents.
God (and possibly other agents) is unintentionally anthropomorphized
in some contexts, perhaps as a means of representing poorly understood
nonnatural entities
Keywords: Concepts
Barrett, S., Abdi, H., Murphy, G., and Gallagher, J. (1993).
Theory-based correlations and their role in children's concepts.
Child Development, 64:1595--1616.
[ bib ]
Barsalou, L. (1990).
On the indistinguishability of exemplar memory and abstraction
in category representation, pages 61--88.
Erlbaum.
[ bib ]
Barsalou, L. (1999).
Perceptual symbol systems.
Behavioral and Brain Sciences, 22:577--660.
[ bib ]
Barsalou, L., Huttenlocher, J., and Lamberts, K. (1998).
Basing categorization on individuals and events.
Cognitive Psychology, 36:203--272.
[ bib ]
Barsalou, L. W. (1982).
Context-independent and context-dependent information in concepts.
Memory & Cognition, 10:82--93.
[ bib ]
Keywords: Concepts
Barsalou, L. W. (1983).
Ad hoc categories.
Memory & Cognition, 11:211--227.
[ bib ]
Barsalou, L. W. (1985).
Ideals, central tendency, and frequency of instantiation as
determinants of graded structure in categories.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 11:629--654.
[ bib ]
Barsalou, L. W. (1987).
The instability of graded structure: Implications for the nature of
concepts.
In Neisser, U., editor, Concepts and conceptual development:
Ecological and intellectual factors in categorization, chapter The
instability of graded structure: Implications for the nature of concepts,
pages 101--140. Cambridge University Press, New York, NY.
[ bib ]
Barsalou, L. W. (1991).
Deriving categories to achieve goals.
In Bower, G. H., editor, The psychology of learning and
motivation: Advances in research and theory, volume 27, chapter Deriving
categories to achieve goals, pages 1--64. Academic Press, San Diego, CA.
[ bib ]
Barsalou, L. W. (1993).
Flexibility, structure, and linguistic vagary in concepts:
Manifestations of a compositional system of perceptual symbols.
In Collins, A. F., Gathercole, S. E., Conway, M. A., and Morris,
P. E., editors, Theories of memory, chapter Flexibility, structure, and
linguistic vagary in concepts: Manifestations of a compositional system of
perceptual symbols, pages 29--101. Lawrence Erlbaum Associates, East Sussex,
UK.
[ bib ]
Barsalou, L. W. (2003).
Situated simulation in the human conceptual system.
Language and Cognitive Processes, 18:513--562.
[ bib ]
Barsalou, L. W. (2010).
Ad hoc categories.
In Hogan, P. C., editor, The Cambridge encyclopedia of the
language sciences, chapter Ad hoc categories, pages 87--88. Cambridge
University Press, New York, NY.
[ bib ]
Barsalou, L. W. and Sewell, D. R. (1984).
Constructing representations of categories from different points of
view.
Emory Cognition Project Report #2, Emory University, Atlanta, GA.
[ bib ]
Barsalou, L. W. and Wiemer-Hastings, K. (2005).
Situating abstract concepts.
In Pecher, D. and Zwaan, R., editors, Grounding cognition: The
role of perception and action in memory, language, and thought, chapter
Situating abstract concepts, pages 129--163. Cambridge University Press, New
York.
[ bib ]
Bartlema, A., Lee, M. D., Wetzels, R., and Vanpaemel, W. (2014).
A Bayesian hierarchical mixture approach to individual differences:
Case studies in selective attention and representation in category
learning.
Journal of Mathematical Psychology, 59:132--150.
[ bib ]
Bassok, M. and Medin, D. L. (1997).
Birds of a feather flock together: Similarity judgments with
semantically rich stimuli.
Journal of Memory and Language, 36(3):311--336.
[ bib |
http ]
The structural-alignment approach to similarity posits a principled
distinction between object attributes and relations between objects.
We examined whether this assumption holds for nonarbitrary combinations
of interrelated objects. Subjects judged similarity between simple
statements in which the nouns (denoting attributes) and verbs (denoting
relations) were semantically interdependent. We found that semantic
dependencies affected similarity judgments both by inducing inferences
about the abstract combined meaning of the statements and by changing
the process by which subjects arrived at their judgments. When the
paired statements had matching verbs (e.g., "The carpenter fixed
the chair" and "The electrician fixed the radio"), subjectscomparedthe
combined meanings of the statements (e.g., "Similar because both
are professionals doing their job"). These results are consistent
with the logic of structural alignment. However, when the paired
statements had matching nouns (e.g., "The carpenter fixed the chair"
and "The carpenter sat on the chair"), very often subjectsintegratedthe
combined meanings of the statements (e.g., "Similar because he sat
on the chair to see whether he fixed it well"). These results defy
every existing account of similarity. We discuss the prevalence and
systematicity of such processing replacements and the need for incorporating
them into similarity-based accounts of cognition
Keywords: Cognition, Inference, Judgment, Logic, Meaning
Battig, W. and Montague, W. (1969).
Category norms for verbal items in 56 categories: A replication and
extension of the connecticut category norms.
Journal of Experimental Psychology Monograph, 80 (3, part
2):--.
[ bib ]
Bauer, P., Dow, G., and Hertsgaard, L. (1995).
Effects of prototypicality on categorization in 1- to 2-year-olds:
Getting down to basic.
Cognitive Development, 10:43--68.
[ bib ]
Beale, J. M. and Keil, F. C. (1995).
Categorical effects in the perception of faces.
Cognition, 57(3):217--239.
[ bib |
http ]
These studies suggest categorical perception effects may be much more
general than has commonly been believed and can occur in apparently
similar ways at dramatically different levels of processing. To test
the nature of individual face representations, a linear continuum
of "morphed" faces was generated between individual exemplars of
familiar faces. In separate categorization, discrimination and "better-likeness"
tasks, subjects viewed pairs of faces from these continua. Subjects
discriminate most accurately when face-pairs straddle apparent category
boundaries; thus individual faces are perceived categorically. A
high correlation is found between the familiarity of a face-pair
and the magnitude of the categorization effect. Categorical perception
therefore is not limited to low-level perceptual continua, but can
occur at higher levels and may be acquired through experience as
well
Keywords: Perception
Becker, A. and Ward, T. (1991).
Children's use of shape in extending novel labels to animate objects:
Identity versus postural change.
Cognitive Development, 6:3--16.
[ bib ]
Behl-Chadha, G. (1996).
Basic-level and superordinate-like categorical representation in
early infancy.
Cognition, 60:105--141.
[ bib ]
Berlin, B. (1992).
Ethnobiological classification: Principles of categorization of
plants and animals in traditional societies. CY - Princeton, NJ.
Princeton University Press.
[ bib ]
Berlin, B., Breedlove, D., and Raven, P. (1973).
General principles of classification and nomenclature in folk
biology.
American Anthropologist, 75:214--242.
[ bib ]
Berlin, B. and Kay, P. (1969).
Basic color terms: Their universality and evolution.
University of California Press, Berkeley, CA.
[ bib ]
Billman, D. and Knutson, J. (1996).
Unsupervised concept learning and value systematicity: A complex
whole aids learning the parts.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 22:458--475.
[ bib ]
Birnbaum, A. (1968).
Some latent trait models.
In Ford, F. M. and Novick, M. R., editors, Statistical theories
of mental test scores, chapter Some latent trait models, pages 397--424.
Addison-Wesley, Reading, MA.
[ bib ]
Bjorklund, D. and Thompson, B. (1983).
Category typicality effects in children's memory performance:
Qualitative and quantitative differences in the processing of category
information.
Journal of Experimental Child Psychology, 35:329--344.
[ bib ]
Bjorklund, D. F., Thompson, B. E., and Ornstein, P. A. (1983).
Developmental trends in children's typicality judgments.
Behavior Research Methods & Instrumentation, 15:350--356.
[ bib ]
Black, M. (1937).
Vagueness: An exercise in logical analysis.
Philosophy of Science, 4:427--455.
[ bib ]
Blair, M. and Homa, D. (2001).
Expanding the search for a linear separability constraint on category
learning.
Memory & Cognition, 29:1153--1164.
[ bib ]
Blewitt, P. (1983).
Dog versus collie: Vocabulary in speech to young children.
Developmental Psychology, 19:602--609.
[ bib ]
Blewitt, P. (1994).
Understanding categorical hierarchies: The earliest levels of skill.
Child Development, 65:1279--1298.
[ bib ]
Block, N. and Fodor, J. (1972).
What psychological states are not.
Philosophical Review, 81:159--181.
[ bib ]
Keywords: BEHAVIORISM, EPISTEMOLOGY, MIND, PHYSICALISM, PSYCHOLOGY, STATE
Bloom, P. (1996).
Intention, history, and artifact concepts.
Cognition, 60:1--29.
[ bib ]
Bloom, P. (1998).
Theories of artifact categorization.
Cognition, 66:87 -- 93.
[ bib ]
Bloom, P. (2000a).
How children learn the meanings of words.
MIT Press.
[ bib ]
Bloom, P. (2000b).
Roots of word learning.
[ bib ]
Bloom, P. and Markson, L. (1998).
Capacities underlying word learning.
Trends in Cognitive Science, 2:67--73.
[ bib ]
Bomba, P. and Siqueland, E. (1983).
The nature and structure of infant form categories.
Journal of Experimental Child Psychology, 35:294--328.
[ bib ]
Bond, T. G. and Fox, C. M. (2007a).
Basic principles of the rasch model.
In Applying the Rasch model: Fundamental measurement in the
human sciences, chapter Basic principles of the Rasch model, pages 29--48.
Lawrence Erlbaum, Mahwah, NJ.
[ bib ]
Bond, T. G. and Fox, C. M. (2007b).
Development, education, and rehabilitation: Change over time.
In Applying the Rasch model: Fundamental measurement in the
human sciences, chapter Development, education, and rehabilitation: Change
over time, pages 163--182. Lawrence Erlbaum, Mahwah, NJ.
[ bib ]
Bonnefon, J.-F., Eid, M., Vautier, S., and Jmel, S. (2008).
A mixed rasch model of dual-process conditional reasoning.
The Quarterly Journal of Experimental Psychology, 61:809--824.
[ bib ]
Borkenau, P. (1991).
Proximity to central tendency and usefulness in attaining goals as
predictors of prototypicality for behaviour-descriptive categories.
European Journal of Personality, 5:71--78.
[ bib ]
Boster, J. and Johnson, J. (1989).
Form or function: A comparison of expert and novice judgments of
similarity among fish.
American Anthropologist, 91:866--889.
[ bib ]
Bowerman, M. (1996).
The origins of children's spacial semantic categories: Cognitive
versus linguistic determinants, pages 145--176.
Cambridge University Press.
[ bib ]
Boyd, R. (1999).
Homeostasis, species, and higher taxa, pages 141--185.
MIT Press.
[ bib ]
Braeken, J. and Tuerlinckx, F. (2009).
Investigating latent constructs with item response models: A
MATLAB IRTm toolbox.
Behavior Research Methods, 41:1127--1137.
[ bib ]
Braisby, N., Franks, B., and Hampton, J. A. (1996).
Essentialism, word use, and concepts.
Cognition, 59:247--274.
[ bib ]
Keywords: Concepts, Essentialism
Braisby, N. R. (1993).
Stable concepts and context-sensitive classification.
Irish Journal of Psychology, 14:426--441.
[ bib ]
Braisby, N. R. (2005).
Perspectives, compositionality, and complex concepts.
In Machery, E., Werning, M., and Schurz, G., editors, The
compositionality of meaning and content (Vol. II: Applications to
Linguistics, Psychology and Neuroscience), chapter Perspectives,
compositionality, and complex concepts, pages 179--202. Ontos Verlag,
Frankfurt, DE.
[ bib ]
Bransford, J., Barclay, J., and Franks, J. (1972).
Sentence memory: A constructive versus interpretive approach.
Cognitive Psychology, 3:193--209.
[ bib ]
Brem, S. K. and Rips, L. J. (2000).
Explanation and evidence in informal argument.
Cognitive Science, 24:573 -- 604.
[ bib ]
Brewer, W. F., Chinn, C. A., and Samarapungavan, A. (1998).
Explanation in scientists and children.
Minds and Machines, 8(1): 119-136):--136.
[ bib ]
Keywords: EXPLANATION
Brewer, W. F., Chinn, C. A., and Samarapungavan, A. (2000).
Explanation in scientists and children.
In Keil, F. and Wilson, R., editors, Explanation and Cognition,
chapter 11, pages 279--298. MIT, Cambridge, Massachusetts.
[ bib ]
(from the chapter) In examining explanations as used by scientists
and by children, this chapter provides a psychological account of
the nature of explanation and the criteria people use to evaluate
the quality of explanations. The authors first discuss explanation
in everyday and scientific use, then analyze the criteria used by
nonscientists and scientists to evaluate explanations, describing
the types of explanations commonly used by nonscientists and scientists.
Finally, the authors use the framework they have developed to discuss
the development of explanation in children. (PsycINFO Database Record
(c) 2003 APA, all rights reserved)
Keywords: *Interpersonal Communication, *Reasoning, *Scientific Communication,
*Scientists, Adulthood (18 yrs & older), Childhood (birth-12 yrs),
Cognition, Explanation, Human, psychological account of nature &
quality of explanations as used by scientists & children in everyday
& scientific use, PSYCHOLOGY, Psychology: Professional & Research.,
Social Psychology [3000]; Cognitive Processes [2340].
Bröder, A. (2003).
Decision making with the “adaptive toolbox": Influence of
environmental structure, intelligence, and working memory load.
Journal of Experimental Psychololgy: Learning, Memory, and
Cognition, 29:611--625.
[ bib ]
Bröder, A. and Newell, B. R. (2008).
Challenging some common beliefs: Empirical work within the adaptive
toolbox metaphor.
Judgment and Decision Making, 3:205--214.
[ bib ]
Bröder, A. and Schiffer, S. (2003).
Take-the-best versus simultaneous feature matching: Probabilistic
inferences from memory and the effects of representation format.
Journal of Experimental Psychology: General, 132:277--293.
[ bib ]
Brooks, L. (1987).
Decentralized control of categorization: The role of prior
processing episodes, pages 141--174.
Cambridge University Press.
[ bib ]
Brooks, L., Norman, G., and Allen, S. (1991).
Role of specific similarity in a medical diagnosis task.
Journal of Experimental Psychology: General, 120:278--287.
[ bib ]
Brown, R. (1958a).
How shall a thing be called?
Psychological Review, 65:14--21.
[ bib ]
Brown, R. (1958b).
Words and things.
The Free Press.
[ bib ]
Bruner, J., Goodnow, J., and Austin, G. (1956).
A study of thinking.
Wiley.
[ bib ]
Burgess, C., Livesay, K., and Lund, K. (1998).
Explorations in context space: Words, sentences, discourse.
Discourse Processes, 25:211--257.
[ bib ]
Burnett, R. C., Medin, D. L., Ross, N. O., and Blok, S. V. (2005).
Ideal is typical.
Canadian Journal of Experimental Psychology, 59:3--10.
[ bib ]
Callanan, M. (1985).
How parents label objects for young children: The role of input in
the acquisition of category hierarchies.
Child Development, 56:508--523.
[ bib ]
Callanan, M. (1989).
Development of object categories and inclusion relations:
Preschoolers' hypotheses about word meanings.
Developmental Psychology, 25:207--216.
[ bib ]
Callanan, M. (1990).
Parent's descriptions of objects: Potential data for children's
inferences about category principles.
Cognitive Development, 5:101--122.
[ bib ]
Callanan, M. and Markman, E. (1982).
Principles of organization in young children's natural language
hierarchies.
Child Development, 53:1093--1101.
[ bib ]
Cantor, N. and Mischel, W. (1979).
Prototypes in person perception, pages 3--52.
Academic Press.
[ bib ]
Cantor, N., Smith, E., French, R., and Mezzich, J. (1980).
Psychiatric diagnosis as prototype categorization.
Journal of Abnormal Psychology, 89:181--193.
[ bib ]
Carabine, B. (1991).
Fuzzy boundaries and the extension of object-words.
Journal of Child Language, 18:355--372.
[ bib ]
Caramazza, A. and Grober, E. (1976).
Polysemy and the structure of the subjective lexicon.
In Rameh, C., editor, Semantics: Theory and application.
Georgetown University Round Table on languages and linguistics,
chapter Polysemy and the structure of the subjective lexicon, pages 181--206.
Georgetown University Press, Washington, DC.
[ bib ]
Carey, S. (1978).
The child as word learner, pages 264--293.
MIT Press.
[ bib ]
Carey, S. (1982).
Semantic development: The state of the art, pages 347--389.
Cambridge University Press.
[ bib ]
Carey, S. (1985).
Conceptual change in childhood.
MIT Press.
[ bib ]
Cartwright, N. (2004).
From causation to explanation and back.
In Leiter, B., editor, The Future for Philosophy, pages 230 --
245. Oxford University Press, Oxford, UK.
[ bib ]
Casey, P. (1992).
A reexamination of the roles of typicality and category dominance in
verifying category membership.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 18:823--834.
[ bib ]
Casler, K. and Kelemen, D. (2007).
Reasoning about artifacts at 24 months: The developing
teleo-functional stance.
Cognition, 103(1):120 -- 130.
[ bib |
DOI ]
Ceulemans, E. and Storms, G. (2010).
Detecting intra and inter categorical structure in semantic concepts
using HICLAS.
Acta Psychologica, 133:296--304.
[ bib ]
Chang, T. (1986).
Semantic memory: Facts and models.
Psychological Bulletin, 99:199--220.
[ bib ]
Cheng, P. W. (1997).
From covariation to causation: A causal power theory.
Psychological Review, 104(2):367--405.
[ bib ]
(from the journal abstract) Because causal relations are neither observable
nor deducible, they must be induced from observable events. The 2
dominant approaches to the psychology of causal induction--the covariation
approach and the causal power approach--are each crippled by fundamental
problems. This article proposes an integration of these approaches
that overcomes these problems. The proposal is that reasoners innately
treat the relation between covariation (a function defined in terms
of observable events) and causal power (an unobservable entity) as
that between scientists' law or model and their theory explaining
the model. This solution is formalized in the power PC theory, a
causal power theory of the probabilistic contrast model (P. W. Cheng
& L. R. Novick, 1990). The article reviews diverse old and new empirical
tests discriminating this theory from previous models, none of which
is justified by a theory. The results uniquely support the power
PC theory. (PsycINFO Database Record (c) 2003 APA, all rights reserved)
Keywords: *Analysis of Covariance, *Causal Analysis, *Theories, Causation, Human,
integration of covariation & causation in causal power theory, Models,
Power, probabilistic contrast model, PSYCHOLOGY, Statistics & Mathematics
[2240].
Cheng, P. W. and Lien, Y. (1995).
The role of coherence in differentiating genuine from spurious
causes, pages 463--494.
Oxford University Press.
[ bib ]
(from the chapter) illustrated the top-down influence of superordinate
causal knowledge / even when conditional contrasts cannot be computed,
people are able to make a systematic distinction between a genuine
cause and a spurious cause / according to the power view, a statistical
relevance relation is judged as causal if one knows of an underlying
power or mechanism / proposed that an underlying power means a causal
relation that implies a relevance relation at a more abstract level
than the target relevance relation; when the target relation is consistent
with the more abstract contrast it will be accepted as causal, but
when it is not consistent with any such contrast it will be less
likely to be accepted as causal /// the primary task in this experiment
was to judge whether or not a target relevance relation is causal
[in a categorization task] / [participants were] 96 undergraduate
students /// [this chapter includes a discussion among F. Keil, M.
Morris, P. Cheng and Y. Lien] (PsycINFO Database Record (c) 2003
APA, all rights reserved)
Keywords: *Causal Analysis, *Knowledge Level, *Statistical Correlation, Adulthood
(18 yrs & older), Classification (Cognitive Process), Cognition,
Cognitive Processes [2340]., college students, Empirical Study, Human,
Knowledge, Power, PSYCHOLOGY, Psychology: Professional & Research.,
subordinate causal knowledge & power & role of coherence in differentiating
genuine from spurious causes in statistically relevant relations
in categorization task
Cheng, P. W. and Novick, L. R. (1990).
A probabilistic contrast model of causal induction.
Journal of Personality & Social Psychology, 58(4):545--567.
[ bib ]
Deviations from the predictions of covariational models of causal
attribution have often been reported in the literature. These include
a bias against using a consensus information, a bias toward attributing
effects to a person, and a tendency to make a variety of unpredicted
conjunctive attributions. It is contended that these deviations,
rather than representing irrational biases, could be due to (a) unspecified
information over which causal inferences are computed and (b) the
questionable normativeness of the models against which these deviations
have been measured. A probabilistic extension of Kelley's analysis-of-variance
analogy is proposed. An experiment was performed to assess the above
biases and evaluate the proposed model against competing ones. The
results indicate that the inference process is unbiased. (PsycINFO
Database Record (c) 2003 APA, all rights reserved)
Keywords: *Attribution, *Inference, *Statistical Probability, Attribution, causal
attribution, Human, Induction, Inference, Information, Models, probabilistic
contrast model, probabilistic contrast model of causal inference,
PSYCHOLOGY, Social Perception & Cognition [3040].
Cheng, P. W. and Novick, L. R. (1992).
Covariation in natural causal induction.
Psychological Review, 99(2):365--382.
[ bib ]
The covariation component of everyday causal inference has been depicted,
in both cognitive and social psychology as well as in philosophy,
as heterogeneous and prone to biases. The models and biases discussed
in these domains are analyzed with respect to focal sets: contextually
determined sets of events over which covariation is computed. Moreover,
these models are compared to our probabilistic contrast model, which
specifies causes as first and higher order contrasts computed over
events in a focal set. Contrary to the previous depiction of covariation
computation, the present assessment indicates that a single normative
mechanism-the computation of probabilistic contrasts-underlies this
essential component of natural causal induction both in everyday
and in scientific situations.
Chi, M., Feltovich, P., and Glaser, R. (1981).
Categorization and representation of physics problems by experts and
novices.
Cognitive Science, 5:121--152.
[ bib ]
Chi, M., Hutchinson, J., and Robin, A. (1989).
How inferences about novel domain-related concepts can be constrained
by structured knowledge.
Merrill-Palmer Quarterly, 35:27--62.
[ bib ]
Chierchia, G. and McConnell-Ginet, S. (1990).
Meaning and grammar: An introduction to semantics.
MIT Press.
[ bib ]
Chinn, C. A. and Brewer, W. F. (2001).
Models of data: A theory of how people evaluate data. [references].
Cognition and Instruction, 19(3):323--393.
[ bib ]
Reports the results of a study investigating how undergraduates evaluate
realistic scientific data in the domains of geology and paleontology.
The results are used to test several predictions of a theory of data
evaluation, which the authors call models-of-data theory. Models-of-data
theory assumes that when evaluating data, the individual constructs
a particular kind of cognitive model that integrates many features
of the data with a theoretical interpretation of the data. The individual
evaluates the model by attempting to generate alternative causal
explanations for the events in the model. Models-of-data theory are
contrasted with other proposals for how data are cognitively represented
and it is shown that models-of-data theory gives a good account of
the pattern of written evaluations of data produced by the undergraduates
in the study. Theoretical and instructional implications of the theory
are discussed. (PsycINFO Database Record (c) 2003 APA, all rights
reserved)
Cho, S.-J., Cohen, A. S., and Kim, S.-H. (2013).
Markov chain Monte Carlo estimation of a mixture item response
theory model.
Journal of Statistical Computation and Simulation, 83:278--306.
[ bib ]
Chomsky, N. (1959).
Review of skinner's verbal behavior.
Language, 35:26--58.
[ bib ]
Church, B. and Schachter, D. (1994).
Perceptual specificity of auditory priming: Implicit memory for voice
intonation and fundamental frequency.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 20:521--533.
[ bib ]
Clark, A. (1998).
Twisted tales: Causal complexity and cognitive scientific
explanation.
Minds and Machines, 8(1): 79-99):--99.
[ bib ]
Keywords: EXPLANATION
Clark, E. (1983a).
Meaning and concepts, pages 787--840.
Wiley.
[ bib ]
Clark, E. (1993).
The lexicon in acquisition.
Cambridge University Press.
[ bib ]
Clark, E. and Clark, H. (1979).
When nouns surface as verbs.
Language, 55:767--811.
[ bib ]
Clark, E. V. (1973).
What�s in a word? On the child`s acquisition of semantics in his
first language.
In Moore, T. E., editor, Cognitive development and the
acquisition of language, chapter What�s in a word? On the child�s
acquisition of semantics in his first language., pages 65--110. Academic
Press, New York, NY.
[ bib ]
Clark, H. (1974).
Semantics and comprehension.
Mouton.
[ bib ]
Clark, H. (1983b).
Making sense of nonce sense, pages 297--331.
John Wiley.
[ bib ]
Clark, H. (1991).
Words, the world, and their possibilities, pages --.
American Psychological Association.
[ bib ]
Clark, H. (1996).
Using language.
Cambridge University Press.
[ bib ]
Clark, H. and Clark, E. (1977).
Psychology and language.
Harcourt Brace Jovanovich.
[ bib ]
Clark, H. and Wilkes-Gibbs, D. (1986).
Referring as a collaborative process.
Cognition, 22:1--39.
[ bib ]
Cohen, B. and Murphy, G. (1984).
Models of concepts.
Cognitive Science, 8:27--58.
[ bib ]
Cohen, J. D. and Servan-Schreiber, D. (1992).
Context, cortex, and dopamine: A connectionist approach to behavior
and biology in schizophrenia.
Psychological Review, 99:45--77.
[ bib ]
Coleman, L. and Kay, P. (1981).
Prototype semantics: The english word lie.
Language, 57:26--44.
[ bib ]
Coley, J., Medin, D., and Atran, S. (1997).
Does rank have its privilege? inductive inferences within
folkbiological taxonomies.
Cognition, 64(1):73--112.
[ bib |
http ]
Keywords: Inference
Collins, A. and Loftus, E. (1975).
A spreading-activation theory of semantic processing.
Psychological Review, 82:407--428.
[ bib ]
Collins, A. and Quillian, M. (1969).
Retrieval time from semantic memory.
Journal of Verbal Learning and Verbal Behavior, 8:241--248.
[ bib ]
Collins, A. and Quillian, M. (1970).
Does category size affect categorization time?
Journal of Verbal Learning and Verbal Behavior, 9:432--438.
[ bib ]
Conrad, C. (1972).
Cognitive economy in semantic memory.
Journal of Experimental Psychology, 92:149--154.
[ bib ]
Corneille, O., Goldstone, R. L., Queller, S., and Potter, T. (2006).
Asymmetries in categorization, perceptual discrimination, and visual
search for reference and nonreference exemplars.
Memory & Cognition, 34:556--567.
[ bib ]
Corter, J. and Gluck, M. (1992).
Explaining basic categories: Feature predictability and information.
Psychological Bulletin, 111:291--303.
[ bib ]
Craig, S. and Lewandowsky, S. (2012).
Whichever way you choose to categorize, working memory helps you
learn.
Quarterly Journal of Experimental Psychology, 65:439--464.
[ bib ]
Cree, G. and McRae, K. (2003).
Analyzing the factors underlying the structure and computation of the
meaning of chipmunk, cherry, chisel, cheese, and cello (and many other such
concrete nouns).
Journal of Experimental Psychology: General, 132:163--201.
[ bib ]
Croft, W. (1991).
Categories and grammatical relations: The cognitive organization
of information.
University of Chicago Press.
[ bib ]
Cruse, D. (1977).
The pragmatics of lexical specificity.
Journal of Linguistics, 13:153--164.
[ bib ]
Cruse, D. (1986).
Lexical semantics.
Cambridge University Press.
[ bib ]
Cruse, D. (2000).
Aspects of the micro-structure of word meanings.
In Ravin, Y. and Leacock, C., editors, Polysemy: Theoretical and
computational approaches, pages 30--51. Oxford University Press, New York,
NY.
[ bib ]
Cruse, D. (2001).
Microsenses, default specificity and the semantics-pragmatics
boundary.
Axiomathes, 12:35--54.
[ bib ]
Crutch, S. J. and Warrington, E. K. (2005).
Abstract and concrete concepts have structurally different
representational frameworks.
Brain, 128:615--627.
[ bib ]
Cummins, R. (1975).
Functional analysis.
The Journal of Philosophy, 72(20):741--765.
[ bib ]
Cummins, R. (2000).
How does it work? versus "what are the laws?: Two conceptions of
psychological explanation.
In Keil, F. and Wilson, R., editors, Explanation and Cognition,
chapter 5, pages 255--276. MIT, Cambridge, Massachusetts.
[ bib ]
(from the chapter) This chapter discusses why some features of concepts
are more central than others. The authors begin with a review of
possible determinants of feature centrality, then focus on one important
determinant, the effects of causal background knowledge on feature
centrality. The different approaches to understanding feature centrality
(content-based, statistical, and theory-based) are addressed, then
a general introduction is made to the Causal Status hypothesis. The
authors present their rationale for predicting the causal status
effect and empirical results supporting the hypothesis under various
contexts. They describe previous categorization studies that can
be accounted for by this hypothesis, and discuss moderating factors
for the effect. Finally, they examine the potential consequences
of focusing only on causal relations among features in study the
effect of lay theories on feature centrality. (PsycINFO Database
Record (c) 2003 APA, all rights reserved)
Dahr, H. E. and Fort, F. (2008).
Effect of goal salience and goal conflict on typicality: The case
of health food.
Advances in Consumer Research, 35:282--288.
[ bib ]
Dale, R., Kehoe, C., and Spivey, M. (2007).
Graded motor responses in the time course of categorizing atypical
exemplars.
Memory & Cognition, 35:15--28.
[ bib ]
Davidson, D. (1963).
Actions, reasons, causes.
Journal of Philosophy, 60(63):685 -- 700.
[ bib ]
Davidson, D. (1980).
Essays on Actions and Events, Second Edition.
Clarendon Oxford Pr.
[ bib ]
Donald Davidson has prepared a new edition of his classic 1980 collection
of Essays on Actions and Events, including two additional essays.
In this seminal investigation of the nature of human action, Davidson
argues for an ontology which includes events along with persons and
other objects. Certain events are identified and explained as actions
when they are viewed as caused and rationalized by reasons; these
same events, when described in physical, biological, or physiological
terms, may be explained by appeal to natural laws. The mental and
the physical thus constitute irreducibly discrete ways of explaining
and understanding events and their causal relations. (publisher,
edited)
Keywords: action, cause, epistemology, event, intention, mental-event; metaphysics,
mind
Davidson, D. (1986/1970).
Events as particulars.
In Actions & Events, pages 181--187. Oxford University
Press, Oxford, UK.
[ bib ]
TWO PROBLEMS ABOUT EVENTS ARE (1) TO GIVE A PLAUSIBLE ACCOUNT OF SENTENCES
THAT SAY, OR SEEM TO SAY, THAT ONE AND THE SAME EVENT OCCURRED MORE
THAN ONCE, AND (2) TO GIVE AN ANALYSIS OF SENTENCES LIKE 'HE DID
IT IN THE ATTIC' THAT VALIDATE THE INFERENCE TO 'HE DID IT.' RODERICK
CHISHOLM (IN "EVENTS AND PROPOSITIONS," THIS ISSUE OF 'NOUS') PROPOSES
A NEW ANALYSIS OF EVENTS TO DEAL WITH PROBLEM (1), AND CLAIMS THAT
THE THEORY OF THE AUTHOR ("ON THE LOGICAL FORM OF ACTION SENTENCES,"
IN 'THE LOGIC OF DECISION AND ACTION,' N. RESCHER (ED.), PITTSBURGH,
1967) CAN NOT DO AS WELL. THE AUTHOR DISPUTES THIS CLAIM, AND ARGUES
THAT CHISHOLM'S THEORY, UNLIKE HIS OWN, HAS NOT BEEN SHOWN CAPABLE
OF DEALING WITH PROBLEM (2).
Davis, T. and Love, B. C. (2010).
Memory for category information is idealized through contrast with
competing options.
Psychological Science, 21:234--242.
[ bib ]
De Boeck, P. (2008).
Random item IRT models.
Psychometrika, 73:533--559.
[ bib ]
De Boeck, P. and Rosenberg, S. (1988).
Hierarchical classes: Model and data analysis.
Psychometrika, 53:361--381.
[ bib ]
De Boeck, P. and Wilson, M. (2004).
Explanatory item response models: A generalized linear and
nonlinear approach.
Springer, New York, NY.
[ bib ]
De Deyne, S. (2008).
Proximity in semantic vector space.
PhD thesis, University of Leuven.
[ bib ]
De Deyne, S., Peirsman, Y., and Storms, G. (2009).
Sources of semantic similarity.
In Taatgen, N. A. and van Rijn, H., editors, Proceedings of
the 31st Annual Conference of the Cognitive Science Society,
chapter Sources of semantic similarity, pages 1834--1839. Cognitive Science
Society, Austin, TX.
[ bib ]
De Deyne, S., Verheyen, S., Ameel, E., Vanpaemel, W., Dry, M. J., Voorspoels,
W., and Storms, G. (2008).
Exemplar by feature applicability matrices and other Dutch
normative data for semantic concepts.
Behavior Research Methods, 40:1030--1048.
[ bib ]
Deci, E. L. and Ryan, R. M. (1985).
Intrinsic motivation and self-determination in human behavior.
Plenum, New York, NY.
[ bib ]
DeJong, G. and Mooney, R. (1986).
Explanation-based learning: An alternative view.
Machine Learning, 1:145--176.
[ bib ]
Dennett, D. C. (1987).
The intentional stance.
MIT, Cambridge, MA.
[ bib ]
DeSarbo, W. S., Johnson, M. D., Manrai, A. K., Manrai, L. A., and Edwards,
E. A. (1992).
TSCALE: A new multidimensional scaling procedure based on
Tversky's contrast model.
Psychometrika, 57:43--69.
[ bib ]
Dewberry, C., Juanchich, M., and Narendran, S. (2013).
Decision-making competence in everyday life: The roles of general
cognitive styles, decision-making styles and personality.
Personality and Individual Differences, 55:783--788.
[ bib ]
Diesendruck, G. (2003).
Categories for names or names for categories? the interplay between
domain-specific conceptual structure and language.
Language and Cognitive Processes, 18:759 -- 787.
[ bib ]
Diesendruck, G. and Gelman, S. A. (1999).
Domain differences in absolute judgments of category membership:
Evidence for an essentialist account of categorization.
Psychonomic Bulletin & Review, 6:338--346.
[ bib ]
Dougherty, J. (1978).
Salience and relativity in classification.
American Ethnologist, 5:66--80.
[ bib ]
Downing, P. (1977).
On the creation and use of english compound nouns.
Language, 53:810--842.
[ bib ]
Dowty, D., Wall, R., and Peters, S. (1981).
Introduction to Montague semantics.
D. Reidel.
[ bib ]
STATEMENTS THAT DIFFER ONLY WITH RESPECT TO THE LOCATION OF THEIR
CONTRASTIVE FOCI (E.G. "CLYDE MARRIED 'BERTHA'" VS. "CLYDE 'MARRIED'
BERTHA") ARE INVESTIGATED. IT IS ARGUED THAT SUCH DIFFERENCES, ALTHOUGH
PLAUSIBLY CONSTRUED AS PRAGMATIC DIFFERENCES (NON-SEMANTIC), PLAY
AN IMPORTANT ROLE IN DETERMINING THE MEANING OF CERTAIN LARGER EXPRESSIONS
IN WHICH THEY ARE EMBEDDED. IN PARTICULAR, A VARIETY OF EPISTEMIC
CONTEXTS ('REASON TO BELIEVE THAT', 'SEE THAT', 'KNOW THAT') ARE
SENSITIVE TO THE CONTRASTIVE DIFFERENCES IN THE EMBEDDED THAT-CLAUSE.
TO KNOW THAT CLYDE MARRIED 'BERTHA' IS NOT (NECESSARILY) TO KNOW
THAT CLYDE 'MARRIED' BERTHA.
Dry, M. J. and Storms, G. (2010).
Features of graded category structure: Generalizing the family
resemblance and polymorphous concept models.
Acta Psychologica, 133:244--255.
[ bib ]
Dupre, J. (2003).
Human nature and the limits of science.
Oxford : Clarendon.
[ bib ]
Efron, B. and Tibshirani, R. (1993).
An introduction to the bootstrap.
Chapman & Hall, London.
[ bib ]
Eimas, P. and Quinn, P. (1994).
Studies on the formation of perceptually based basic-level categories
in young infants.
Child Development, 65:903--917.
[ bib ]
Einhorn, H. J. and Hogarth, R. M. (1986).
Judging probable cause.
Psychological Bulletin, 99(1):3 -- 19.
[ bib ]
Eliasmith, C. and Thagard, P. (2001).
Integrating structure and meaning: a distributed model of analogical
mapping.
Cognitive Science, 25(2):245--286.
[ bib |
http ]
In this paper we present Drama, a distributed model of analogical
mapping that integrates semantic and structural constraints on constructing
analogies. Specifically, Drama uses holographic reduced representations
[Plate 1994], a distributed representation scheme, to model the effects
of structure and meaning on human performance of analogical mapping.
Drama is compared to three symbolic models of analogy (SME, Copycat,
and ACME) and one partially distributed model (LISA). We describe
Drama's performance on a number of example analogies and assess the
model in terms of neurological and psychological plausibility. We
argue that Drama's successes are due largely to integrating structural
and semantic constraints throughout the mapping process. We also
claim that Drama is an existence proof of using distributed representations
to model high-level cognitive phenomena
Keywords: Human, Meaning
Estes, W. (1986).
Memory storage and retrieval processes in category learning.
Journal of Experimental Psychology: General, 115:155--174.
[ bib ]
Estes, W. (1994).
Classification and cognition.
Oxford University Press.
[ bib ]
Estes, Z. (2003).
Domain differences in the structure of artifactual and natural
categories.
Memory & Cognition, 31:199--214.
[ bib ]
Estes, Z. (2004).
Confidence and gradedness in semantic categorization: Definitely
somewhat artifactual, maybe absolutely natural.
Psychonomic Bulletin & Review, 11:1041--1047.
[ bib ]
Estes, Z. and Glucksberg, S. (2000a).
Interactive property attribution in concept combination.
Memory & Cognition, 28:28--34.
[ bib ]
Estes, Z. and Glucksberg, S. (2000b).
Similarity and attribution in concept combination: Reply to
wisniewski.
Memory & cognition, 28(1):39.
ID: 2877435; M3: Article; Accession Number: 2877435; Estes,
ZacharyGlucksberg, Sam; Source Information: Jan2000, Vol. 28 Issue 1, p39;
Subject Term: COGNITIONSubject Term: COMPREHENSIONSubject Term: CONCEPTS;
Number of Pages: 2p; Document Type: Article.
[ bib |
http ]
Argues that postcomprehension elaboration processes can account for
specific property instantiations. Reply to comments on the authors'
study on the nonrole of similarity in concept combination; Perceived
similarity between constituents of a combined concept as an outcome
of the comprehension process, not a prior condition for, or an integral
part of, that process.
Keywords: COGNITION; COMPREHENSION; CONCEPTS
Everitt, B. S. and Dunn, G. (2001).
Principal components analysis.
In Applied multivariate data analysis, chapter Principal
components analysis, pages 48--73. Arnold, London, UK, 2 edition.
[ bib ]
Federmeier, K. and Kutas, M. (1999).
A rose by any other name: Long-term memory structure and sentence
processing.
Journal of Memory and Language, 41:469--495.
[ bib ]
Fischer, G. H. (1973).
The linear logistic test model as an instrument in educational
research.
Acta Psychologica, 37:359--374.
[ bib ]
Fischer, G. H. (1995).
The linear logistic test model.
In Fischer, G. H. and Molenaar, I. W., editors, Rasch models:
Foundations, Recent Developments, and Applications, chapter The linear
logistic test model, pages 131--155. Springer, New York, NY.
[ bib ]
Fisher, C. (2000).
Partial sentence structure as an early constraint on language
acquisition, pages 275--290.
MIT Press.
[ bib ]
Fodor, J. (1972).
Some reflections on l. s. vygotsky's thought and language.
Cognition, 1:83--95.
[ bib ]
Fodor, J. (1975).
The language of thought.
Crowell.
[ bib ]
Fodor, J. (1977).
Semantics: Theories of meaning in generative grammar.
Crowell.
[ bib ]
Fodor, J. (1981).
The present status of the innateness controversy, pages
257--316.
MIT Press.
[ bib ]
Keywords: Cognitive science, Science
Fodor, J. (1983a).
The modularity of mind.
MIT Press.
[ bib ]
Fodor, J. (1994).
Concepts - a pot-boiler.
Cognition, 50:95--113.
[ bib ]
Keywords: Concepts
Fodor, J., Garrett, M., Walker, E., and Parkes, C. (1980).
Against definitions.
Cognition, 8:263--367.
[ bib ]
Fodor, J. and Lepore, E. (1996a).
The red herring and the pet fish: why concepts still can't be
prototypes.
Cognition, 58:253--270.
[ bib ]
Keywords: Concepts
Fodor, J. and Pylyshyn, Z. (1988).
Connectionism and cognitive architecture: A critical analysis.
Cognition, 28:136--196.
[ bib ]
Fodor, J. A. (1964).
On knowing what we would say.
Philosophical Review, 73:198--212.
[ bib ]
Fodor, J. A. (1998).
Concepts: Where cognitive science went wrong.
Oxford University Press, Oxford, UK.
[ bib ]
Jerry Fodor presents a strikingly original theory of the basic constituents
of thought. He suggests that the heart of a cognitive science is
its theory of concepts, and that cognitive scientists have gone badly
wrong in many areas because their assumptions about concepts have
been seriously mistaken. Fodor argues compellingly for an atomistic
theory of concepts, and maintains that future work on human cognition
should build upon new foundations. (publisher, edited)
Fodor, J. A. (2001b).
Language, thought and compositionality.
Philosophy, 48(Supp): 227-242):--242.
[ bib ]
Keywords: COMPOSITION, COMPOSITIONALITY, LANGUAGE, METAPHYSICS, MIND, THOUGHT
Fodor, J. A. (2001c).
The mind doesn't work that way: the scope and limits of
computational psychology.
MIT Press, Cambridge, MA.
[ bib ]
Keywords: Cognitive science, Nativism (Psychology), Philosophy of mind
Fodor, J. A. (2002).
The mind doesn't work that way: The scope and limits of computational
psychology.
Philosophical Psychology, 15(4): 551-562):--562.
[ bib ]
Keywords: MIND, PSYCHOLOGY
Fodor, J. A. (2003).
Hume Variations.
Clarendon-Press.
[ bib ]
Hume says in the Treatise that his main project is to construct a
theory of human nature and, in particular, a theory of the mind.
Hume Variations examines his account of cognition and how it is grounded
in his 'theory of ideas'. Fodor discusses such key topics as the
distinction between 'simple' and 'complex' ideas, the thesis that
an idea is some kind of picture, and the roles that 'association'
and 'imagination' play in cognitive processes. He argues that the
theory of ideas, as Hume develops it, is both historically and ideologically
continuous with the representational theory of mind as it is now
widely endorsed by cognitive scientists. (publisher, edited)
Keywords: COGNITION, CONCEPT, EPISTEMOLOGY, IMAGINATION, SCIENTIST, THEORY
Fodor, J. A. (2004a).
Having concepts: A brief refutation of the twentieth century.
Mind and Language, 19(1): 29-47):--47.
[ bib ]
Fodor, J. A. and Lepore, E. (1992).
Holism: A shopper's guide.
Blackwell, Oxford, UK.
[ bib ]
The main question addressed in this book is whether individuation
of the contents of thoughts and linguistic expressions is inherently
holistic. The authors consider arguments that are alleged to show
that the meaning of a word depends on the entire language that it
belongs to, or that the meaning of a scientific hypothesis depends
on the entire theory that entails it, or that the content of a concept
depends on the entire belief system of which it is part. If these
arguments are sound then it would follow that the meanings of words,
sentences, hypotheses, prediction, discourages, dialogues, texts,
thoughts and the like are merely derivative. The implications of
holism about meaning for other philosophical issues (intentional
explanation, translation, realism, skepticism, etc.) are also explored.
Authors discussed include Quine, Davidson, Lewis, Dennett, Block,
Field, Churchland, and others
Fodor, J. A. and Lepore, E. (1994).
"Is Radical Interpretation Possible?" in Philosophical
Perspectives, 8: Logic and Language, 1994, Tomberlin, James, pages --.
Ridgeview.
[ bib ]
The specter of a certain transcendental argument has haunted the philosophy
of language ever since Wittgenstein wrote the Philosophical Investigations.
We take the form of the argument to be something like this: Argument
form T: 1) No language would be interpretable at all unless it were
radically interpretable; that is, unless it were interpretable from
the epistemic position of a radical interpreter. 2) No language would
be radically interpretable unless it were F. 3) (Natural) languages
are actually interpreted; hence, natural language are radically interpretable.
4) Therefore natural languages are F. We say that this is the specter
of an argument because there is less than universal consensus as
to what goes in for F. But never mind: an argument schema is sufficient
for our purposes. We are going to claim that no case has been made
for the soundness of any familiar instantiations of argument from
T
Fodor, J. A. and Lepore, E. (1996b).
What cannot be evaluated cannot be evaluated, and it cannot be
supervalued either.
Journal of Philosophy, 93(10): 516-535):--535.
[ bib ]
Keywords: EPISTEMOLOGY, LANGUAGE, SEMANTICS, SENTENCE, TRUTH, VALUE
Fodor, J. A. and Lepore, E. (1999).
All at sea in semantic space: Churchland on meaning similarity.
Journal of Philosophy, 96(8): 381-403):--403.
[ bib ]
Keywords: EPISTEMOLOGY, LANGUAGE, MEANING, SEMANTICS, SIMILARITY, SPACE
Fodor, J. A. and Lepore, E. (2001).
Why compositionality won't go away: Reflections on horwich's
'deflationary' theory.
Ratio, 14(4):):350--368.
[ bib ]
Keywords: COMPOSITIONALITY, DEFLATION, EXPRESSION, LANGUAGE, THEORY
Fodor, J. A. and LePore, E. (2002).
The compositionality papers.
Oxford ; New York : Clarendon Press, c2002.
[ bib ]
Keywords: Composionality (Linguistics), Compositionality (Linguistics), Language
and languages - Philosophy, Meaning, Semantics
Follett, W. (1970).
Modern American usage.
Grosset & Dunlap.
[ bib ]
Ford, M. E. and Nichols, C. W. (1987).
A taxonomy of human goals and some possible applications.
In Ford, M. E. and Ford, D. H., editors, Humans as
self-constructing systems: Putting the framework to work, chapter A
taxonomy of human goals and some possible applications, pages 289--311.
Erlbaum, Hillsdale, NJ.
[ bib ]
Förster, J., Liberman, N., and Higgins, E. T. (2005).
Accessibility from active and fulfilled goals.
Journal of Experimental Social Psychology, 41:220--239.
[ bib ]
Franks, B. (1995).
Sense generation: A "quasi-classical" approach to concepts and
concept combination.
Cognitive Science, 19:441--505.
[ bib ]
Franks, J. and Bransford, J. (1971).
Abstraction of visual patterns.
Journal of Experimental Psychology, 90:65--74.
[ bib ]
Frege, G. (1952).
On sense and reference, pages --.
Basil Blackwell.
[ bib ]
Gagn�, C. and Murphy, G. (1996).
Influence of discourse context on feature availability in conceptual
combination.
Discourse Processes, 22:79--101.
[ bib ]
Gagn�, C. and Shoben, E. (1997).
Influence of thematic relations on the comprehension of modifier-noun
combinations.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 23:71--87.
[ bib ]
Galbraith, R. C. and Underwood, B. J. (1973).
Perceived frequency of concrete and abstract words.
Memory & Cognition, 1:56--60.
[ bib ]
Garbarino, E. and Johnson, M. S. (2001).
Effects of consumer goals on attribute weighting, overall
satisfaction, and product usage.
Psychology & Marketing, 18:929--949.
[ bib ]
Garcia-Retamero, R. and Dhami, M. K. (2009).
Take-the-best in expert-novice decision strategies for residential
burglary.
Psychonomic Bulletin & Review, 16:163--169.
[ bib ]
Gardner, R. W. (1953).
Cognitive styles in categorizing behavior.
Journal of Personality, 22:214--233.
[ bib ]
Garfinkel, A. (1981).
Forms of explanation: Rethinking the questions in social
theory.
Yale-Univ-Pr, New Haven.
[ bib ]
Garrod, S. and Anderson, A. (1987).
Saying what you mean in dialogue: A study in conceptual and semantic
co-ordination.
Cognition, 27:181--218.
[ bib ]
Garrod, S. and Doherty, G. (1994).
Conversation, co-ordination and convention: An empirical
investigation of how groups establish linguistic conventions.
Cognition, 53:181--215.
[ bib ]
Garrod, S. and Sanford, A. (1977).
Interpreting anaphoric relations: The integration of semantic
information while reading.
Journal of Verbal Learning and Verbal Behavior, 16:77--90.
[ bib ]
Gati, I. and Tversky, A. (1984).
Weighting common and distinctive features in perceptual and
conceptual judgements.
Cognitive Psychology, 16:341--370.
[ bib ]
Gelman, A., Carlin, J. B., Stern, H. S., and Rubin, D. B. (2004).
Bayesian Data Analysis. Second Edition.
Chapman & Hall/CRC, London, UK.
[ bib ]
Gelman, A., Goegebeur, Y., Tuerlinckx, F., and Van Mechelen, I. (2000).
Diagnostic checks for discrete-data regression models using posterior
predictive simulations.
Applied Statistics, 42:247--268.
[ bib ]
Gelman, R. (1990).
First principles organize attention to and learning about relevant
data: Number and the animate-inanimate distinction as examples.
Cognitive Science, 14:79--106.
[ bib ]
Gelman, S. (1988).
The development of induction within natural kind and artifact
categories.
Cognitive Psychology, 20:65--95.
[ bib ]
Gelman, S., Coley, J., and Gottfried, G. (1994).
Essentialist beliefs in children: The acquisition of concepts
and theories, pages 341--365.
Cambridge University Press.
[ bib ]
Gelman, S., Croft, W., Fu, P., Clausner, T., and Gottfried, G. (1998).
Why is a pomegranate an apple? the role of shape, taxonomic
relatedness, and prior lexical knowledge in children's overextensions of
applei and dog.
Journal of Child Language, 25:267--291.
[ bib ]
Gelman, S. and Diesendruck, G. (1999).
What's in a concept? Context, variability, and psychological
essentialism.
In Sigel, I. E., editor, Development of mental representation:
Theories and applications, chapter What's in a concept? Context,
variability, and psychological essentialism, pages 87--111. Lawrence Erlbaum,
Mahwah, NJ.
[ bib ]
Gelman, S. and Markman, E. (1986).
Categories and induction in young children.
Cognition, 23:183--209.
[ bib ]
Gelman, S. and Markman, E. (1987).
Young children's inductions from natural kinds: The role of
categories and appearances.
Child Development, 58:1532--1541.
[ bib ]
Gelman, S. and Wellman, H. (1991).
Insides and essences: Early understandings of the non-obvious.
Cognition, 38:213--244.
[ bib ]
Gelman, S. A. (2004).
Psychological essentialism in children.
Trends in Cognitive Sciences, 8(9):404 -- 409.
[ bib ]
Psychological essentialism is the idea that certain categories, such
as 'lion' or 'female', have an underlying reality that cannot be
observed directly. Where does this idea come from? This article reviews
recent evidence suggesting that psychological essentialism is an
early cognitive bias. Young children look beyond the obvious in many
converging ways: when learning words, generalizing knowledge to new
category members, reasoning about the insides of things, contemplating
the role of nature versus nurture, and constructing causal explanations.
These findings argue against the standard view of children as concrete
thinkers, instead claiming that children have an early tendency to
search for hidden, non-obvious features.
Gelman, S. A. and Hirschfeld, L. A. (1999).
How biological is essentialism?
In Medin, D. and Atran, S., editors, Folkbiology, pages
403--446. MIT, Cambridge, MA.
[ bib |
http ]
(from the chapter) The authors argue for a notion of "essence"
that is broader and more contained than they found in the literature.
The authors ask how essential essentialism is in empirical thought
and investigate evidence and sources for essentialist representations.
The authors use the title of the chapter to provoke a discussion
of how well motivated the attention is that folkbiology has received
in research on essentialist reasoning as well as that which essentialism
has received in research on folkbiology. The authors conclude that
the motivation is better with respect to the latter than the former
and that essentialism is an essential part of folkbiology though
folkbiology is not critical to understanding essentialism. [Chapter;
In English; Print]
Gentner, D. and France, I. (1988).
The verb mutability effect: Studies of the combinatorial
semantics of nouns and verbs, pages --.
Morgan Kaufman.
[ bib ]
Gerrig, R. (1989).
The time course of sense creation.
Memory & Cognition, 17:194--207.
[ bib ]
Gerrig, R. and Murphy, G. (1992).
Contextual influences on the comprehension of complex concepts.
Language and Cognitive Processes, 7:205--230.
[ bib ]
Gibbs, R.W., J. (1984).
Literal meaning and psychological theory.
Cognitive Science, 8:275--304.
[ bib ]
Gibbs, R. W., Beitel, D. A., Harrington, M., and Sanders, P. E. (1994).
Taking a stand on the meanings of “stand": Bodily experience as a
motivation for polysemy.
Journal of Semantics, 11:231--251.
[ bib ]
Gigerenzer, G. and Todd, P. M. (1999).
Fast and frugal heuristics: The adaptive toolbox.
In Gigerenzer, G., Todd, P. M., and the ABC Research Group,
editors, Simple heuristics that make us smart, chapter Fast and frugal
heuristics: The adaptive toolbox, pages 3--34. Oxford University Press, New
York, NY.
[ bib ]
Gilbert, D. T. and Malone, P. S. (1995).
The correspondence bias.
Psychological Bulletin, 117(1):21--38.
[ bib ]
The correspondence bias is the tendency to draw inferences about a
person's unique and enduring dispositions from behaviors that can
be entirely explained by the situations in which they occur. Although
this tendency is one of the most fundamental phenomena in social
psychology, its causes and consequences remain poorly understood.
This article sketches an intellectual history of the correspondence
bias as an evolving problem in social psychology, describes 4 mechanisms
(lack of awareness, unrealistic expectations, inflated categorizations,
and incomplete corrections) that produce distinct forms of correspondence
bias, and discusses how the consequences of correspondence-biased
inferences may perpetuate such inferences.
Glass, A. and Holyoak, K. (1975).
Alternative conceptions of semantic memory.
Cognition, 3:313--339.
[ bib ]
Glöckner, A. and Betsch, T. (2011).
The empirical content of theories in judgment and decision making:
Shortcomings and remedies.
Judgment and Decision Making, 6:711--721.
[ bib ]
Gluck, M. and Bower, G. (1988).
From conditioning to category learning: An adaptive network model.
Journal of Experimental Psychology: General, 117:227--247.
[ bib ]
Glucksberg, S. and Estes, Z. (2000).
Feature accessibility in conceptual combination: Effects of
context-induced relevance.
Psychonomic Bulletin & Review, 7:510--515.
[ bib ]
Glymour, C. (2000).
Bayes nets as psychological models.
In Keil, F. W. R., editor, Explanation and Cognition,
chapter 7. MIT Press.
[ bib ]
Goldstone, R. (1994a).
Influences of categorization on perceptual discrimination.
Journal of Experimental Psychology: General, 123:178--200.
[ bib ]
Goldstone, R. (1994b).
The role of similarity in categorization: Providing a groundwork.
Cognition, 52:125--157.
[ bib ]
Goldstone, R. (1994c).
Similarity, interactive activation, and mapping.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 20:3--28.
[ bib ]
Goldstone, R. (2000).
Unitization during category learning.
Journal of Experimental Psychology: Human Perception and
Performance, 26:86--112.
[ bib ]
Goldstone, R., Medin, D., and Gentner, D. (1991).
Relational similarity: The non-independence of features in similarity
judgments.
Cognitive Psychology, 23:222--264.
[ bib ]
Keywords: Judgment
Goldstone, R., Medin, D., and Halberstadt, J. (1997).
Similarity in context.
Memory & Cognition, 25:237--255.
[ bib ]
Goldstone, R. and Steyvers, M. (2001).
The sensitization and differentiation of dimensions during category
learning.
Journal of Experimental Psychology: General, 130:116--139.
[ bib ]
Goldstone, R. L. (1996).
Isolated and interrelated concepts.
Memory & Cognition, 24:608--628.
[ bib ]
Goldstone, R. L., Steyvers, M., and Rogosky, B. J. (2003).
Conceptual interrelatedness and caricatures.
Memory & Cognition, 31:169--180.
[ bib ]
Golinkoff, R., Shuff-Bailey, M., Olguin, R., and Ruan, W. (1995).
Young children extend novel words at the basic level: Evidence for
the principle of categorical scope.
Developmental Psychology, 31:494--507.
[ bib ]
Goodman, N. (1965).
Fact, fiction, and forecast (2nd ed.).
Bobbs-Merrill.
[ bib ]
Goodman, N. (1972).
Seven strictures on similarity.
In Goodman, N., editor, Problems and projects, chapter Seven
strictures on similarity, pages 437--447. Bobbs-Merrill, Indianapolis, IN.
[ bib ]
Gopnik, A. (1998).
Explanation as orgasm.
Minds and Machines, 8(1): 101-118):--118.
[ bib ]
Keywords: EXPLANATION
Gorfein, D. S., Viviani, J. M., and Leddo, J. (1982).
Norms as a tool for the study of homography.
Memory & Cognition, 10:503--509.
[ bib ]
Gorfein, D. S. and Weingartner, K. M. (2008).
On the norming of homophones.
Behavior Research Methods, 40:522--530.
[ bib ]
Graff, D. (2000).
Shifting sands: An interest-relative theory of vagueness.
Philosophical Topics, 28:45--81.
[ bib ]
Grandy, R. E. (1987).
In defense of semantic fields.
In Le Pore, E., editor, New directions in semantics, chapter In
defense of semantic fields, pages 261--280. Academic Press, New York, NY.
[ bib ]
Graves, R. (1926).
Impenetrability or the proper habit of English.
Hogarth Press.
[ bib ]
Grice, H. P. (1989).
Studies in the way of words.
Harvard University Press, Cambridge, MA.
[ bib ]
Griffiths, T. L., Steyvers, M., and Tenenbaum, J. B. (2007).
Topics in semantic representation.
Psychological Review, 114:211--244.
[ bib ]
Gutheil, G., Vera, A., and Keil, F. C. (1998).
Do houseflies think? patterns of induction and biological beliefs in
development.
Cognition, 66(1):33--49.
[ bib |
http ]
A current debate within the cognitive development literature addresses
how best to characterize conceptual change. Within one proposal,
development primarily consists of a series of radical conceptual
shifts or restructurings in which the most current understanding
is inexplicable within (incommensurate with) prior conceptual structure.
Alternatively, development is discussed as more gradual enrichment
of multiple existing early explanatory systems, allowing for commensuarability
over time and change. This paper examines the literature in this
debate with specific focus on naive biological understanding, and
discusses a series of studies on preschoolers' inductive inferences
across biological and non-biological kinds. Children were taught
a series of biological properties for a human being (e.g. eating,
sleeping etc.), and asked to generalize these properties to both
biological (e.g. dogs, worms) and non-biological kinds (e.g. clouds,
tables). The results of these studies support the gradual-enrichment
proposal. Specifically, 4-year-olds seem to possess a limited, but
coherent and independent biological theory which may form the basis
of mature understanding of biological kinds. These results are discussed
in terms of multiple explanatory systems which both preschoolers
and adults can employ across development to effectively guide their
decisions within a given domain
Keywords: Adult, Human, Inference
Hadjichristidis, C., Sloman, S., Stevenson, R., and Over, D. (2004).
Feature centrality and property induction.
Cognitive Science, 28(1):45--.
[ bib ]
A feature is central to a concept to the extent that other features
depend on it. Four studies tested the hypothesis that people will
project a feature from a base concept to a target concept to the
extent that they believe the feature is central to the two concepts.
This centrality hypothesis implies that feature projection is guided
by a principle that aims to maximize the structural commonality between
base and target concepts. Participants were told that a category
has two or three novel features. One feature was the most central
in that more properties depended on it. The extent to which the target
shared the feature's dependencies was manipulated by varying the
similarity of category pairs. Participants' ratings of the likelihood
that each feature would hold in the target category support the centrality
hypothesis with both natural kind and artifact categories and with
both well-specified and vague dependency structures. [Copyright 2004
Elsevier]
Haith, M. and Benson, J. (1998).
Infant cognition, pages 199--254.
John Wiley.
[ bib ]
Hall, D. and Waxman, S. (1993).
Assumptions about word meaning: Individuation and basic-level kinds.
Child Development, 64:1550--1570.
[ bib ]
Hampton, J. (1982).
A demonstration of intransitivity in natural categories.
Cognition, 12:151--164.
[ bib ]
Hampton, J. (1987).
Inheritance of attributes in natural concept conjunctions.
Memory & Cognition, 15:55--71.
[ bib ]
Hampton, J. (1988a).
Disjunction of natural concepts.
Memory & Cognition, 16:579--591.
[ bib ]
Hampton, J. (1988b).
Overextension of conjunctive concepts: Evidence for a unitary model
of concept typicality and class inclusion.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 14:12--32.
[ bib ]
Hampton, J. (1993).
Categories and concepts: Theoretical views and inductive data
analysis, chapter Prototype models of concept representationHa, pages
67--95.
Academic Press.
[ bib ]
Hampton, J. (1996).
Conjunctions of visually based categories: Overextension and
compensation.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 22:378--396.
[ bib ]
Hampton, J. (1997a).
Associative and similarity-based processes in categorization
decisions.
Memory & Cognition, 25:--.
[ bib ]
Hampton, J. (1997b).
Conceptual combination: Conjunction and negation of natural concepts.
Memory & Cognition, 25:888--909.
[ bib ]
Hampton, J. (1997c).
Emergent attributes in conceptual combinations, pages 83--110.
American Psychological Association Press.
[ bib ]
Hampton, J. (1997d).
Psychological representation of concepts, pages --.
Psychology Press.
[ bib ]
Keywords: Concepts
Hampton, J. (2006).
Concepts as prototypes.
In Psychology of learning and motivation: Advances in research
and theory, volume 46 of PSYCHOLOGY OF LEARNING AND
MOTIVATION-ADVANCES IN RESEARCH AND THEORY, pages 79--113. Elsevier
Academic Press Inc, 525 B STREET, SUITE 1900, SAN DIEGO, CA 92101-4495
USA.
[ bib ]
Hampton, J. and Dubois, D. (1993).
Psychological models of concepts: Introduction, pages --.
Academic Press.
[ bib ]
Keywords: Concepts
Hampton, J. A. (1979).
Polymorphous concepts in semantic memory.
Journal of Verbal Learning and Verbal Behavior, 18:441--461.
[ bib ]
Hampton, J. A. (1981).
An investigation of the nature of abstract concepts.
Memory & Cognition, 9:149--156.
[ bib ]
Hampton, J. A. (1995).
Testing the prototype theory of concepts.
Journal of Memory and Language, 34:686--708.
[ bib ]
Hampton, J. A. (1998).
Similarity-based categorization and fuzziness of natural categories.
Cognition, 65:137--165.
[ bib ]
Hampton, J. A. (2007).
Typicality, graded membership, and vagueness.
Cognitive Science, 31:355--384.
[ bib ]
Hampton, J. A. (2010).
Stability in concepts and evaluating the truth of generic statements.
In Pelletier, F. J., editor, Kinds, things, and stuff: Concepts
of generics and mass terms. New directions in cognitive science, chapter
Stability in concepts and evaluating the truth of generic statements, pages
80--99. Oxford University Press, Oxford.
[ bib ]
Hampton, J. A., Dubois, D., and Yeh, W. (2006).
Effects of classification context on categorization in natural
categories.
Memory & Cognition, 34:1431--1443.
[ bib ]
Hampton, J. A., Estes, Z., and Simmons, C. L. (2005).
Comparison and contrast in perceptual categorization.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 31:1459--1476.
[ bib ]
Hampton, J. A., Estes, Z., and Simmons, S. (2007).
Metamorphosis: Essence, appearance, and behavior in the
categorization of natural kinds.
Memory & Cognition, 35:1785--1800.
[ bib ]
Hampton, J. A. and Gardiner, M. M. (1983).
Measures of internal category structure: A correlational analysis of
normative data.
British Journal of Psychology, 74:491--516.
[ bib ]
Hampton, J. A., Storms, G., Simmons, C. L., and Heussen, D. (2009).
Feature integration in natural language concepts.
Memory & Cognition, 37:1150--1163.
[ bib ]
Hanke, D. E. (2004).
Teleology: the explanation that bedevils biology.
In Cornwell, J., editor, Explanations: Styles of explanation in
science, pages 143--155. Oxford University Press, Oxford.
[ bib ]
Hart, H. (1961).
The concept of law.
Clarendon Press.
[ bib ]
Harvey, J. H. and Weary, G. (1984).
Current issues in attribution theory and research.
Annual Review of Psychology, 35:427.
ID: 11266058; M3: Article; Accession Number: 11266058; Harvey, John
H. 1Weary, Gifford 2; Affiliations: 1: Department of Psychology, Texas Tech
University 2: Department of Psychology, Ohio State University; Source
Information: 1984, Vol. 35, p427; Thesaurus Term: SOCIAL psychology; Subject
Term: ATTRIBUTION (Social psychology)Subject Term: PSYCHOLOGY -- Research;
Number of Pages: 33p; Document Type: Article.
[ bib |
http ]
Discusses studies of current issues in attribution theory and research.
Measurement of attribution; Nature of attribution; Perceptual and
cognitive processes; Affective consequences of achievement-related
attributions.
Keywords: SOCIAL psychology; ATTRIBUTION (Social psychology); PSYCHOLOGY --
Research
Haslam, N., Bastian, B., and Bissett, M. (2004).
Essentialist beliefs about personality and their implications.
Personality and Social Psychology Bulletin, 30(12):1661 --
1673.
[ bib |
DOI ]
Two studies examine implicit theories about the nature of personality
characteristics, asking whether they are understood as underlying
essences. Consistent with the hypothesis, essentialist beliefs about
personality formed a coherent and replicable set. Personality characteristics
differed systematically in the extent to which they were judged to
be discrete, biologically based, immutable, informative, consistent
across situations, and deeply inherent within the person. In Study
1, the extent to which characteristics were essentialized was positively
associated with their perceived desirability, prevalence, and emotionality.
In Study 2, essentialized characteristics were judged to be particularly
important for defining people?s identity, for forming impressions
of people, and for communicating about a third person. The findings
indicate that people understand some personality attributes in an
essentialist fashion, that these attributes are taken to be valued
elements of a shared human nature, and that they are particularly
central to social identity and judgment.
Keywords: essentialism ? personality ? traits ? human nature
Haslam, N., Rothschild, L., and Ernst, D. (2000).
Essentialist beliefs about social categories.
British Journal of Social Psychology, 39(1):113 -- 127.
[ bib ]
This study examines beliefs about the ontological status of social
categories, asking whether their members are understood to share
fixed, inhering essences or natures. Forty social categories were
rated on nine elements of essentialism. These elements formed two
independent dimensions, representing the degrees to which categories
are understood as natural kinds and as coherent entities with inhering
cores ('entitativity' or reification), respectively. Reification
was negatively associated with categories evaluative status, especially
among those categories understood to be natural kinds. Essentialism
is not a unitary syndrome of social beliefs, and is not monolithically
associated with devaluation and prejudice, but it illuminates several
aspects of social categorization.
Haslam, N., Rothschild, L., and Ernst, D. (2002).
Are essentialist beliefs associated with prejudice?
British Journal of Social Psychology, 41(1):87 -- 100.
[ bib ]
Gordon Allport (1954) proposed that belief in group essences is one
aspect of the prejudiced personality, alongside a rigid, dichotomous
and ambiguity-intolerant cognitive style. We examined whether essentialist
beliefs?beliefs that a social category has a fixed, inherent, identity-defining
nature?are indeed associated in this fashion with prejudice towards
black people, women and gay men. Allport's claim, which is mirrored
by many contemporary social theorists, received partial support but
had to be qualified in important respects. Essence-related beliefs
were associated strongly with anti-gay attitudes but only weakly
with sexism and racism, and they did not reflect a cognitive style
that was consistent across stigmatized categories. When associations
with prejudice were obtained, only a few specific beliefs were involved,
and some anti-essentialist beliefs were associated with anti-gay
attitudes. Nevertheless, the powerful association that essence-related
beliefs had with anti-gay attitudes was independent of established
prejudice-related traits, indicating that they have a significant
role to play in the psychology of prejudice.
Hastie, R., Schroeder, C., and Weber, R. (1990).
Creating complex social conjunction categories from simple
categories.
Bulletin of the Psychonomic Society, 28:242--247.
[ bib ]
Haviland, S. and Clark, H. (1974).
What's new? acquiring new information as a process in comprehension.
Journal of Verbal Learning and Verbal Behavior, 13:512--521.
[ bib ]
Hayes, B. and Taplin, J. (1992).
Developmental changes in categorization processes: Knowledge and
similarity-based modes of categorization.
Journal of Experimental Child Psychology, 54:188--212.
[ bib ]
Hayes, B. and Taplin, J. (1993).
Developmental differences in the use of prototype and
exemplar-specific information.
Journal of Experimental Child Psychology, 55:329--352.
[ bib ]
Hayes-Roth, B. and Hayes-Roth, F. (1977).
Concept learning and the recognition and classification of exemplars.
Journal of Verbal Learning and Verbal Behavior, 16:321--328.
[ bib ]
Heibeck, T. and Markman, E. (1987).
Word learning in children: An examination of fast mapping.
Child Development, 58:1021--1034.
[ bib ]
Heider, F. (1958, reprinted 1983).
The psychology of interpersonal relations.
NJ, US: Lawrence Erlbaum Associates.
[ bib ]
(from the introduction) How one person thinks and feels about another
person, how he perceives him and what he does to him, what he expects
him to do or think, how he reacts to the actions of the other--these
are some of the phenomena that will be treated. Our concern will
be with "surface" matters, the events that occur in everyday life
on a conscious level, rather than with the unconscious processes
studied by psychoanalysis in "depth" psychology. /// The discussion
will center on the person as the basic unit to be investigated. That
is to say, the two-person group and its properties as a superindividual
unit will not be the focus of attention. /// This then will be the
purpose of this book: to offer suggestions for the construction of
a language that will allow us to represent, if not all, at least
a great number of interpersonal relations, discriminated by conventional
language in such a way that their place in a general system will
become clearer. This talk will require identifying and defining some
of the underlying concepts and their patterns of combination that
characterize interpersonal relations. (PsycINFO Database Record (c)
2004 APA, all rights reserved); Introduction Perceiving the other
person The other person as perceiver The naive analysis of action
Desire and pleasure Environmental effects Sentiment Ought and value
/ Request and command Benefit and harm Reaction to the lot of the
other person Conclusion Appendix: A notation for representing interpersonal
relations Bibliography Author index Subject index
Keywords: Interpersonal Interaction; Language; Social Perception
Heit, E. (1997).
Knowledge and concept learning, pages 7--41.
Psychology Press.
[ bib ]
Heit, E. (1998).
Influences of prior knowledge on selective weighting of category
members.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 24:712--731.
[ bib ]
Heit, E. (2000).
Properties of inductive reasoning.
Psychonomic Bulletin & Review, 7:569--592.
[ bib ]
Heit, E. and Bott, L. (2000).
Knowledge selection in category learning, pages 163--199.
Academic Press.
[ bib ]
Heit, E. and Rubinstein, J. (1994).
Similarity and property effects in inductive reasoning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 20:411--422.
[ bib ]
Hempel, C. (1965a).
Aspects of scientific explanation and other essays in the
philosophy of science.
Free Press, New York, NY.
[ bib ]
Hempel, C. and Oppenheim, P. (1948).
Studies in the logic of explanation.
Philosophy of Science, 15:135--175.
[ bib ]
Keywords: EMERGENCE, EXPLANATION, LAWS, LOGIC, PREDICTION, SCIENCE, THEORY
Hempel, C. G. (1965b).
Aspects of scientific explanation, and other essays in the
philosophy of science.
New York; Collier-Macmillan: London : Free Press.
[ bib ]
Keywords: Explanation, Philosophy, Science
Hempel, C. G., Essler, W. K., Putnam, H., and Stegm?ller, W. (1985).
Epistemology, methodology, and philosophy of science : essays in
honour of Carl G. Hempel.
Dordrecht, Holland ; Boston, U.S.A. : D. Reidel Pub. Co.
[ bib ]
Keywords: Hempel,Carl Gustav,1905-, Knowledge,Theory of - Addresses,essays,lectures,
Philosophy, Philosophy of Science, Science, Science - Methodology,
Science - Philosophy
Heussen, D. and Hampton, J. A. (2007).
Emeralds are expensive because they are rare: Plausibility of
property explanations.
In Proceedings of the 2nd European Cognitive Science
Conference, pages 101--106, Hove, UK. Lawrence Erlbaum Associates.
[ bib ]
Hilbig, B. E. (2008).
Individual differences in fast-and-frugal decision making:
Neuroticism and the recognition heuristic.
Journal of Research in Personality, 42:1641--1645.
[ bib ]
Hilton, D. J. and Slugoski, B. R. (1986).
Knowledge-based causal attribution - the abnormal conditions focus
model.
Psychological Review, 93(1):75--88.
[ bib ]
Keywords: Attribution Theory, Contrast
Hintzman, D. (1986).
"schema abstraction" in a multiple-trace memory model.
Psychological Review, 93:411--428.
[ bib ]
Hintzman, D. and Ludlam, G. (1980).
Differential forgetting of prototypes and old instances: Simulation
by an exemplar-based classification model.
Memory & Cognition, 4:378--382.
[ bib ]
Hirschfeld, L. (1996).
Race in the making: Cognition, culture, and the child's
construction of human kinds.
MIT Press.
[ bib ]
Hirschfeld, L. and Gelman, S. (1994).
Mapping the mind: Domain specificity in cognition and culture.
Cambridge University Press.
[ bib ]
Hoeffler, S. and Ariely, D. (1999).
Cosntructing stable preferences: A look into dimensions of
experience and their impact on preference stability.
Journal of Consumer Psychology, 8:113--139.
[ bib ]
Holyoak, K. J. and Thagard, P. (1997).
The analogical mind.
American Psychologist, 52(1):35--44.
[ bib |
http ]
The use of analogy in human thinking is examined from the perspective
of a multiconstraint theory, which postulates 3 basic types of constraints:
similarity, structure, and purpose. The operation of these constraints
is apparent in laboratory experiments on analogy and in naturalistic
settings, including politics, psychotherapy, and scientific research.
The multiconstraint theory has been implemented in detailed computational
simulations of the analogical human mind
Keywords: Human
Homa, D. (1984).
On the nature of categories, pages 49--94.
Academic Press.
[ bib ]
Homa, D., Rhoads, D., and Chambliss, D. (1979).
Evolution of conceptual structure.
Journal of Experimental Psychology: Human Learning and Memory,
5:11--23.
[ bib ]
Homa, D., Sterling, S., and Trepel, L. (1981).
Limitations of exemplar-based generalization and the abstraction of
categorical information.
Journal of Experimental Psychology: Human Learning and Memory,
7:418--439.
[ bib ]
Homa, D. and Vosburgh, R. (1976).
Category breadth and the abstraction of prototypical information.
Journal of Experimental Psychology: Human Learning and Memory,
2:322--330.
[ bib ]
Horgan, T. (1978).
The case against events.
Philosophical Review, 87:28--47.
[ bib ]
Horton, M. and Markman, E. (1980).
Developmental differences in the acquisition of basic and
superordinate categories.
Child Development, 51:708--719.
[ bib ]
Hough, M. S. and Pierce, R. S. (1989).
Exemplar verification for common and ad hoc categories in aphasia.
In Clinical Aphasiology, volume 19, chapter Exemplar
verification for common and ad hoc categories in aphasia, pages 139--150.
Pro-Ed, Austin.
[ bib ]
Hough, M. S., Pierce, R. S., Difilippo, M., and Pabst, M. J. (1997).
Access and organization of goal-derived categories after traumatic
brain injury.
Brain Injury, 11:801--814.
[ bib ]
Hu, Y., Wang, D., Pang, K., Xu, G., and Guo, J. (2014).
The effect of emotion and time pressure on risk decision-making.
Journal of Risk Research.
[ bib ]
Hull, C. (1920).
Quantitative aspects of the evolution of concepts.
Psychological Monographs, XXVIII:--.
[ bib ]
Hume, D. (1978 / 1739).
A treatise of human nature.
Oxford: Oxford University Press.
[ bib ]
Keywords: Human, Knowledge,Theory of
Huttenlocher, J. and Smiley, P. (1987).
Early word meanings: The case of object names.
Cognitive Psychology, 19:63--89.
[ bib ]
H�rmann, H. (1983).
The calculating listener, or How many are einige, mehrere and
ein paar (some, several, and a few)?, pages 221--234.
de Gruyter.
[ bib ]
Inhelder, B. and Piaget, J. (1964).
The early growth of logic in the child: Classification and
seriation.
Routledge and Kegan Paul.
[ bib ]
Jacoby, L. (1983).
Remembering the data: Analyzing interactive processes in reading.
Journal of Verbal Learning and Verbal Behavior, 22:485--508.
[ bib ]
Jacoby, L., Baker, J., and Brooks, L. (1989).
Episodic effects on picture identification: Implications for theories
of concept learning and theories of memory.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 15:275--281.
[ bib ]
Janczura, G. and Nelson, D. (1999).
Concept accessibility as the determinant of typicality judgments.
American Journal of Psychology, 112:1--19.
[ bib ]
Janssen, R. (2009).
Modeling the effect of item designs within the Rasch model.
In Embretson, S. and Roberts, J., editors, New directions in
psychological measurement with model-based approaches, chapter Modeling the
effect of item designs within the Rasch model, pages 227--245. American
Psychological Association, Washington, DC.
[ bib ]
Janssen, R., Schepers, J., and Peres, D. (2004).
Models with item and item group predictors.
In De Boeck, P. and Wilson, M., editors, Explanatory item
response models: A generalized linear and nonlinear approach, chapter Models
with item and item group predictors, pages 189--212. Springer, New York, NY.
[ bib ]
Janssen, R., Tuerlinckx, F., Meulders, M., and De Boeck, P. (2000).
A hierarchical irt model for criterion-referenced measurement.
Journal of Educational and Behavioral Statistics, 25:285--306.
[ bib ]
Jee, B. D. and Wiley, J. (2007).
How goals affect the organization and use of domain knowledge.
Memory & Cognition, 35:837--851.
[ bib ]
Johansen, M. K. and Palmeri, T. J. (2002).
Are there representational shifts during category learning?
Cognitive Psychology, 45:482--553.
[ bib ]
John, O., Hampson, S., and Goldberg, L. (1991).
The basic level of personality-trait hierarchies: Studies of trait
use and accessibility in different contexts.
Journal of Personality and Social Psychology, 60:348--361.
[ bib ]
Johnson, C. and Keil, F. (2000).
Explanatory understanding and conceptual combination.
In Keil, F. and Wilson, R., editors, Explanation and Cognition,
chapter 13, pages 328--359. MIT Press, Cambridge, Massachusetts.
[ bib ]
Keywords: Cognition
Johnson, K. and Mervis, C. (1994).
Microgenetic analysis of first steps in children's acquisition of
expertise on shorebirds.
Developmental Psychology, 30:418--435.
[ bib ]
Johnson, K., Scott, P., and Mervis, C. (1997).
Development of children's understanding of basic-subordinate
inclusion relations.
Developmental Psychology, 33:745--763.
[ bib ]
Johnson, K. E. and Eilers, A. T. (1998).
Effects of knowledge and development on subordinate level
categorization.
Cognitive Development, 13:515--545.
[ bib ]
Johnson, S. and Solomon, G. (1997).
Why dogs have puppies and cats have kittens: The role of birth in
young children's understanding of biological origins.
Child Development, 68:404--419.
[ bib ]
Johnson-Laird, P. (1983).
Mental models.
Erlbaum.
[ bib ]
Jolicoeur, P., Gluck, M., and Kosslyn, S. (1984).
Pictures and names: Making the connection.
Cognitive Psychology, 19:31--53.
[ bib ]
Jones, E. and Davis, K. (1965).
From acts to dispositions: the attribution process in person
perception.
In Berkowitz, L., editor, Advances in Experimental and Social
Psychology, volume 2, pages 219--266. Academic Press., New York.
[ bib ]
Jones, S. and Smith, L. (1993).
The place of perception in children's concepts.
Cognitive Development, 8:113--139.
[ bib ]
Jones, S., Smith, L., and Landau, B. (1991).
Object properties and knowledge in early lexical learning.
Child Development, 62:499--516.
[ bib ]
Juslin, P., Olsson, H., and Olsson, A. C. (2003).
Exemplar effects in categorization and multiple-cue judgment.
Journal of Experimental Psychology: General, 132:133--156.
[ bib ]
Kahneman, D. and Miller, D. (1986).
Norm theory: Comparing reality to its alternatives.
Psychological Review, 93:136 -- 153.
[ bib ]
Kahneman, D. and Tversky, A. (1982a).
On the study of statistical intuitions.
Cognition, 11(2):123--141.
[ bib |
http ]
The study of intuitions and errors in judgment under uncertainty is
complicated by several factors: discrepancies between acceptance
and application of normative rules; effects of content on the application
of rules; Socratic hints that create intuitions while testing them;
demand characteristics of within-subject experiments; subjects' interpretations
of experimental messages according to standard conversational rules.
The positive analysis of a judgmental error in terms of heuristics
may be supplemented by a negative analysis, which seeks to explain
why the correct rule is not intuitively compelling. A negative analysis
of non-regressive prediction is outlined
Keywords: Judgment
Kahneman, D. and Tversky, A. (1982b).
Variants of uncertainty.
Cognition, 11(2):143--157.
[ bib |
http ]
In contrast to formal theories of judgement and decision, which employ
a single notion of probability, psychological analyses of responses
to uncertainty reveal a wide variety of processes and experiences,
which may follow different rules. Elementary forms of expectation
and surprise in perception are reviewed. A phenomenological analysis
is described, which distinguishes external attributions of uncertainty
(disposition) from internal attributions of uncertainty (ignorance).
Assessments of uncertainty can be made in different modes, by focusing
on frequencies, propensities, the strength of arguments, or direct
experiences of confidence. These variants of uncertainty are associated
with different expressions in natural language; they are also suggestive
of competing philosophical interpretations of probability
Keywords: Language, Perception
Kalish, C. and Gelman, S. (1992).
On wooden pillows: Multiple classification and children's
category-based inductions.
Child Development, 63:1536--1557.
[ bib ]
Kalish, C. W. (1995).
Essentialism and graded membership in animal and artifact categories.
Memory & Cognition, 23:335--353.
[ bib ]
Keywords: Essentialism
Kalish, C. W. (2002).
Essentialist to some degree: Beliefs about the structure of natural
kind categories.
Memory & Cognition, 30:340--352.
[ bib ]
Kanji, G. K. (2006).
100 Statistical Tests.
Sage, London, UK, 3rd edition.
[ bib ]
Kaplan, A. and Murphy, G. (1999).
The acquisition of category structure in unsupervised learning.
Memory & Cognition, 27:699--712.
[ bib ]
Kaplan, A. S. and Murphy, G. L. (2000).
Category learning with minimal prior knowledge.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 26(4):829--846.
[ bib |
http ]
Katz, J. and Fodor, J. (1963).
The structure of a semantic theory.
Language, 39:170--210.
[ bib ]
Katz, N., Baker, E., and Macnamara, J. (1974).
What's in a name? a study of how children learn common and proper
names.
Child Development, 45:469--473.
[ bib ]
Kawamoto, A. (1993).
Nonlinear dynamics in the resolution of lexical ambiguity: A parallel
distributed processing account.
Journal of Memory and Language, 32:474--516.
[ bib ]
Keefe, R. and Smith, P. (1997).
Theories of vagueness, pages 1--57.
MIT Press.
[ bib ]
Keil, F. (1989).
Concepts, Kinds, and Cognitive Development.
MIT, Cambridge, MA.
[ bib ]
Keywords: Concepts
Keil, F. (1994).
The birth and nurturance of concepts by domains: The origins of
concepts of living things, pages 234--254.
Cambridge University Press.
[ bib ]
Keil, F. and Batterman, N. (1984).
A characteristic-to-defining shift in the development of word
meaning.
Journal of Verbal Learning and Verbal Behavior, 23:221--236.
[ bib ]
Keywords: Meaning
Keil, F. C. (2003).
Categorisation, causation and the limits of understanding.
Language and Cognitive Processes, 18:663 -- 692.
[ bib ]
Keil, F. C. (2006).
Explanation and understanding.
Annual Review of Psychology, 57:227 -- 254.
[ bib ]
Keil, F. C., Carter Smith, W., Simons, D. J., and Levin, D. T. (1998).
Two dogmas of conceptual empiricism: implications for hybrid models
of the structure of knowledge.
Cognition, 65(2-3):103--135.
[ bib |
http ]
Concepts seem to consist of both an associative component based on
tabulations of feature typicality and similarity judgments and an
explanatory component based on rules and causal principles. However,
there is much controversy about how each component functions in concept
acquisition and use. Here we consider two assumptions, or dogmas,
that embody this controversy and underlie much of the current cognitive
science research on concepts. Dogma 1: Novel information is first
processed via similarity judgments and only later is influenced by
explanatory components. Dogma 2: Children initially have only a similarity-based
component for learning concepts; the explanatory component develops
on the foundation of this earlier component. We present both empirical
and theoretical arguments that these dogmas are unfounded, particularly
with respect to real world concepts; we contend that the dogmas arise
from a particular species of empiricism that inhibits progress in
the study of conceptual structure; and finally, we advocate the retention
of a hybrid model of the structure of knowledge despite our rejection
of these dogmas
Keil, F. C., Greif, M. L., and Kerner, R. S. (2007).
A world apart: How concepts of the constructed world are different in
representation and in development.
In Margolis, E. and Laurence, S., editors, Creations of the
mind: Theories of artifacts and their representation, pages 232--245. Oxford
University Press, New York.
[ bib ]
Keil, F. C. and Wilson, R. A. (2000).
Explaining explanation.
In Keil, F. C. and Wilson, R. A., editors, Explanation and
Cognition, number 1, chapter 1, pages 1--18. MIT, Cambridge, MA.
[ bib ]
Keywords: Explanation, Cognition
Kelemen, D. (1999a).
Functions, goals and intentions: Childrens teleological reasoning
about objects.
Trends in Cognitive Sciences, 12:461 -- 468.
[ bib ]
Kelemen, D. (1999b).
The scope of teleological thinking in preschool children.
Cognition, 70:241 -- 272.
[ bib ]
Kelemen, D. and Bloom, P. (1994).
Domain-specific knowledge in simple categorization tasks.
Psychonomic Bulletin & Review, 1:390--395.
[ bib ]
Kelley, H. H. (1967).
Attribution theory in social psychology.
In Levine, D., editor, Nebraska Symposium on Motivation,
volume 15, pages 192--238. University of Nebraska Press, Lincoln.
[ bib ]
Kelley, H. H. (1972).
Attribution theory in social psychology.
In Jones, E., Kanouse, D., Kelley, H., Nisbett, R., Valins, S., and
Weiner, B., editors, Attribution: Perceiving the causes of behaviour.
General Learning Press, Morristown, NJ.
[ bib ]
"THE THEORY DESCRIBES PROCESSES THAT OPERATE AS IF THE INDIVIDUAL
WERE MOTIVATED TO ATTAIN A COGNITIVE MASTERY OF THE CAUSAL STRUCTURE
OF HIS ENVIRONMENT." THE 4 CRITERIA CONSIDERED RELEVANT TO THE ATTRIBUTION
PROCESS ARE DISTINCTIVENESS, CONSISTENCY OVER TIME, CONSISTENCY OVER
MODALITY, AND CONSENSUS. THE "ILLUSION OF FREEDOM" IN THE FACE OF
OUR SOCIETY'S INSISTENCE ON "CONFORMITY OF BEHAVIOR" IS 1 PROBLEM
THAT CAN BE CONSIDERED WITHIN THE FRAMEWORK OF ATTRIBUTION THEORY.
COMMENTS RELATING ATTRIBUTION THEORY TO MOTIVATIONAL BLOCKS IN CLASSROOM
LEARNING ARE MADE BY I. KATZ. (PsycINFO Database Record (c) 2004
APA, all rights reserved)
Kelley, H. H. and Michela, J. L. (1980).
Attribution theory and research.
Annual Review of Psychology, 31:457--501.
[ bib |
http ]
Focuses on the wide use of attribution theory in psychological research.
Difference between other-perception and self-perception; Information
on the three types of antecedents; Revelation that consistency and
distinctiveness are important parameters of individual experience.
Keywords: MATHEMATICAL models; SELF-perception; THEORY; PSYCHOLOGICAL literature;
PSYCHOLOGY -- Research
Kelly, M., Bock, J., and Keil, F. (1986).
Prototypicality in a linguistic context: Effects on sentence
structure.
Journal of Memory and Language, 25:59--74.
[ bib ]
Kemler, D. (1981).
New issues in the study of infant categorization: A reply to husaim
& cohen.
Merrill-Palmer Quarterly, 27:457--463.
[ bib ]
Kemler Nelson, D. (1995).
Principle-based inferences in young children's categorization:
Revisiting the impact of function on the naming of artifacts.
Cognitive Development, 10:347--380.
[ bib ]
Kendler, K. S., Ochs, A. L., Gorman, A. M., Hewitt, J. K., Ross, D. E., and
Mirsky, A. F. (1991).
The structure of schizotypy: A pilot multitrait twin study.
Psychiatry Research, 36:19--36.
[ bib ]
Keysar, B., Barr, D., Balin, J., and Brauner, J. (2000).
Taking perspective in conversation: The role of mutual knowledge in
comprehension.
Psychological Science, 11:32--38.
[ bib ]
Kiang, M. and Kutas, M. (2005).
Association of schizotypy with semantic processing differences: An
event-related brain potential study.
Schizophrenia Research, 77:329--342.
[ bib ]
Kiang, M. and Kutas, M. (2006).
Abnormal typicality of responses on a category fluency task in
schizotypy.
Psychiatry Research, 145:119--126.
[ bib ]
Kiang, M., Kutas, M., Light, G. A., and Braff, D. L. (2007).
Electrophysiological insights into conceptual disorganization in
schizophrenia.
Schizophrenia Research, 92:225--236.
[ bib ]
Kiang, M., Kutas, M., Light, G. A., and Braff, D. L. (2008).
An event-related brain potential study of direct and indirect
semantic priming in schizophrenia.
American Journal of Psychiatry, 165:74--81.
[ bib ]
Kim, J. (1976/1996).
Events as property exemplifications.
In Casati, R. and Varzi, A. C., editors, Events, pages
117--135. Aldershot, Dartmouth.
Reprinted from Action Theory, pp. 159-77, by M. Brand and D. Walton
(eds.), Dordrecht: Reidel.
[ bib ]
Kim, J.-S. and Bolt, D. M. (2007).
Estimating item response theory models using Markov Chain Monte
Carlo methods.
Instructional Topics in Educational Measurement, 26:38--51.
[ bib ]
Kim, S. and Murphy, G. L. (2011).
Ideals and category typicality.
Journal of Experimental Psychology: Learning, Memory, &
Cognition, 37:1092--1112.
[ bib ]
Kitcher, P. (1922).
Explanation, conjunction, and unification.
Journal of Philosophy, 73:207--212.
[ bib ]
Klein, B. V. E. (1980).
What should we expect of a theory of explanation?
In PSA: Proceedings of the Biennial Meeting of the Philosophy of
Science Association, volume 1, pages 319--328, Chicago, IL. The Philosophy
of Science Association, The University of Chicago Press.
[ bib ]
Keywords: Explanation, Metatheory
Klein, D. E. and Murphy, G. L. (2001).
The representation of polysemous words.
Journal of Memory and Language, 45:259--282.
[ bib ]
Klein, D. E. and Murphy, G. L. (2002).
Paper has been my ruin: Conceptual relations of polysemous senses.
Journal of Memory and Language, 47:548--570.
[ bib ]
Klibanoff, R. and Waxman, S. (2000).
Basic level object categories support the acquisition of novel
adjectives: Evidence from preschool-aged children.
Child Development, 71:649--659.
[ bib ]
Knapp, A. and Anderson, J. (1984).
Theory of categorization based on distributed memory storage.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 10:616--637.
[ bib ]
Kolers, P. and Ostry, D. (1974).
Time course of loss of information regarding pattern analyzing
operations.
Journal of Verbal Learning and Verbal Behavior, 13:599--612.
[ bib ]
Kooij, J. G. (1971).
Ambiguity in natural language.
North Holland, Amsterdam, The Netherlands.
[ bib ]
Kornblith, H. (1993).
Inductive inference and its natural ground: An essay in
naturalistic epistemology.
MIT Press.
[ bib ]
Keywords: Epistemology, Inference
Krascum, R. and Andrews, S. (1998).
The effects of theories on children's acquisition of
family-resemblance categories.
Child Development, 69:333--346.
[ bib ]
Krauss, R. and Weinheimer, S. (1966).
Concurrent feedback, confirmation, and the encoding of referents in
verbal communication.
Journal of Personality and Social Psychology, 4:343--346.
[ bib ]
Kripke, S. (1980).
Naming and Necessity.
Harvard U.P.
[ bib ]
Kruschke, J. (1992).
ALCOVE: An exemplar-based connectionist model of category
learning.
Psychological Review, 99:22--44.
[ bib ]
Kruschke, J. (1993).
Three principles for models of category learning, pages 57--90.
Academic Press.
[ bib ]
Kruschke, J. (1996).
Base rates in category learning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 22:3--26.
[ bib ]
Kruschke, J. and Johansen, M. (1999).
A model of probabilistic category learning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 25:1083--1119.
[ bib ]
Kuncel, R. B. and Kuncel, N. R. (1995).
Response process models: Toward an integration of
cognitive-processing models, psychometric models, latent-trait theory, and
self-schemas.
In Shrout, P. E. and Fiske, S. T., editors, Personality
research, methods, and theory, chapter Response process models: Toward an
integration of cognitive-processing models, psychometric models, latent-trait
theory, and self-schemas, pages 183--200. Erlbaum, Hillsdale, NJ.
[ bib ]
Kunda, Z., Miller, D., and Claire, T. (1990).
Combining social concepts: The role of causal reasoning.
Cognitive Science, 14:551--577.
[ bib ]
Kunda, Z. and Thagard, P. (1996).
Forming impressions from stereotypes, traits, and behaviors: A
parallel-constraint-satisfaction theory.
Psychological Review, 103(2):284--308.
[ bib |
http ]
The authors propose a parallel-constraint-satisfaction theory of impression
formation that assumes that social stereotypes and individuating
information such as traits or behaviors constrain each other's meaning
and jointly influence impressions of individuals. Building on models
of text comprehension (W. Kintsch, 1988), the authors describe a
connectionist model that can account for the major findings on how
stereotypes affect impressions of individuals in the presence of
different kinds of individuating information; how stereotypes, behaviors,
and traits affect each other's meaning; and how multiple stereotypes
jointly affect impressions. Most of these findings can be modeled
by constraint networks, which suggests that they may be due to relatively
automatic processes that require little conscious inference. The
authors also point to a small number of phenomena that involve more
controlled processes. The advantages of the authors' parallel model
over serial models are discussed
Keywords: Inference, Meaning
Lakoff, G. (1973).
Hedges: A study in meaning criteria and the logic of fuzzy
concepts.
Journal of Philosophical Logic, 2:458--508.
[ bib ]
Lakoff, G. (1987).
Women, fire, and dangerous things: What categories reveal about
the mind.
University of Chicago Press, Chicago, IL.
[ bib ]
Lakoff, G. and Johnson, M. (1980).
The metaphorical structure of the human conceptual system.
Cognitive Science, 4:195--208.
[ bib ]
Lakoff, G. and Turner, M. (1989).
More than cool reason: A field guide to poetic metaphor.
University of Chicago Press, Chicago, IL.
[ bib ]
Lamberts, K. (1995).
Categorization under time pressure.
Journal of Experimental Psychology: General, 124:161--180.
[ bib ]
Lamberts, K. (1997).
Knowledge, concept and categories, pages 371--403.
Psychology Press.
[ bib ]
Keywords: Concepts, Knowledge
Lamberts, K. (2000).
Information-accumulation theory of speeded categorization.
Psychological Review, 107:227--260.
[ bib ]
Polysemous words have different but related meanings (senses), such
as paper meaning a newspaper or writing material. Six experiments
examined the similarity of word senses using categorization and
inference tasks. The experiments found that subjects did not categorize
together phrases that used a polysemous word in different senses,
though they did when the word was used in the same sense. Different
senses of a word were categorized together no more than 20
time, only slightly more often than different meanings of homonyms.
Pre- exposing Subjects to a polysemous relation did riot increase
categorization of word senses that had that relation. Finally, induction
from one sense of a word to a different sense was also weak. The
results are consistent with the view that polysemous senses are
represented separately, often with little semantic overlap, helping
to explain previous results that using a word. in one sense interferes
with using it in another sense, even if the senses are related.
Implications for lexical representations are discussed. (C) 2002
Elsevier Science (USA). All rights reserved.
Landau, B., Smith, L., and Jones, S. (1988).
The importance of shape in early lexical learning.
Cognitive Development, 3:299--321.
[ bib ]
Landauer, T. and Dumais, S. (1997).
A solution to plato's problem: The latent semantic analysis theory of
acquisition, induction, and representation of knowledge.
Psychological Review, 104:211--240.
[ bib ]
Landauer, T., Foltz, P., and Laham, D. (1998).
Introduction to latent semantic analysis.
Discourse Processes, 25:259--284.
[ bib ]
Larochelle, S., Richard, S., and Soulières, I. (2000).
What some effects might not be: The time to verify membership in
"well-defined" categories.
The Quarterly Journal of Experimental Psychology, 53A:929--961.
[ bib ]
Lasky, R. (1974).
The ability of six-year-olds, eight-year-olds, and adults to abstract
visual patterns.
Child Development, 45:626--632.
[ bib ]
Lassaline, M. (1996).
Structural alignment in induction and similarity.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 22:754--770.
[ bib ]
Lassaline, M. and Murphy, G. (1996).
Induction and category coherence.
Psychonomic Bulletin & Review, 3:95--99.
[ bib ]
Lassaline, M., Wisniewski, E., and Medin, D. (1992).
The basic level in artificial and natural categories: Are all
basic levels created equal?, pages --.
Elsevier.
[ bib ]
Lassaline, M. E. and Murphy, G. L. (1998).
Alignment and category learning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 24(1):144--160.
[ bib |
http ]
Lee, M. D. (2008).
Three case studies in the Bayesian analysis of cognitive models.
Psychonomic Bulletin & Review, 15:1--15.
[ bib ]
Lee, M. D. (2014).
The Bayesian implementation and evaluation of heuristic
decision-making models.
Manuscript submitted for publication.
[ bib ]
Lee, M. D. and Newell, B. R. (2011).
Using hierarchical Bayesian methods to examine the tools of
decision-making.
Judgment and Decision Making, 6:832--842.
[ bib ]
Lee, M. D. and Webb, M. R. (2005).
Modeling individual differences in cognition.
Psychonomic Bulletin & Review, 12:605--621.
[ bib ]
Lee, M. D. and Wetzels, R. (2010).
Individual differences in attention during category learning.
In Catrambone, R. and Ohlsson, S., editors, Proceedings of the
32nd Annual Conference of the Cognitive Science Society, pages
387--392. Cognitive Science Society, Austin, TX.
[ bib ]
Lehrer, A. (1990).
Polysemy, conventionality, and the structure of the lexicon.
Cognitive Linguistics, 1:207--246.
[ bib ]
Lehrer, A. and Kittay, E. F. (1992).
Frames, fields and contrasts.
Erlbaum, Hillsdale, NJ.
[ bib ]
Lesgold, A. (1984).
Acquiring expertise.
W. H. Freeman.
[ bib ]
Levi, J. (1978).
The syntax and semantics of complex nominals.
Academic Press.
[ bib ]
Levy, D. K. (2003).
Concepts, language and privacy: An argument "vaguely viennese in
provenance".
Language and Cognitive Processes, 18:693 -- 723.
[ bib ]
Lewis, D. (1911).
Causation.
Journal of Philosophy, 70: 556-567:--5677.
[ bib ]
THE BOOK CONSISTS OF REPRINTS OF FIFTEEN PAPERS IN ONTOLOGY, PHILOSOPHY
OF MIND, AND PHILOSOPHY OF LANGUAGE. THE PAPERS ARE UNCHANGED FROM
THEIR ORIGINAL FORM, BUT NEW POSTSCRIPTS HAVE BEEN ADDED TO EIGHT
OF THEM
Lewis, D. (1986a).
Causal explanation.
In Ruben, D.-H., editor, Explanation, pages 182--206. Oxford
University Press, Oxford, UK.
[ bib ]
Keywords: Explanation, Causal Explanation
Lewis, D. (1986b).
On the plurality of worlds.
Blackwell, Oxford, UK.
[ bib ]
Keywords: Existence - Philosophical perspectives, Modality (Theory of knowledge),
Ontology, Plurality of worlds, Realism
Lewis, D. (1986c).
Philosophical Paper Vol 2.
OXFORD-UNIV-PR.
[ bib ]
THE BOOK CONSISTS OF TWO NEW PAPERS AND ELEVEN REPRINTED PAPERS ON
TOPICS CONCERNING COUNTERFACTUALS, PROBABILITY, CAUSATION, AND RELATED
MATTERS. THE REPRINTED PAPERS ARE UNCHANGED FROM THEIR ORIGINAL FORM,
BUT NEW POSTSCRIPTS HAVE BEEN ADDED TO SIX OF THEM
Keywords: CAUSATION, CONDITIONAL, CONDITIONAL PROBABILITY, COUNTERFACTUAL, DECISION,
DEPENDENCY, PHILOSOPHY, PROBABILITY
Lewis, D. (1988).
Desire as belief.
Mind, 97: 323-332:--3322.
[ bib ]
Keywords: BELIEF, DECISION THEORY, DESIRE, LOGIC
Li, F., Cohen, A. S., Kim, S.-H., and Cho, S.-J. (2009).
Model selection methods for mixture dichotomous IRT models.
Applied Psychological Measurement, 33:353--373.
[ bib ]
Lin, E. and Murphy, G. (1997a).
The effects of background knowledge on object categorization and part
detection.
Journal of Experimental Psychology: Human Perception and
Performance, 23:1153--1169.
[ bib ]
Lin, E., Murphy, G., and Shoben, E. (1997).
The effect of prior processing episodes on basic-level superiority.
Quarterly Journal of Experimental Psychology, 50A:25--48.
[ bib ]
Lin, E. L. and Murphy, G. L. (1997b).
Effects of background knowledge on object categorization and part
detection.
Journal of Experimental Psychology: Human Perception and
Performance, 23(4):1153--1169.
[ bib |
http ]
Keywords: Knowledge
Lin, E. L. and Murphy, G. L. (2001).
Thematic relations in adults' concepts.
Journal of Experimental Psychology: General, 130(1):3--28.
[ bib |
http ]
Keywords: Adult, Concepts
Lin, P.-J., Schwanenflugel, P. J., and Wisenbaker, J. M. (1990).
Category typicality, cultural familiarity, and the development of
category knowledge.
Developmental Psychology, 26:805--813.
[ bib ]
Lipe, M. G. (1991).
Counterfactual reasoning as a framework for attribution theories.
Psychological bulletin, 109(3):456.
[ bib |
http ]
Proposes a model based on the two proxies often substituted for counterfactual
information (on which all of the major attribution theories are based)
since counterfactual information is difficult to obtain. Covariation
data and information regarding alternative explanations; Framework
for understanding the use and success of Kelley's analysis of variance
model and others' models; Understanding of the fundamental attribution
error and actor-observer attributional differences.
Keywords: PSYCHOLOGY -- Research
Lipshitz, R. (2000).
Two cheers for bounded rationality.
Behavioral and Brain Sciences, 23:756--757.
[ bib ]
Lipton, P. (1987).
A real contrast.
Analysis, 47:207--208.
[ bib ]
A RECENT ACCOUNT OF THE EXPLANATION OF CONTRASTIVE FACTS HOLDS THAT
TO EXPLAIN WHY "E" OCCURRED RATHER THAN "F" IS SIMPLY TO EXPLAIN
WHY "E" OCCURRED AND TO SHOW THAT "E" PREVENTED "F" FROM OCCURRING.
THIS IS SHOWN TO BE INCORRECT. IT FAILS TO ACCOUNT FOR CASES WHERE
THE CONTRAST EXPLAINED REPRESENTS A CHOICE, A SURPRISING OUTCOME,
OR AN UNEXPECTED DIFFERENCE, AND IT IGNORES THE FACT THAT IT IS USUALLY
EASIER TO EXPLAIN WHY "E" RATHER THAN "F" THAN IT IS TO EXPLAIN WHY
"E SIMPLICITER".
Keywords: explanation, fact, language
Lipton, P. (2004).
Inference to the best explanation.
Routledge, 2nd edition edition.
[ bib ]
How do we go about weighing evidence, testing hypotheses and making
inferences? According to the model of Inference to the Best Explanation,
we work out what to infer from the evidence by thinking about what
would actually explain that evidence, and we take the ability of
a hypothesis to explain the evidence as a sign that the hypothesis
is correct. In Inference to the Best Explanation, Peter Lipton gives
this important and influential idea the development and assessment
it deserves. The second edition has been substantially enlarged and
reworked, with a new chapter on the relationship between explanation
and Bayesianism, and an extension and defence of the account of contrastive
explanation. (publisher, edited)
Keywords: bayesianism, explanation, induction, inference, science, truth
Little, D. R. and Lewandowsky, S. (2009).
Beyond nonutilization: Irrelevant cues can gate learning in
probabilistic categorization.
Journal of Experimental Psychology: Human Perception and
Performance, 35:530--550.
[ bib ]
Locke, E. A. and Latham, G. P. (1990).
A theory of goal-setting theory and task performance.
Prentice-Hall, Englewood Cliffs, NJ.
[ bib ]
Loken, B. and Ward, J. (1990).
Alternative approaches to understanding the determinants of
typicality.
Journal of Consumer Research, 17:111--126.
[ bib ]
Lombrozo, T. (2006).
The structure and function of explanations.
Trends in Cognitive Sciences, 10(10):464 -- 470.
[ bib ]
Lombrozo, T. and Carey, S. (2006).
Functional explanation and the function of explanation.
Cognition, 99:167--204.
[ bib ]
Lopez, A., Atran, S., Coley, J. D., Medin, D. L., and Smith, E. E. (1997).
The tree of life: Universal and cultural features of folkbiological
taxonomies and inductions.
Cognitive Psychology, 32(3):251--295.
[ bib |
http ]
Two parallel studies were performed with members of very different
cultures--industrialized American and traditional Itzaj-Mayan--to
investigate potential universal and cultural features of folkbiological
taxonomies and inductions. Specifically, we examined how individuals
organize natural categories into taxonomies, and whether they readily
use these taxonomies to make inductions about those categories. The
results of the first study indicate that there is a cultural consensus
both among Americans and the Itzaj in their taxonomies of local mammal
species, and that these taxonomies resemble and depart from a corresponding
scientific taxonomy in similar ways. However, cultural differences
are also shown, such as a greater differentiation and more ecological
considerations in Itzaj taxonomies. In a second study, Americans
and the Itzaj used their taxonomies to guide similarity- and typicality-based
inductions. These inductions converge and diverge crossculturally
and regarding scientific inductions where their respective taxonomies
do. These findings reveal some universal features of folkbiological
inductions, but they also reveal some cultural features such as diversity-based
inductions among Americans, and ecologically based inductions among
the Itzaj. Overall, these studies suggest that while building folkbiological
taxonomies and using them for folkbiological inductions is a universal
competence of human cognition there are also important cultural constraints
on that competence
Keywords: Cognition, Human, Induction
Luce, R. D. (1959).
Individual choice behaviour.
Wiley, New York, NY.
[ bib ]
Lucy, J. (1992).
Language diversity and thought: A reformulation of the
linguistic relativity hypothesis.
Cambridge University Press.
[ bib ]
Lund, K. and Burgess, C. (1996).
Producing high-dimensional semantic spaces from lexical
co-occurrence.
Behavior Research Methods, Instruments, & Computers,
28:203--208.
[ bib ]
Lunn, D. J., Thomas, A., Best, N., and Spiegelhalter, D. (2000).
WinBUGS: A Bayesian modelling framework: Concepts, structure, and
extensibility.
Statistics and Computing, 10:325--337.
[ bib ]
Luria, A. (1976).
Cognitive development: Its cultural and social foundations.
MIT Press.
[ bib ]
Lynch, E. B., Coley, J. B., and Medin, D. L. (2000).
Tall is typical: Central tendency, ideal dimensions, and graded
category structure among tree experts and novices.
Memory & Cognition, 28:41--50.
[ bib ]
L�pez, A., Atran, S., Coley, J., Medin, D., and Smith, E. (1997).
The tree of life: Universal and cultural features of folkbiological
taxonomies and inductions.
Cognitive Psychology, 32:251--295.
[ bib ]
L�pez, A., Gelman, S., Gutheil, G., and Smith, E. (1992).
The development of category-based induction.
Child Development, 63:1070--1090.
[ bib ]
Mackie, J. L. (1974).
The Cement of the Universe.
Clarendon Press, Oxford.
[ bib ]
Macnamara, J. (1986).
A border dispute: The place of logic in psychology.
MIT Press.
[ bib ]
Maddox, W. (1999).
On the dangers of averaging across observers when comparing decision
bound models and generalized context models of categorization.
Perception & Psychophysics, 61:354--374.
[ bib ]
Madole, K. and Cohen, L. (1995).
The role of object parts in infants' attention to form-function
correlations.
Developmental Psychology, 31:637--648.
[ bib ]
Maij-de Meij, A. M., Kelderman, H., and van der Flier, H. (2008).
Fitting a mixture item response theory model to personality
questionnaire data: Characterizing latent classes and investigating
possibilities for improving prediction.
Applied Psychological Measurement, 32:611--631.
[ bib ]
Mair, P. and Hatzinger, R. (2007a).
CML based estimation of extended rasch models with the eRm
package in R.
Psychology Science, 49:26--43.
[ bib ]
Mair, P. and Hatzinger, R. (2007b).
Extended Rasch modeling: The eRm package for the application of
IRT models in R.
Journal of Statistical Software, 20:1--20.
[ bib ]
Malt, B. (1989).
An on-line investigation of prototype and exemplar strategies in
classification.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 15:539--555.
[ bib ]
Malt, B. (1991).
Word meaning and word use, pages 37--70.
Erlbaum.
[ bib ]
Keywords: Meaning
Malt, B. (1994).
Water is not H2O.
Cognitive Psychology, 27:41--70.
[ bib ]
Malt, B. (1995).
Category coherence in cross-cultural perspective.
Cognitive Psychology, 29:85--148.
[ bib ]
Malt, B., Ross, B., and Murphy, G. (1995).
Predicting features for members of natural categories when
categorization is uncertain.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 21:646--661.
[ bib ]
Malt, B., Sloman, S., Gennari, S., Shi, M., and Wang, Y. (1999).
Knowing versus naming: Similarity and the linguistic categorization
of artifacts.
Journal of Memory and Language, 40:230--262.
[ bib ]
Malt, B. and Smith, E. (1984).
Correlated properties in natural categories.
Journal of Verbal Learning and Verbal Behavior, 23:250--269.
[ bib ]
Malt, B. C. (1990).
Features and beliefs in the mental representation of categories.
Journal of Memory and Language, 29:289--315.
[ bib ]
Malt, B. C. and Johnson, E. C. (1992).
Do artifact concepts have cores?
Journal of Memory and Language, 31:195--217.
[ bib ]
Keywords: Concepts
Malt, B. C. and Sloman, S. A. (2004).
Conversation and convention: Enduring influences on name choice for
common objects.
Memory & Cognition, 32:1346--1354.
[ bib ]
The name chosen for an object is influenced by both short-term history
(e.g., speaker-addressee pacts) and long-term history (e.g., the
language's naming pattern for the domain). But these influences must
somehow be linked. We propose that names adopted through speaker-addressee
collaboration have influences that carry beyond the original context.
To test this hypothesis, we adapted the standard referential communication
task. The first director of each matching session was a confederate
who introduced one of two possible names for each object. The director
role then rotated to naive participants. The participants later rated
name preference for the introduced and alternative names for each
object. They also rated object typicality or similarity to each named
category. The name that was initially introduced influenced later
name use and preference, even for participants who had not heard
the name from the original director. Typicality and similarity showed
lesser effects from the names originally introduced. Name associations
built in one context appear to influence retrieval and use of names
in other contexts, but they have reduced impact on nonlinguistic
object knowledge. These results support the notion that stable conventions
for object names within a linguistic community may arise from local
interactions, and they demonstrate how different populations of speakers
may come to have a shared under-standing of objects' nonlinguistic
properties but different naming patterns.
Malt, B. C. and Sloman, S. A. (2007).
Artifact categorization: The good, the bad, and the ugly.
In Margolis, E. and Laurence, S., editors, Creations of the
mind: Theories of artifacts and their representation, pages 85--123. Oxford
University Press, New York.
[ bib ]
Malt, B. C. and Smith, E. E. (1982).
The role of familiarity in determining typicality.
Memory & Cognition, 10:69--75.
[ bib ]
Mandel, D. R., Lehman, and R, D. (1996).
Counterfactual thinking and ascriptions of cause and preventability.
Journal of Personality and Social Psychology, 71:450 -- 463.
[ bib ]
Mandler, J. (1992).
How to build a baby: Ii. conceptual primitives.
Psychological Review, 99:587--604.
[ bib ]
Mandler, J. (1998).
Representation, pages 255--308.
Wiley.
[ bib ]
Mandler, J., Bauer, P., and McDonough, L. (1991).
Separating the sheep from the goats: Differentiating global
categories.
Cognitive Psychology, 23:263--298.
[ bib ]
Mandler, J. and McDonough, L. (1993).
Concept formation in infancy.
Cognitive Development, 8:291--318.
[ bib ]
Mandler, J. and McDonough, L. (1996).
Drinking and driving don't mix: Inductive generalization in infancy.
Cognition, 59:307--335.
[ bib ]
Marewski, J. N. and Schooler, L. J. (2011).
Cognitive niches: An ecological model of strategy selection.
Psychological Review, 118:393--437.
[ bib ]
Margolis, E. (1994).
A reassessment of the shift from the classical theory of concepts to
prototype theory.
Cognition, 51:73--89.
[ bib ]
Keywords: Concepts
Margolis, J. (1970).
Puzzles regarding explanation by reason and explanation by causes.
Journal of Philosophy, 67(7):187 -- 195.
[ bib ]
Markman, A. (1999).
Knowledge representation.
Erlbaum.
[ bib ]
Markman, A. and Gentner, D. (1993).
Structural alignment during similarity comparisons.
Cognitive Psychology, 25:431--467.
[ bib ]
Markman, A. and Makin, V. (1998).
Referential communication and category acquisition.
Journal of Experimental Psychology: General, 127:331--354.
[ bib ]
Markman, A. and Wisniewski, E. (1997).
Similar and different: The differentiation of basic-level categories.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 23:54--70.
[ bib ]
Markman, E. (1985).
Why superordinate category terms can be mass nouns.
Cognition, 19:31--53.
[ bib ]
Markman, E. (1989).
Categorization and naming in children: Problems of induction.
MIT Press.
[ bib ]
Markman, E. and Callanan, M. (1984).
An analysis of hierarchical classification, pages 325--365.
Erlbaum.
[ bib ]
Markman, E., Cox, B., and Machida, S. (1981).
The standard object-sorting task as a measure of conceptual
organization.
Developmental Psychology, 17:115--117.
[ bib ]
Markman, E., Horton, M., and McLanahan, A. (1980).
Classes and collections: Principles of organization in the learning
of hierarchical relations.
Cognition, 8:227--241.
[ bib ]
Markman, E. and Hutchinson, J. (1984).
Children's sensitivity to constraints on word meaning: Taxonomic vs
thematic relations.
Cognitive Psychology, 16:1--27.
[ bib ]
Markson, L. and Bloom, P. (1997).
Evidence against a dedicated system for word learning in children.
Nature, 385:813--815.
[ bib ]
Martin, J. D. and Billman, D. O. (1994).
Acquiring and combining overlapping concepts.
Machine Learning, 16:121--155.
[ bib ]
Martin, R. C. and Caramazza, A. (1980).
Classification in well-defined and ill-defined categories: Evidence
for common processing strategies.
Journal of Experimental Psychology: General, 109:320--353.
[ bib ]
Massey, C. and Gelman, R. (1988).
Preschoolers' ability to decide whether a photographed unfamiliar
object can move itself.
Developmental Psychology, 24:307--317.
[ bib ]
Mata, R., Schooler, L. J., and Rieskamp, J. (2007).
The aging decision maker: Cognitive aging and the adaptive selection
of decision strategies.
Psychology and Aging, 22:796--810.
[ bib ]
Mayr, E. (1982).
The growth of biological thought: Diversity, evolution, and
inheritance.
Harvard University Press.
[ bib ]
McCarrell, N. and Callanan, M. (1995).
Form-function correspondences in children's inference.
Child Development, 66:532--546.
[ bib ]
McClelland, J. and Rumelhart, D. (1985).
Distributed memory and the representation of general and specific
information.
Journal of Experimental Psychology: General, 114:159--188.
[ bib ]
McCloskey, M. and Glucksberg, S. (1979).
Decision processes in verifying category membership statements:
Implications for models of semantic memory.
Cognitive Psychology, 11:1--37.
[ bib ]
McCloskey, M. E. (1980).
The stimulus familiarity problem in semantic memory research.
Journal of Verbal Learning and Verbal Behavior, 19:485--502.
[ bib ]
McCloskey, M. E. and Glucksberg, S. (1978).
Natural categories: Well defined or fuzzy sets?
Memory & Cognition, 6:462--472.
[ bib ]
McFalls, E. L. and Schwanenflugel, P. J. (2002).
The influence of contextual constraints on recall for words within
sentences.
American Journal of Psychology, 115:67--88.
[ bib ]
McGill, A. (1989).
Context effects in judgments of causation.
Journal of Personality and Social Psychology, 57:189--200.
[ bib ]
McGill, A. L. (1990).
Conjunctive explanations: The effect of comparison of the target
episode to a contrasting background instance.
Social Cognition, 8(4):362--382.
[ bib ]
McGill, A. L. (1991a).
Conjunctive explanations: Accounting for events that differ from
several norms.
Journal of Experimental Social Psychology, 27(6):527--549.
[ bib ]
McGill, A. L. (1991b).
The influence of the causal background on the selection of causal
explanations.
British Journal of Social Psychology, 30:79--87.
[ bib ]
McGill, A. L. (2002).
Alignable and nonalignable differences in causal explanations.
Memory & Cognition, 30(3):456 -- 468.
[ bib ]
McGill, A. L. and Klein, J. G. (1993).
Contrastive and counterfactual reasoning in causal judgment.
Journal of Personality and Social Psychology, 64(6):897--905.
[ bib ]
The present research addressed differences in the use of covariation
information implied by counterfactual reasoning, which focuses on
the question ”Would the event Y have occurred if the candidate X
had not?” and contrastive reasoning, which involves comparing the
target episode to contrasting background instances and noting distinctive
features. Two experiments test hypotheses regarding the use of counterfactual
and contrastive thinking under different conditions. Findings suggest
that when no candidate has been identified, people are more likely
to engage in contrastive thinking, but they may engage in counterfactual
thinking when they are asked to evaluate a specific candidate.
McKoon, G. and Ratcliff, R. (1988).
Contextually relevant aspects of meaning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 13:331--343.
[ bib ]
McLaughlin, P. (2001).
What Functions Explain: Functional Explanation and
Self-Reproducing Systems.
Cambridge University Press, Cambridge, UK.
[ bib ]
McRae, K., de Sa, V., and Seidenberg, M. (1997).
On the nature and scope of featural representations of word meaning.
Journal of Experimental Psychology: General, 126:99--130.
[ bib ]
Medin, D. (1983).
Structural principles of categorization, pages 203--230.
Erlbaum.
[ bib ]
Medin, D., Altom, M., Edelson, S., and Freko, D. (1982).
Correlated symptoms and simulated medical classification.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 8:37--50.
[ bib ]
Medin, D. and Bettger, J. (1994).
Presentation order and recognition of categorically related examples.
Psychonomic Bulletin & Review, 1:250--254.
[ bib ]
Medin, D., Dewey, G., and Murphy, T. (1983).
Relationships between item and category learning: Evidence that
abstraction is not automatic.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 9:607--625.
[ bib ]
Medin, D. and Edelson, S. (1988).
Problem structure and the use of base-rate information from
experience.
Journal of Experimental Psychology: General, 117:68--85.
[ bib ]
Medin, D., Goldstone, R., and Gentner, D. (1993).
Respects for similarity.
Psychological Review, 100:254--278.
[ bib ]
Medin, D. and Schaffer, M. (1978).
Context theory of classification learning.
Psychological Review, 85:207--238.
[ bib ]
Medin, D. and Schwanenflugel, P. (1981).
Linear separability in classification learning.
Journal of Experimental Psychology: Human Learning and Memory,
7:355--368.
[ bib ]
Medin, D. and Shoben, E. (1988).
Context and structure in conceptual combination.
Cognitive Psychology, 20:158--190.
[ bib ]
Medin, D. and Smith, E. (1981).
Strategies and classification learning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 7:241--253.
[ bib ]
Medin, D., Wattenmaker, W., and Hampson, S. (1987).
Family resemblance, conceptual cohesiveness, and category
construction.
Cognitive Psychology, 19:242--279.
[ bib ]
Medin, D. L. (1989).
Concepts and conceptual structure.
American Psychologist, 44:1469--1481.
[ bib ]
Research and theory on categorization and conceptual structure have
recently undergone two major shifts. The first shift is from the
assumption that concepts have defining properties (the classical
view) to the idea that concept representations may be based on properties
that are only characteristic or typical of category examples (the
probabilistic view). Both the probabilistic view and the classical
view assume that categorization is driven by similarity relations.
A major problem with describing category structure in terms of similarity
is that the notion of similarity is too unconstrained to give an
account of conceptual coherence. The second major shift is from the
idea that concepts are organized by similarity to the idea that concepts
are organized around theories. In this article, the evidence and
rationale associated with these shifts are described, and one means
of integrating similarity-based and theory-driven categorization
is outlined
Medin, D. L. and Atran, S. (1999).
Folkbiology.
Cambridge, Mass. : CogNet.
[ bib ]
Keywords: Cognition and culture, Ethnobiology, Folklore
Medin, D. L. and Atran, S. (2004).
The native mind: Biological categorization and reasoning in
development and across cultures.
Psychological Review, 111(4):960--983.
[ bib |
http ]
This article describes cross-cultural and developmental research on
folk biology: that is, the study of how people conceptualize living
kinds. The combination of a conceptual module for biology and cross-cultural
comparison brings a new perspective to theories of categorization
and reasoning. From the standpoint of cognitive psychology, the authors
find that results gathered from standard populations in industrialized
societies often fail to generalize to humanity at large. For example,
similarity-driven typicality and diversity effects either are not
found or pattern differently when one moves beyond undergraduates.
From the perspective of folk biology, standard populations may yield
misleading results because they represent examples of especially
impoverished experience with nature. Certain phenomena are robust
across populations, consistent with notions of a core module
Medin, D. L., Coley, J. D., Storms, G., and Hayes, B. K. (2003).
A relevance theory of induction.
Psychonomic Bulletin & Review, 10(3):517 -- 532.
[ bib ]
A framework theory, organized around the principle of relevance, is
proposed for category-based reasoning. According to the relevance
principle, people assume that premises are informative with respect
to conclusions. This idea leads to the prediction that people will
use causal scenarios and property reinforcement strategies in inductive
reasoning. These predictions are contrasted with both existing models
and normative logic. Judgments of argument strength were gathered
in three different countries, and the results showed the importance
of both causal scenarios and property reinforcement in categorybased
inferences. The relation between the relevance framework and existing
models of category-based inductive reasoning is discussed in the
light of these findings.
Medin, D. L. and Lynch, E. B. (2000).
Are there kinds of concepts?
Annual Review of Psychology, 51(1):121--.
[ bib |
http ]
Focuses on distinctions among kinds of concepts. Importance of distinguishing
concept types; Three types of criteria for distinguishing concept
types; Candidates for kinds of concepts based on structure, processing,
and content-laden principles; Skepticism over the use of domain-specificity
framework; Sensitivity to kinds of concepts as an effective research
strategy
Keywords: CATEGORIZATION (Psychology), Concepts
Medin, D. L., Lynch, E. B., Coley, J. D., and Atran, S. (1996).
The basic level and privilege in relation to goals, theories, and
similarity.
In Michalski, R. and Wnek, J., editors, Proceedings of the
Third International Conference on Multistrategy Learning.
Association for the Advancement of Artificial Intelligence.
[ bib ]
Medin, D. L., Lynch, E. B., Coley, J. D., and Atran, S. (1997).
Categorization and reasoning among tree experts: Do all roads lead to
rome?
Cognitive Psychology, 32:49--96.
[ bib ]
Medin, D. L., Lynch, E. B., and Solomon, K. O. (2000).
Are there kinds of concepts?
Annual Review of Psychology, 51:121--147.
[ bib ]
Medin, D. L. and Ortony, A. (1989).
Psychological essentialism.
In Vosniadou, S. and Ortony, A., editors, Similarity and
analogical reasoning, pages 179--195. Cambridge University Press, New York.
[ bib ]
Medin, D. L., Ross, N. O., Atran, S., Cox, D., Coley, J., Proffitt, J. B., and
Blok, S. (2006).
Folkbiology of freshwater fish.
Cognition, 99:237--273.
[ bib ]
Meints, K., Plunkett, K., and Harris, P. (1999).
When does an ostrich become a bird? the role of typicality in early
word comprehension.
Developmental Psychology, 35:1072--1078.
[ bib ]
Merriman, W., Schuster, J., and Hager, L. (1991).
Are names ever mapped onto preexisting categories.
Journal of Experimental Psychology: General, 120:288--300.
[ bib ]
Mervis, C., Catlin, J., and Rosch, E. (1976a).
Relationships among goodness-of-example, category norms, and word
frequency.
Bulletin of the Psychonomic Society, 7:283--284.
[ bib ]
Mervis, C. and Crisafi, M. (1982).
Order of acquisition of subordinate, basic, and superordinate level
categories.
Child Development, 53:258--266.
[ bib ]
Mervis, C., Johnson, K., and Mervis, C. (1994).
Acquisition of subordinate categories by 3-year-olds: The roles of
attribute salience, linguistic input, and child characteristics.
Cognitive Development, 9:211--234.
[ bib ]
Mervis, C. and Pani, J. (1980).
Acquisition of basic object categories.
Cognitive Psychology, 12:496--522.
[ bib ]
Mervis, C. and Rosch, E. (1981).
Categorization of natural objects.
Annual Review of Psychology, 32:89--115.
[ bib ]
Mervis, C. B. (1984).
Early lexical development: The contributions of mother and child.
In Sophian, C., editor, Origins of cognitve skills, chapter
Early lexical development: The contributions of mother and child, pages
339--370. Erlbaum, Hillsdale, NY.
[ bib ]
Mervis, C. B. (1987).
Child-basic object categories and early lexical development.
In Neisser, U., editor, Concepts and conceptual development:
Ecological and intellectual factors in categorisation, chapter Child-basic
object categories and early lexical development, pages 201--233. Cambridge
University Press, Cambridge, UK.
[ bib ]
Mervis, C. B., Catlin, J., and Rosch, E. (1976b).
Relationships among goodness-of-example, category norms, and word
frequency.
Bulletin of the Psychonomic Society, 7:283--284.
[ bib ]
Meulders, M. and Xie, Y. (2004).
Person-by-item predictors.
In De Boeck, P. and Wilson, M., editors, Explanatory item
response models: A generalized linear and nonlinear approach, chapter
Person-by-item predictors, pages 213--240. Springer, New York, NY.
[ bib ]
Meyer, J. P. (2010).
A mixture rasch model with item response time components.
Applied Psychological Measurement, 34:521--538.
[ bib ]
Miller, G. and Johnson-Laird, P. (1976).
Language and perception.
Harvard University Press.
[ bib ]
Millikan, R. (1986).
Thoughts without laws; cognitive science with content.
Philosophical Review, 95:47--80.
[ bib ]
Keywords: Cognitive science, Science
Mills, C. M. and Keil, F. C. (2004).
Knowing the limits of one's understanding: The development of an
awareness of an illusion of explanatory depth.
Journal of Experimental Child Psychology, 87(1):1--32.
[ bib |
http ]
Adults overestimate the detail and depth of their explanatory knowledge,
but through providing explanations they recognize their initial illusion
of understanding. By contrast, they are much more accurate in making
self-assessments for other kinds of knowledge, such as for procedures,
narratives, and facts. Two studies examined this illusion of explanatory
depth with 48 children each in grades K, 2, and 4, and also explored
adults' ratings of the children's explanations. Children judged their
understanding of mechanical devices (Study 1) and procedures (Study
2). Second and fourth graders showed a clear illusion of explanatory
depth for devices, recognizing the inaccuracy of their initial impressions
after providing explanations. The illusion did not occur for knowledge
of procedures
Keywords: Adult, Explanation, Knowledge
Mislevy, R. J. and Verhelst, N. (1990).
Modeling item responses when different subjects employ different
solution strategies.
Psychometrika, 55:195--215.
[ bib ]
Mooney, R. (1993).
Integrating theory and data in category learning, pages
189--218.
Academic Press.
[ bib ]
Morris, M. and Murphy, G. (1990).
Converging operations on a basic level in event taxonomies.
Memory & Cognition, 18:407--418.
[ bib ]
Morris, M. W. and Larrick, R. P. (1995).
When one cause casts doubt on another: A normative analysis of
discounting in causal attribution.
Psychological Review, 102:331--355.
[ bib ]
Murphy, G. (1982).
Cue validity and levels of categorization.
Psychological Bulletin, 91:174--177.
[ bib ]
Murphy, G. (1991a).
Meanings and Concepts, pages 11--36.
Erlbaum.
[ bib ]
Keywords: Concepts, Meaning
Murphy, G. (1991b).
Parts in object concepts: Experiments with artificial categories.
Memory & Cognition, 19:423--438.
[ bib ]
Murphy, G. (1993).
Theories and concept formation, pages 173--200.
Academic Press.
[ bib ]
Keywords: Concept Formation, Concepts
Murphy, G. (1997a).
Polysemy and the creation of new word meanings, pages 235--265.
American Psychological Association.
[ bib ]
Murphy, G. (2000).
Explanatory concepts.
In Keil, F. and Wilson, R., editors, Explanation and Cognition,
chapter 14, pages 361--392. MIT Press, Cambridge, Massachusetts.
[ bib ]
Keywords: Cognition
Murphy, G. (2002).
The big book of concepts.
MIT, Cambridge, MA.
[ bib ]
Keywords: Concepts
Murphy, G. and Andrew, J. (1993).
The conceptual basis of antonymy and synonymy in adjectives.
Journal of Memory and Language, 32:301--319.
[ bib ]
Murphy, G. and Brownell, H. (1985).
Category differentiation in object recognition: Typicality
constraints on the basic category advantage.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 11:70--84.
[ bib ]
Murphy, G. and Kaplan, A. (2000).
Feature distribution and background knowledge in category learning.
Quarterly Journal of Experimental Psychology A: Human
Experimental Psychology, 53A:962--982.
[ bib ]
Murphy, G. and Lassaline, M. (1997).
Hierarchical structure in concepts and the basic level of
categorization, pages 93--131.
UCL Press.
[ bib ]
Murphy, G. and Medin, D. (1985a).
The role of theories in conceptual coherence.
Psychological Review, 92:289--316.
[ bib ]
Murphy, G. and Ross, B. (1994).
Predictions from uncertain categorizations.
Cognitive Psychology, 27:148--193.
[ bib ]
Murphy, G. and Ross, B. (1999).
Induction with cross-classified categories.
Memory & Cognition, 27:1024--1041.
[ bib ]
Murphy, G. and Smith, E. (1982).
Basic level superiority in picture categorization.
Journal of Verbal Learning and Verbal Behavior, 21:1--20.
[ bib ]
Murphy, G. and Spalding, T. (1995).
Knowledge, similarity, and concept formation.
Psychologica Belgica, 35:127--144.
[ bib ]
Keywords: Concept Formation, Knowledge
Murphy, G. and Wisniewski, E. (1989a).
Categorizing objects in isolation and in scenes: What a superordinate
is good for.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 15:572--586.
[ bib ]
Murphy, G. and Wisniewski, E. (1989b).
Feature correlations in conceptual representations, pages
23--45.
Ellis Horwood.
[ bib ]
Murphy, G. and Wright, J. (1984).
Changes in conceptual structure with expertise: Differences between
real-world experts and novices.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 10:144--155.
[ bib ]
Murphy, G. L. (1996).
On metaphoric representation.
Cognition, 60(2):173--204.
[ bib |
http ]
Murphy, G. L. (1997b).
Reasons to doubt the present evidence for metaphoric representation.
Cognition, 62(1):99--108.
[ bib |
http ]
Keywords: Reason
Murphy, G. L. and Allopenna, P. D. (1994).
The locus of knowledge effects in concept learning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 20(4):904--919.
[ bib |
http ]
Keywords: Knowledge
Murphy, G. L. and Medin, D. L. (1985b).
The role of theories in conceptual coherence.
Psychological Review, 92(3):289--316.
[ bib ]
Nagel, E. (1977a).
Functional explanation in biology.
Journal of Philosophy, 74(5):280--301.
[ bib ]
Keywords: Teleology, Explanation
Nagel, E. (1977b).
Goal-directed processes in biology.
The Journal of Philosophy, 74(5):261--279.
[ bib ]
Keywords: Teleology, Explanation
Navarro, D. J. and Lee, M. D. (2004).
Common and distinctive features in stimulus similarity: A modified
version of the contrast model.
Psychonomic Bulletin & Review, 11:961--974.
[ bib ]
Needham, A. and Baillargeon, R. (2000).
Infants' use of featural and experiential information in segregating
and individuating objects: A reply to xu, carey and welch (2000).
Cognition, 74:255--284.
[ bib ]
Nelson, K. (1974).
Concept, word, and sentence: Interrelations in acquisition and
development.
Psychological Review, 81:267--285.
[ bib ]
Nestor, P. G., Akdag, S. J., O'Donnell, B. F., Niznikiewicz, M., Law, S.,
Shenton, M. E., and McCarley, R. W. (1998).
Word recall in schizophrenia: A connectionist model.
American Journal of Psychiatry, 155:1685--1690.
[ bib ]
Newell, B. R. (2005).
Re-visions of rationality?
Trends in Cognitive Science, 9:11--15.
[ bib ]
Newell, B. R. and Bröder, A. (2008).
Cognitive processes, models and metaphors in decision research.
Judgment and Decision Making, 3:195--204.
[ bib ]
Newport, E. and Bellugi, U. (1979).
Linguistic expression of category levels, pages --.
Harvard University Press.
[ bib ]
Nosofsky, R. (1984).
Choice, similarity, and the context theory of classification.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 10:104--114.
[ bib ]
Nosofsky, R. (1986).
Attention, similarity, and the identification-categorization
relationship.
Journal of Experimental Psychology: General, 115:39--57.
[ bib ]
Nosofsky, R. (1988).
Similarity, frequency, and category representations.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 14:54--65.
[ bib ]
Nosofsky, R. (1992).
Exemplars, prototypes and similarity rules, pages 149--168.
Erlbaum.
[ bib ]
Nosofsky, R. (2000).
Exemplar representation without generalization? comment on smith and
minda's (2000) "thirty categorization results in search of a model.".
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 26:1735--1743.
[ bib ]
Nosofsky, R. and Johansen, M. (2000).
Exemplar-based accounts of "multiple-system" phenomena in perceptual
categorization.
Psychonomic Bulletin & Review, 7:375--402.
[ bib ]
Nosofsky, R. and Palmeri, T. (1997).
An exemplar-based random walk model of speeded categorization.
Psychological Review, 104:266--300.
[ bib ]
Nosofsky, R. and Zaki, S. (1998).
Dissociations between categorization and recognition in amnesic and
normal individuals: An exemplar-based interpretation.
Psychological Science, 9:247--255.
[ bib ]
Nosofsky, R. M., Palmeri, T. J., and McKinley, S. C. (1994).
Rule-plus-exception model of classification learning.
Psychological Review, 101:53--79.
[ bib ]
Nunberg, G. (1979).
The non-uniqueness of semantic solutions: Polysemy.
Linguistics and Philosophy, 3:143--184.
[ bib ]
Oakes, L., Coppage, D., and Dingel, A. (1997).
By land or by sea: The role of perceptual similarity in infants'
categorization of animals.
Developmental Psychology, 33:396--407.
[ bib ]
O'Connor, C., Cree, G., and McRae, K. (2009).
Conceptual hierarchies in a flat attractor network: Dynamics of
learning and computations.
Cognitive Science, 33:665--708.
[ bib ]
Osgood, C., Suci, G., and Tannenbaum, P. (1957).
The measurement of meaning.
University of Illinois Press.
[ bib ]
Osherson, D. and Smith, E. (1981).
On the adequacy of prototype theory as a theory of concepts.
Cognition, 9:35--58.
[ bib ]
Osherson, D. and Smith, E. (1982).
Gradedness and conceptual conjunction.
Cognition, 12:299--318.
[ bib ]
Osherson, D. and Smith, E. (1997a).
On typicality and vagueness.
Cognition, 64:189--206.
[ bib ]
Osherson, D., Smith, E., Wilkie, O., L�pez, A., and Shafir, E. (1990).
Category-based induction.
Psychological Review, 97:185--200.
[ bib ]
Keywords: Induction
Osherson, D. and Smith, E. E. (1997b).
On typicality and vagueness.
Cognition, 64:189--206.
[ bib ]
Osherson, D., Stern, J., Wilkie, O., Stob, M., and Smith, E. (1991).
Default probability.
Cognitive Science, 15:251--269.
[ bib ]
Pachur, T. and Bröder, A. (2013).
Judgment: A cognitive processing perspective.
WIREs Cognitive Science, 4:665--681.
[ bib ]
Pachur, T. and Marinello, G. (2013).
Expert intuitions: How to model the decision strategies of airport
custom officers?
Acta Psychologica, 144:97--103.
[ bib ]
Palmeri, T. (1999).
Learning categories at different hierarchical levels: A comparison of
category learning models.
Psychonomic Bulletin & Review, 6:495--503.
[ bib ]
Palmeri, T. and Blalock, C. (2000).
The role of background knowledge in speeded perceptual
categorization.
Cognition, 77:B45--B57.
[ bib ]
Palmeri, T. J. and Nosofsky, R. M. (1995).
Recognition memory for exceptions to the category rule.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 21:548--568.
[ bib ]
Palmeri, T. J. and Nosofsky, R. M. (2001).
Central tendencies, extreme points, and prototype enhancement effects
in ill-defined perceptual categorization.
The Quarterly Journal of Experimental Psychology, 54A:197--235.
[ bib ]
Papineau, D. (1993).
Philosophical naturalism.
Blackwell.
[ bib ]
Keywords: Naturalism, Philosophy of mind
Papineau, D. (2002).
Thinking about consciousness.
Clarendon Press.
[ bib ]
Keywords: Consciousness
Pazzani, M. (1991).
Influence of prior knowledge on concept acquisition: Experimental and
computational results.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 17:416--432.
[ bib ]
Pearce, J. A. and DeNisi, A. S. (1983).
Attribution theory and strategic decision making: An application to
coalition formation.
Academy of Management Journal, 26(1):119.
ID: 4397344; M3: Article; Accession Number: 4397344; Pearce, John
A.DeNisi, Angelo S.; Source Information: Mar1983, Vol. 26 Issue 1, p119;
Thesaurus Term: ASSOCIATIONS, institutions, etc. -- Membership; Subject Term:
ATTRIBUTION (Social psychology)Subject Term: BANK directorsSubject Term:
SOCIAL networks -- Psychological aspects; NAICS/Industry Codes: 8139
Business, Professional, Labor, Political, and Similar Organizations; Number
of Pages: 10p; Illustrations: 2 charts; Document Type: Article.
[ bib |
http ]
Presents information on a study which investigated the attributions
made for membership in the dominant coalitions present among the
board members of several banks, by both members and nonmembers of
those coalitions. Method used in the study; Application of social
psychology on the nature of successful membership; Results and discussion.
Keywords: ASSOCIATIONS, institutions, etc. -- Membership; ATTRIBUTION (Social
psychology); BANK directors; SOCIAL networks -- Psychological aspects
Pearl, J. (2000).
Causality.
Cambridge University Press, Cambridge.
[ bib ]
Pervin, L. A. (1992).
The rational mind and the problem of volition.
Psychological Science, 3:162--165.
[ bib ]
Pinker, S. (1997).
How the mind works.
Penguin Books, New York.
[ bib ]
Pitt, M. A., Kim, W., and Myung, I. J. (2003).
Flexibility vs generalizability in model selection.
Psychonomic Bulletin & Review, 10:29--44.
[ bib ]
Plato (1987).
The Republic.
Penguin Classics.
[ bib ]
Plaut, D. C. and Shallice, T. (1993).
Deep dyslexia: A case study of connectionist neuropsychology.
Cognitive Neuropsychology, 10:377--500.
[ bib ]
Poldrack, R., Selco, S., Field, J., and Cohen, N. (1999).
The relationship between skill learning and repetition priming:
Experimental and computational analyses.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 25:208--235.
[ bib ]
Polichak, J. and Gerrig, R. (1998).
Common ground and everyday language use: Comments on horton and
keysar.
Cognition, 66:183--189.
[ bib ]
Posnansky, C. and Neumann, P. (1976).
The abstraction of visual prototypes by children.
Journal of Experimental Child Psychology, 21:367--379.
[ bib ]
Posner, M. and Keele, S. (1968).
On the genesis of abstract ideas.
Journal of Experimental Psychology, 77:353--363.
[ bib ]
Posner, M. and Keele, S. (1970).
Retention of abstract ideas.
Journal of Experimental Psychology, 83:304--308.
[ bib ]
Proffitt, J. B., Coley, J. D., and Medin, D. L. (2000).
Expertise and category-based induction.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 26(4):811--828.
[ bib |
http ]
The authors examined inductive reasoning among experts in a domain.
Three types of tree experts (landscapers, taxonomists, and parks
maintenance personnel) completed 3 reasoning tasks. In Experiment
1, participants inferred which of 2 novel diseases would affect "more
other kinds of trees" and provided justifications for their choices.
In Experiment 2, the authors used modified instructions and asked
which disease would be more likely to affect "all trees." In Experiment
3, the conclusion category was eliminated altogether, and participants
were asked to generate a list of other affected trees. Among these
populations, typicality and diversity effects were weak to nonexistent.
Instead, experts' reasoning was influenced by "local" coverage (extension
of the property to members of the same folk family) and causal-ecological
factors. The authors concluded that domain knowledge leads to the
use of a variety of reasoning strategies not captured by current
models of category-based induction
Keywords: Knowledge, Induction
Pullum, G. (1991).
The great Eskimo vocabulary hoax and other irreverent essays on
the study of language.
University of Chicago Press.
[ bib ]
Pustejovsky, J. (1995).
The generative lexicon.
MIT Press.
[ bib ]
Putnam, H. (1919).
Mathematics without foundations.
Journal of Philosophy, 64: 5-22:--222.
[ bib ]
Keywords: MATHEMATICS
Putnam, H. (1927).
Time and physical geometry.
Journal of Philosophy, 64: 240-247:--2477.
[ bib ]
Keywords: FUTURE, PHYSICS, REALITY, SCIENCE, TIME
Putnam, H. (1956a).
A definition of degree of confirmation for very rich languages.
Philosophy of Science, 23: 58-62:--622.
[ bib ]
Putnam, H. (1965).
Craig's theorem.
Journal of Philosophy, 62: 251-259:--2599.
[ bib ]
Keywords: ENUMERATION, LOGIC, RECURSIVENESS, THEORETICAL TERM
Putnam, H. (1975a).
Is semantics possible?
In Philosophical Papers Vol 2, pages 139--152. Cambridge
University Press, Cambridge, UK.
[ bib ]
Keywords: Language, Reality, Semantics
Putnam, H. (1975b).
The meaning of 'meaning'.
In Philosophical Papers Vol 2, Philosophical Papers Vol 2,
chapter 12, pages 215--271. Cambridge University Press, Cambridge, UK.
[ bib ]
Keywords: Language, Meaning, Reality
Putnam, H. (1975c).
Philosophical Papers Vol. 2: Mind, language and reality.
Cambridge University Press.
[ bib ]
Keywords: Language, Meaning, Realism, Reality
Putnam, H. (1975d).
Philosophy and our mental life.
In Philosophical Papers Vol 2, chapter 14, pages 291--303.
Cambridge: Cambridge University Press.
[ bib ]
Keywords: Language, Meaning, Reality
Putnam, H. (1979).
Reflections on goodman's "ways of worldmaking".
Journal of Philosophy, 76: 603-618:--6188.
[ bib ]
Keywords: LANGUAGE, METAPHYSICS, PHENOMENALISM, PHYSICALISM, TRUTH
Putnam, H. (1980a).
Meaning and reference.
Journal of Philosophy, 70: 699-711:--7111.
[ bib ]
Putnam, H. (1983b).
Possibility and necessity.
In Philosophical Papers Vol 3, pages 46--68. Cambridge:
Cambridge University Press.
[ bib ]
Keywords: Realism, Reason
Putnam, H. (1983c).
Reference and truth.
In Philosophical Papers Vol 3, Philosophical Papers Vol 3,
pages --. Cambridge U.P.
[ bib ]
Keywords: Realism, Reason, Truth
Putnam, H. (1991).
Representation and Reality.
MIT.
[ bib ]
Keywords: Reality
Putnam, H. (2001).
The threefold cord: mind, body, and world.
Columbia University Press, New York, NY.
[ bib ]
Keywords: Mind and body, Perception (Philosophy), Philosophy
Putnam, H. and ULLIAN, J. (1965).
More about 'about'.
Journal of Philosophy, 62: 305-310:--3100.
[ bib ]
Keywords: ABOUT, ABSOLUTE, LANGUAGE, PREDICATE
Pylkkänen, L., Llinás, R., and Murphy, G. L. (2006).
The representation of polysemy: MEG evidence.
Journal of Cognitive Neuroscience, 18:97--109.
[ bib ]
Quine, W. (1960).
Word and object.
MIT Press.
[ bib ]
Quine, W. (1969).
Natural Kinds, pages --.
Columbia U.P.
[ bib ]
Quine, W. (1985).
Events and reification.
In LePore, E. and McLaughlin, B., editors, Actions and Events:
Perspectives on the Philosophy of Donald Davidson, pages 162 -- 171.
Blackwell, New York.
[ bib ]
Quine, W. V. O. (1977).
Natural kinds.
In Schwartz, S. P., editor, Naming, necessity, and natural
kinds, chapter Natural kinds, pages 155--175. Cornell University Press,
Ithaca, NY.
[ bib ]
Quinn, P. (1987).
The categorical representation of visual pattern information by young
infants.
Cognition, 27:145--179.
[ bib ]
Quinn, P. and Eimas, P. (1996).
Perceptual cues that permit categorical differentiation of animal
species by infants.
Journal of Experimental Child Psychology, 63:189--211.
[ bib ]
Quinn, P. and Eimas, P. (1997).
A reexamination of the perceptual-to-conceptual shift in mental
representations.
Review of General Psychology, 1:271--287.
[ bib ]
Quinn, P., Eimas, P., and Rosenkrantz, S. (1993).
Evidence for representations of perceptually similar natural
categories by 3-month-old and 4-month-old infants.
Perception, 22:463--475.
[ bib ]
Quinn, P. and Johnson, M. (1997).
The emergence of perceptual category representations in young
infants: A connectionist analysis.
Journal of Experimental Child Psychology, 66:236--263.
[ bib ]
Raine, A. (1991).
The spq: A scale for the assessment of schizotypal personality based
on dsm-iii-r criteria.
Schizophrenia Bulletin, 17:555--564.
[ bib ]
Rakison, D. and Butterworth, G. (1998).
Infants' use of object parts in early categorization.
Developmental Psychology, 34:49--62.
[ bib ]
Rasch, G. (1960).
Probabilistic models for some intelligence and attainment
tests.
Danish Institute for Educational Research, Copenhagen, Denmark.
[ bib ]
Rasch, G. (1966).
An item analysis which takes individual differences into account.
British Journal of Mathematical & Statistical Psychology,
19:49--57.
[ bib ]
Ratneshwar, S., Barsalou, L. W., Pechmann, C., and Moore, M. (2001).
Goal-derived categories: The role of personal and situational goals
in category representations.
Journal of Consumer Psychology, 10:147--157.
[ bib ]
Ratneshwar, S., Mick, D. G., and Reitinger, G. (1990).
Selective attention in consumer information processing: The role of
chronically accessible attributes.
Advances in Consumer Research, 17:547--553.
[ bib ]
Ratneshwar, S., Pechmann, C., and Shocker, A. D. (1996).
Goal-derived categories and the antecedents of across-category
consideration.
Journal of Consumer Research, 23:240--250.
[ bib ]
Reed, S. (1972).
Pattern recognition and classification.
Cognitive Psychology, 3:382--407.
[ bib ]
Regehr, G. and Brooks, L. (1993).
Perceptual manifestations of an analytic structure: The priority of
holistic individuation.
Journal of Experimental Psychology: General, 122:92--114.
[ bib ]
Regehr, G. and Brooks, L. (1995).
Category organization in free classification: The organizing effect
of an array of stimuli.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 21:347--363.
[ bib ]
Rehder, B. (2001).
Interference between cognitive skills.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 27(2):451--469.
[ bib |
http ]
This study used a novel task, clock arithmetic, and a classic A-B/A-Br
transfer design to investigate the presence of interference between
cognitive skills. The A-B/A-Br design required participants to first
learn problem-to-answer associations during training and then to
learn new pairings between the same problems and answers during transfer.
The associations learned during training interfered with those learned
during transfer, as measured by slowed reaction times to emit the
correct response, failures to retrieve any response, and intrusion
errors. Interference persisted even after a 1-week retention interval
and was especially prevalent during the warm-up period at the beginning
of the retention test. The use of the A-B/A-Br design indicates that
whether an incorrect answer retrieved from memory is emitted as a
response depends on whether the intrusion is recognized as inappropriate
for the current task. The long-term memory for cognitive skills means
that attempts to learn new responses to old stimuli will be plagued
by persistent intrusion errors
Rehder, B. (2003a).
Categorization as causal reasoning.
Cognitive Science, 27(5):709--748.
[ bib |
http ]
A theory of categorization is presented in which knowledge of causal
relationships between category features is represented in terms of
asymmetric and probabilistic causal mechanisms. According to causal-model
theory, objects are classified as category members to the extent
they are likely to have been generated or produced by those mechanisms.
The empirical results confirmed that participants rated exemplars
good category members to the extent their features manifested the
expectations that causal knowledge induces, such as correlations
between feature pairs that are directly connected by causal relationships.
These expectations also included sensitivity to higher-order feature
interactions that emerge from the asymmetries inherent in causal
relationships. Quantitative fits of causal-model theory were superior
to those obtained with extensions to traditional similarity-based
models that represent causal knowledge either as higher-order relational
features or "prior exemplars" stored in memory
Keywords: Knowledge
Rehder, B. (2003b).
A causal-model theory of conceptual representation and
categorization.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 29(6):1141--1159.
[ bib |
http ]
This article presents a theory of categorization that accounts for
the effects of causal knowledge that relates the features of categories.
According to causal-model theory, people explicitly represent the
probabilistic causal mechanisms that link category features and classify
objects by evaluating whether they were likely to have been generated
by those mechanisms. In 3 experiments, participants were taught causal
knowledge that related the features of a novel category. Causal-model
theory provided a good quantitative account of the effect of this
knowledge on the importance of both individual features and interfeature
correlations to classification. By enabling precise model fits and
interpretable parameter estimates, causal-model theory helps place
the theory-based approach to conceptual representation on equal footing
with the well-known similarity-based approaches
Keywords: classification, Knowledge, Theory-based
Rehder, B. and Hastie, R. (2001).
Causal knowledge and categories: The effects of causal beliefs on
categorization, induction, and similarity.
Journal of Experimental Psychology: General, 130(3):323--360.
[ bib |
http ]
Despite the recent interest in the theoretical knowledge embedded
in human representations of categories, little research has systematically
manipulated the structure of such knowledge. Across four experiments
this study assessed the effects of interattribute causal laws on
a number of category-based judgments. The authors found that (a)
any attribute occupying a central position in a network of causal
relationships comes to dominate category membership, (b) combinations
of attribute values are important to category membership to the extent
they jointly confirm or violate the causal laws, and (c) the presence
of causal knowledge affects the induction of new properties to the
category. These effects were a result of the causal laws, rather
than the empirical correlations produced by those laws. Implications
for the doctrine of psychological essentialism, similarity-based
models of categorization, and the representation of causal knowledge
are discussed
Keywords: Essentialism, Human, Induction, Judgment, Knowledge, RESEARCH
Rehder, B. and Hastie, R. (2004).
Category coherence and category-based property induction.
Cognition, 91(2):113--153.
[ bib |
http ]
One important property of human object categories is that they define
the sets of exemplars to which newly observed properties are generalized.
We manipulated the causal knowledge associated with novel categories
and assessed the resulting strength of property inductions. We found
that the theoretical coherence afforded to a category by inter-feature
causal relationships strengthened inductive projections. However,
this effect depended on the degree to which the exemplar with the
to-be-projected predicate manifested or satisfied its category's
causal laws. That is, the coherence that supports inductive generalizations
is a property of individual category members rather than categories.
Moreover, we found that an exemplar's coherence was mediated by its
degree of category membership. These results were obtained across
a variety of causal network topologies and kinds of categories, including
biological kinds, non-living natural kinds, and artifacts
Keywords: Human, Induction, Knowledge
Rehder, B. and Ross, B. H. (2001).
Abstract coherent categories.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 27(5):1261--1275.
[ bib |
http ]
Many studies have demonstrated the importance of the knowledge that
interrelates features in people's mental representation of categories
and that makes our conception of categories coherent. This article
focuses on abstract coherent categories, coherent categories that
are also abstract because they are defined by relations independently
of any features. Four experiments demonstrate that abstract coherent
categories are learned more easily than control categories with identical
features and statistical structure, and also that participants induced
an abstract representation of the category by granting category membership
to exemplars with completely novel features. The authors argue that
the human conceptual system is heavily populated with abstract coherent
concepts, including conceptions of social groups, societal institutions,
legal, political, and military scenarios, and many superordinate
categories, such as classes of natural kinds
Keywords: Concepts, Human, Knowledge
Rehder, B., Schreiner, M., Wolfe, M., Laham, D., Landauer, T., and Kintsch, W.
(1998).
Using latent semantic analysis to assess knowledge: Some technical
considerations.
Discourse Processes, 25:337--354.
[ bib ]
Rey, G. (1983).
Concepts and stereotypes.
Cognition, 15:237--262.
[ bib ]
Rhodes, M. and Gelman, S. A. (2009).
Five-year-olds' beliefs about the discreteness of category boundaries
for animals and artifacts.
Psychonomic Bulletin & Review, 16:920--924.
[ bib ]
Rifkin, A. (1985).
Evidence for a basic level in event taxonomies.
Memory & Cognition, 13:538--556.
[ bib ]
Rips, L. (1989).
Similarity, typicality, and categorization, pages 21--59.
Cambridge University Press.
[ bib ]
Rips, L., Shoben, E., and Smith, E. (1973a).
Semantic distance and the verification of semantic relations.
Journal of Verbal Learning and Verbal Behavior, 12:1--20.
[ bib ]
Rips, L. J. (1975).
Inductive judgments about natural categories.
Journal of Verbal Learning & Verbal Behavior, 14:665--681.
[ bib ]
Rips, L. J. (2001).
Necessity and natural categories.
Psychological Bulletin., 127(6):827 -- 852.
[ bib ]
Our knowledge of natural categories includes beliefs not only about
what is true of them but also about what would be true if the categories
had properties other than (or in addition to) their actual ones.
Evidence about these beliefs comes from three lines of research:
experiments on category-based induction, on hypothetical transformations
of category members, and on definitions of kind terms. The 1st part
of this article examines results and theories arising from each of
these research streams. The 2nd part considers possible unified theories
for this domain, including theories based on ideals and norms. It
also contrasts 2 broad frameworks for modal category information:
one focusing on beliefs about intrinsic or essential properties,
the other focusing on interacting causal relations.
Rips, L. J. and Collins, A. (1993).
Categories and resemblance.
Journal of Experimental Psychology: General, 122:468--486.
[ bib ]
Rips, L. J. and Conrad, F. G. (1989).
Folk psychology of mental activities.
Psychological Review, 96(2):187--207.
[ bib ]
A central aspect of people's beliefs about the mind is that mental
activities-for example, thinking, reasoning, and problem solving-are
interrelated, with some activities being kinds or parts of others.
In common-sense psychology, reasoning is a kind of thinking and reasoning
is part of problem solving. People's conceptions of these mental
kinds and parts can furnish clues to the ordinary meaning of these
terms and to the differences between folk and scientific psychology.
In this article, we use a new technique for deriving partial orders
to analyze subjects' decisions about whether one mental activity
is a kind or part of another. The resulting taxonomies and partonomies
differ from those of common object categories in exhibiting a converse
relation in this domain: One mental activity is a part of another
if the second is a kind of the first. The derived taxonomies and
partonomies also allow us to predict results from further experiments
that examine subjects' memory for these activities, their ratings
of the activities' importance, and their judgments about whether
there could be "possible minds" that possess some of the activities
but not others., Copyright 1989 by the American Psychological Association,
Inc
Keywords: Behavioral & Social Sciences,PsycARTICLES, Judgment, Problem Solving,
PSYCHOLOGY
Rips, L. J., Shoben, E. J., and Smith, E. E. (1973b).
Semantic distance and the verification of semantic relations.
Journal of Verbal Learning & Verbal Behavior, 12:1--20.
[ bib ]
Ritov, I., Gati, I., and Tversky, A. (1990).
Differential weighting of common and distinctive components.
Journal of Experimental Psychology: General, 119:30--41.
[ bib ]
Rizopoulos, D. (2006).
ltm: An R package for latent variable modeling and item response
theory analyses.
Journal of Statistical Software, 17:1--25.
[ bib ]
Roberts, K. (1988).
Retrieval of a basic-level category in prelinguistic infants.
Developmental Psychology, 24:21--27.
[ bib ]
Roediger, H.L., I. (1990).
Implicit memory: Retention without remembering.
American Psychologist, 45:1043--1056.
[ bib ]
Roediger, H.L., I. and Blaxton, T. (1987).
Effects of varying modality, surface features, and retention interval
on priming in word fragment completion.
Memory & Cognition, 15:379--388.
[ bib ]
Roese, N. J. (1994).
The functional basis of counterfactual thinking.
Journal of Personality and Social Psychology, 66:805 -- 818.
[ bib ]
Rogers, T. T. and McClelland, J. L. (2004).
Semantic cognition: A parallel distributed processing approach.
MIT Press, Cambridge, MA.
[ bib ]
Rosch, E. (1973).
On the internal structure of perceptual and semantic categories.
In Moore, T. E., editor, Cognitive Development and the
Acquisition of Language, chapter On the internal structure of perceptual and
semantic categories, pages 111--144. Academic Press, New York.
[ bib ]
Rosch, E. (1975).
Cognitive representations of semantic categories.
Journal of Experimental Psychology: General, 104:192--233.
[ bib ]
Rosch, E. (1977).
Human categorization, pages 177--206.
Academic Press.
[ bib ]
Rosch, E. (1978).
Principles of categorization.
In Rosch, E. and Lloyd, B., editors, Cognition and
categorization, chapter Principles of categorization, pages 27--48. Erlbaum,
Hillsdale, NJ.
[ bib ]
Rosch, E. and Lloyd, B. (1978).
Cognition and Categorization.
Lawrence Erlbaum Associates.
[ bib ]
Keywords: Cognition
Rosch, E. and Mervis, C. (1975a).
Family resemblances: studies in the internal structure of categories.
Cognitive Psychology, 7:573--605.
[ bib ]
Rosch, E., Mervis, C., Gray, W., Johnson, D., and Boyes-Braem, P. (1976a).
Basic objects in natural categories.
Cognitive Psychology, 8:382--439.
[ bib ]
Rosch, E. and Mervis, C. B. (1975b).
Family resemblances: Studies in the internal structure of categories.
Cognitive Psychology, 7:573--605.
[ bib ]
Rosch, E., Simpson, C., and Miller, R. (1976b).
Structural bases of typicality effects.
Journal of Experimental Psychology: Human Perception and
Performance, 2:491--502.
[ bib ]
Ross, B. (1984).
Remindings and their effects in learning a cognitive skill.
Cognitive Psychology, 16:371--416.
[ bib ]
Ross, B. (1989).
Remindings in learning and instruction, pages 438--469.
Cambridge University Press.
[ bib ]
Ross, B. (1997).
The use of categories affects classification.
Journal of Memory and Language, 37:240--267.
[ bib ]
Ross, B. (2000).
The effects of category use on learned categories.
Memory & Cognition, 28:51--63.
[ bib ]
Ross, B., Perkins, S., and Tenpenny, P. (1990).
Reminding-based category learning.
Cognitive Psychology, 22:460--492.
[ bib ]
Ross, B. H. (1996).
Category representations and the effects of interacting with
instances.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 22:1249--1265.
[ bib ]
Ross, B. H. (1999).
Postclassification category use: The effects of learning to use
categories after learning to classify.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 25:743--757.
[ bib ]
Ross, B. H. and Murphy, G. L. (1996).
Category-based predictions: Influence of uncertainty and feature
associations.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 22(3):736--753.
[ bib |
http ]
Ross, B. H. and Murphy, G. L. (1999).
Food for thought: Cross-classification and category organization in a
complex real-world domain.
Cognitive Psychology, 38:495--553.
[ bib ]
Ross, N., Medin, D., Coley, J. D., and Atran, S. (2003).
Cultural and experiential differences in the development of
folkbiological induction.
Cognitive Development, 18(1):25--47.
[ bib |
http ]
Carey's (1985) book on conceptual change and the accompanying argument
that children's biology initially is organized in terms of naive
psychology has sparked a great detail of research and debate. This
body of research on children's biology has, however, been almost
exclusively been based on urban, majority culture children in the
US or in other industrialized nations. The development of folkbiological
knowledge may depend on cultural and experiential background. If
this is the case, then urban majority culture children may prove
to be the exception rather than the rule, because plants and animals
do not play a significant role in their everyday life. Urban majority
culture children, rural majority culture children, and rural Native
American (Menominee) children were given a property projection task
based on Carey's original paradigm. Each group produced a unique
profile of development. Only urban children showed evidence for early
anthropocentrism, suggesting that the co-mingling of psychology and
biology may be a product of an impoverished experience with nature.
In comparison to urban majority culture children even the youngest
rural children generalized in terms of biological affinity. In addition,
all ages of Native American children and the older rural majority
culture children (unlike urban children) gave clear evidence of ecological
reasoning. These results show that both culture and expertise (exposure
to nature) play a role in the development of folkbiological thought
Keywords: Knowledge
Rost, J. (1990).
Rasch models in latent classes: An integration of two approaches to
item analysis.
Applied Psychological Measurement, 14:271--282.
[ bib ]
Roth, E. and Shoben, E. (1983a).
The effect of context on the structure of categories.
Cognitive Psychology, 15:346--378.
[ bib ]
Roth, E. M. and Shoben, E. J. (1983b).
The effect of context on the structure of categories.
Cognitive Psychology, 15:346--378.
[ bib ]
Rothschild, L. and Haslam, N. (2003).
Thirsty for H2O: A pragmatist theory of psychological
essentialism.
New Ideas in Psychology, 21:31 -- 41.
[ bib ]
Rozenblit, L. and Keil, F. (2002).
The misunderstood limits of folk science: an illusion of explanatory
depth.
Cognitive Science, 26(5):521 -- 562.
[ bib ]
Rozin, P. and Nemeroff, C. (1990).
The laws of sympathetic magic: A psychological analysis of similarity
and contagion.
In Stigler, J., Herdt, G., and Shweder, R., editors, Cultural
Psychology: Essays on comparative human development, pages 205 -- 232.
Cambridge, Cambridge, England.
[ bib ]
Ruben, D. H. (1993).
Explanation.
Oxford ; New York : Oxford University Press.
[ bib ]
Ruhl, C. (1989).
On monosemy: A study in linguistic semantics.
SUNY Press.
[ bib ]
Rumelhart, D. and McClelland, J. (1986).
Parallel distributed processing: Explorations in the
microstructure of cognition. Vol. 1: Foundations.
MIT Press.
[ bib ]
Rumelhart, D. and Ortony, A. (1977).
The representation of knowledge in memory, pages --.
Erlbaum.
[ bib ]
Russell, B. (1998/1912).
The problems of philosophy.
Oxford University Press, Oxford.
[ bib ]
Ruts, W., Storms, G., and Hampton, J. A. (2004).
Linear separability in superordinate natural language concepts.
Memory & Cognition, 32:83--95.
[ bib ]
Ryan, R. M. (1992).
Agency and organization: Intrinsic motivation, autonomy, and the
self in psychological development.
In Jacobs, E., editor, Nebraska Symposium on Motivation,
volume 34, chapter Agency and organization: Intrinsic motivation, autonomy,
and the self in psychological development, pages 1--56. University of
Nebraska Press, Lincoln, NE.
[ bib ]
Sadler, D. D. and Shoben, E. J. (1993).
Context effects on semantic domains as seen in analogy solution.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 19:128--147.
[ bib ]
Salmon, W. C. (1981).
Rational prediction.
British Journal for the Philosophy of Science, 32:115--125.
[ bib ]
Keywords: PREDICTION, RATIONALITY, SCIENCE
Salmon, W. C. (1983).
Carl g. hempel on the rationality of science.
Journal of Philosophy, 80:555--562.
[ bib ]
Salmon, W. C. (1998).
Causality and Explanation.
Oxford University Press, Oxford.
[ bib ]
This long-awaited volume collects twenty-six of Salmon's essays, including
seven that have never before been published and others difficult
to find. Part I comprises five introductory essays that presuppose
no formal training in philosophy of science and form a background
for subsequent essays. Parts II and III contain Salmon's seminal
work on scientific explanation and causality. Part IV offers survey
articles that feature advanced material but remain accessible to
those outside philosophy of science. Essays in Part V address specific
issues in particular scientific disciplines, namely, archaeology
and anthropology, astrophysics and cosmology, and physics. (publisher,
edited)
Salmon, W. C. (1999).
The spirit of logical empiricism: Carl g hempel's role in
twentieth-century philosophy of science.
Philosophy of Science, 66(3): 333-350):--350.
[ bib ]
Samarapungavan, A., Vosniadou, S., and Brewer, W. F. (1996).
Mental models of the earth, sun, and moon: Indian children's
cosmologies.
Cognitive Development, 11:491--521.
[ bib ]
Studied acquisition of knowledge about astronomy in children (aged
5 yrs 8 mo to 8 yrs 5 mo) from India. It was hypothesized that the
cosmological models that children construct are influenced by both
1st-order (FO) and 2nd-order (SO) constraints on knowledge acquisition.
FO constraints are the implicit assumptions that govern the construction
of initial cosmological models (e.g., assumptions that the earth
is flat and supported). Such FO constraints are presumed to be universal.
SO constraints arise from the specific properties ascribed to cosmological
objects (e.g., representations of the earth's shape and location
relative to the sun and moon constrain the kinds of mechanisms that
are generated to account for the day-night cycle). It was hypothesized
that in cultures where both folk cosmologies and the scientific cosmological
model are accessible to children, aspects of folk models are likely
to be incorporated in children's cosmologies if they provide a psychologically
easier way of satisfying FO constraints. This hypothesis was supported
by findings with regard to universality and culture specificity in
children's cosmologies. (PsycINFO Database Record (c) 2003 APA, all
rights reserved)
Keywords: *Child Attitudes, *Cognitive Development, *Folklore, *Sciences, 5.7-8.4
yr olds, beliefs about shape & motions & relative location of earth
& sun & moon & day-night cycle & influence of folk models, Childhood
(birth-12 yrs), Cognitive & Perceptual Development [2820]., Cognitive
Development, Concept Formation, Empirical Study, Human, Hypothesis,
India, Knowledge, Models, Preschool Age (2-5 yrs), School Age (6-12
yrs), Science
Sandberg, C., Sebastian, R., and Kiran, S. (2012).
Typicality mediates performance during category verification in both
ad-hoc and well-defined categories.
Journal of Communication Disorders, 45:69--83.
[ bib ]
Sattath, S. and Tversky, A. (1987).
On the relation between common and distinctive feature models.
Psychological Review, 94:16--22.
[ bib ]
Schank, R. and Abelson, R. (1977).
Scripts, plans, goals and understanding.
Erlbaum.
[ bib ]
Scheibehenne, B. and von Helversen, B. (2015).
Selecting decision strategies: The differential role of affect.
Cognition and Emotion, 29:158--167.
[ bib ]
Schmitt, N. and Stuits, D. M. (1985).
Factors defined by negatively keyed items: The result of careless
respondents?
Applied Psychological Measurement, 9:367--373.
[ bib ]
Schneider, W. and Bjorklund, D. (1998).
Memory, pages 467--521.
Wiley.
[ bib ]
Schwanenflugel, P. J., Akin, C., and Luh, W.-M. (1992).
Context availability and the recall of abstract and concrete words.
Memory & Cognition, 20:96--104.
[ bib ]
Schwanenflugel, P. J., Harnishfeger, K. K., and Stowe, R. W. (1988).
Context availability and lexical decisions for abstract and concrete
words.
Journal of Memory and Language, 27:499--520.
[ bib ]
Schwanenflugel, P. J. and Noyes, C. R. (1996).
Context availability and the development of word reading skill.
Journal of Literacy Research, 28:35--54.
[ bib ]
Schwanenflugel, P. J. and Rey, M. (1986).
Interlingual semantic facilitation: Evidence for a common
representational system in the bilingual lexicon.
Journal of Memory and Language, 25:605--618.
[ bib ]
Schwanenflugel, P. J. and Shoben, E. J. (1983).
Differential context effects in the comprehension of abstract and
concrete verbal materials.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 9:82--102.
[ bib ]
Schwanenflugel, P. J. and Stowe, R. W. (1989).
Context availability and the processing of abstract and concrete
words in sentences.
Reading Research Quarterly, 24:114--126.
[ bib ]
Schwartz, S. (1977).
Naming, Necessity, and Natural Kinds.
Cornell U.P.
[ bib ]
Schwartz, S. (1978).
Putnam on artifacts.
Philosophical Review, 87:566 -- 574.
[ bib ]
HILARY PUTNAM HAS ARGUED THAT VIRTUALLY ALL OF THE COMMON NOUNS OF
ORDINARY LANGUAGE ARE LIKE NATURAL KIND TERMS IN THAT THEY ARE INDEXICAL.
HIS ARGUMENTS ARE NOT CONVINCING, HOWEVER, WHEN APPLIED TO ARTIFACT
KIND TERMS. THERE IS A DISTINCTION BETWEEN NATURAL KIND TERMS AND
NOMINAL KIND TERMS. THE LATTER ARE NOT INDEXICAL. ARTIFACT KIND TERMS
ARE NOMINAL KIND TERMS. IT SEEMS THAT A SIGNIFICANT PROPORTION OF
ORDINARY NOUNS ARE NOMINAL KIND TERMS.
Keywords: ARTIFACT-; INDEXICALITY-; LANGUAGE-
Schwarz, G. (1978).
Estimating the dimension of a model.
Annals of Statistics, 6:461--464.
[ bib ]
Schyns, P., Goldstone, R., and Thibaut, J. (1998).
The development of features in object concepts.
Behavioral and Brain Sciences, 21:1--54.
[ bib ]
Schyns, P. and Murphy, G. (1994).
The ontogeny of part representation in object concepts. ED - D.
L. Medin, pages 305--349.
Academic Press.
[ bib ]
Schyns, P. and Rodet, L. (1997).
Categorization creates functional features.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 23:681--696.
[ bib ]
Sebastian, R. and Kiran, S. (2007).
Effect of typicality of ad hoc categories in lexical access.
Brain and Language, 103:248--249.
[ bib ]
Shafto, P., Kemp, C., Masinghka, V. K., and Tenenbaum, J. B. (2011).
A probabilistic model of cross-categorization.
Cognition, 120:1--25.
[ bib ]
Sharp, D., Cole, M., and Lave, C. (1979).
Education and cognitive development: The evidence from experimental
research.
Monographs of the Society for Research in Child Development,
44, serial 148, nos. 1-2:--.
[ bib ]
Shaver, P., Schwartz, J., Kirson, D., and O'Connor, D. (1987).
Emotion knowledge: Further explorations of a prototype approach.
Journal of Personality and Social Psychology, 52:1061--1086.
[ bib ]
Shepard, R. (1974).
Representation of structure in similarity data: Problems and
prospects.
Psychometrika, 39:373--421.
[ bib ]
Shepard, R. (1987).
Toward a universal law of generalization for psychological science.
Science, 237:1317--1323.
[ bib ]
Shepard, R., Hovland, C., and Jenkins, H. (1961).
Learning and memorization of classifications.
Psychological Monographs: General and Applied, 75 (13, Whole
No. 517):--.
[ bib ]
Shepp, B. (1983).
The analyzability of multidimensional objects: Some constraints
on perceived structure, the development of perceived structure, and
attention, pages 39--75.
Erlbaum.
[ bib ]
Shevchenko, Y., von Helversen, B., and Scheibehenne, B. (2014).
Change and status quo in decisions with defaults: The effect of
incidental emotions depends on the type of default.
Judgment and Decision Making, 9:287--296.
[ bib ]
Shipley, E. (1993).
Categories, hierarchies, and induction, pages 265--301.
Academic Press.
[ bib ]
Shipley, E., Kuhn, I., and Madden, E. (1983).
Mothers' use of superordinate category terms.
Journal of Child Language, 10:571--588.
[ bib ]
Shoben, E. J. (1976).
The verification of semantic relations in a same�different paradigm:
An asymmetry in semantic memory.
Journal of Verbal Learning & Verbal Behavior, 15:365--379.
[ bib ]
Simon, D., Krawczyk, D. C., Bleicher, A., and Holyoak, K. J. (2008).
The transience of constructed preferences.
Journal of Behavioral Decision Making, 21:1--14.
[ bib ]
Simon, H. A. (1994).
The bottleneck of attention: Connecting thought with motivation.
In Spaulding, W., editor, Integrative views of motivation,
cognition, and emotion, volume 41 of Nebraska Symposium on Motivation,
chapter The bottleneck of attention: Connecting thought with motivation,
pages 1--21. University of Nebraska Press, Lincoln, NE.
[ bib ]
Simon, H. A. (1998).
Discovering explanations.
Minds and Machines, 8(1): 7-37):--37.
[ bib ]
Keywords: EXPLANATION
Simons, D. J. and Keil, F. C. (1995).
An abstract to concrete shift in the development of biological
thought: the insides story.
Cognition, 56(2):129--163.
[ bib |
http ]
For more than a century, theorists of cognitive development have embraced
some form of the thesis that cognitive development proceeds from
concrete to abstract knowledge. In contrast to this view, we suggest
an abstract to concrete shift in the development of biological thought.
In five studies we examine children's expectations for what could
be inside animals and machines and we find that children of all ages
respond systematically, revealing abstract expectations for how the
insides of animals and machines should differ. By 8 years, children
seem to have more concrete expectations for the nature of insides,
and are substantially more accurate than preschoolers. More broadly,
we suspect that an abstract to concrete progression may capture important
features of how knowledge develops in the realm of biological thought
and in many other areas of understanding as well
Keywords: Knowledge
Simons, S. (1993).
No one may ever have the same knowledge again: Letters to Mount
Wilson Observatory, 1915-1935.
Society for the Diffusion of Useful Information Press.
[ bib ]
Slobin, D. (1996).
From "thought and language" to "thinking for speaking." ED - J.
J. Gumperz, pages 70--96.
Cambridge University Press.
[ bib ]
Sloman, S. (1994).
When explanations compete: The role of explanatory coherence on
judgements of likelihood.
Cognition, 52(1):1--21.
[ bib ]
The likelihood of a statement is often derived by generating an explanation
for it and evaluating the plausibility of the explanation. The explanation
discounting principle states that people tend to focus on a single
explanation; alternative explanations compete with the effect of
reducing one another's credibility. Two experiments tested the hypothesis
that this principle applies to inductive inferences concerning the
properties of everyday categories. In both experiments, subjects
estimated the probability of a series of statements (conclusions)
and the conditional probabilities of those conclusions given other
related facts. For example, given that most lawyers make good sales
people, what is the probability that most psychologists make good
sales people? The results showed that when the fact and the conclusion
had the same explanation the fact increased people's willingness
to believe the conclusion, but when they had different explanations
the fact decreased the conclusion's credibility. This decrease is
attributed to explanation discounting; the explanation for the fact
had the effect of reducing the plausibility of the explanation for
the conclusion.
Sloman, S. (1997).
Explanatory coherence and the induction of properties.
Thinking & Reasoning, 3:81--110.
[ bib ]
Sloman, S. (1998).
Categorical inference is not a tree: The myth of inheritance
hierarchies.
Cognitive Psychology, 35:1--33.
[ bib ]
Sloman, S. (2005a).
Avoiding foolish consistency.
Behavioral and Brain Sciences, 28(1):33--34.
[ bib ]
In most cases, rule-governed relations and similarity relations can
indeed be distinguished by the number of relevant features they require.
This criterion is not sufficient, however, to explain other properties
of the relations that have a more dichotomous character. I focus
on the differential drive for consistency by inferential processes
that draw on the two types of relations.
Sloman, S. and Lagnado, D. A. (2004).
Causal invariance in reasoning and learning.
Psychology of Learning and Motivation: Advances in Research and
Theory, 44:287--325.
[ bib ]
Sloman, S. and Rips, L. (1998).
Similarity as an explanatory construct.
Cognition, 65:87--101.
[ bib ]
Sloman, S. A. (2005b).
Causal models: How people think about the world and its
alternatives.
Oxford University Press, New York.
[ bib ]
Sloman, S. A. and Ahn, W. K. (1999).
Feature centrality: Naming versus imagining.
Memory & Cognition, 27(3):526--537.
[ bib ]
Being white is central to whether we call an animal a "polar bear,"
but it is fairly peripheral to our concept of what a polar bear is.
We propose that a feature is central to category naming in proportion
to the feature's category validity-the probability of the feature,
given the category. In contrast, a feature is conceptually central
in a representation of the object to the extent that the feature
is depended on by other features. Further, we propose that naming
and conceptual centrality are more likely to disagree for features
that hold at more specific levels (such as is white, which holds
only for the specific category of polar bear) than for features that
hold at intermediate levels of abstraction (such as has claws, which
holds for all bears), In support of these hypotheses, we report evidence
that increasing the abstractness of category features has a greater
effect on judgments of conceptual centrality than on judgments of
name centrality and that other category features depend more on intermediate-level
category features than on specific ones.
Sloman, S. A., Harrison, M. C., and Malt, B. C. (2002).
Recent exposure affects artifact naming.
Memory & Cognition, 30(5):687--695.
[ bib ]
Deciding how to label an object depends both on beliefs about the
culturally appropriate name and on memory. A label should be consistent
with a language community's norms, but those norms can be used only
if they can be retrieved. Two experiments are reported in which we
tested the hypothesis that immediate prior exposure to familiar objects
and their names affects how an ambiguous target object is named.
Exposure to a typical instance of one name category was pitted against
exposure to one or two instances from a contrasting category. When
the contrast set consisted of a neighbor of the target, naming was
usually consistent with the contrast category. This effect was reduced
when a typical instance of the contrast category was also exposed.
In Experiment 2, the exposure set was varied to include conditions
in which either the neighbor or a prototypical instance was paired
with an instance dissimilar to the target. The results suggest that
all recently exposed objects affect name choice in proportion to
their similarity to the target.
Sloman, S. A. and Lagnado, D. A. (2005).
Do we "do"?
Cognitive Science, 29(1):5--39.
[ bib ]
A normative framework for modeling causal and counterfactual reasoning
has been proposed by Spirtes, Glymour, and Scheines (1993; cf. Pearl,
2000). The framework takes as fundamental that reasoning from observation
and intervention differ. Intervention includes actual manipulation
as well as counterfactual manipulation of a model via thought. To
represent intervention, Pearl employed the do operator that simplifies
the structure of a causal model by disconnecting an intervened-on
variable from its normal causes. Construing the do operator as a
psychological function affords predictions about how people reason
when asked counterfactual questions about causal relations that we
refer to as undoings a family of effects that derive from the claim
that intervened-on variables become independent of their normal causes.
Six studies support the prediction for causal (A causes B) arguments
but not consistently for parallel conditional (if A then B) ones.
Two of the studies show that effects are treated as diagnostic when
their values are observed but nondiagnostic when they are intervened
on. These results cannot be explained by theories that do not distinguish
interventions from other sorts of events.
Sloman, S. A., Love, B. C., and Ahn, W.-k. (1998).
Feature centrality and conceptual coherence.
Cognitive Science, 22(2):189--228.
[ bib ]
Focuses on conceptual features. Immutability of features; Dependence
of the internal structure of a concept on that feature; Testing of
a model of mutability; Findings of the qualitative tests of the model
Keywords: CENTRALITY, Concepts, Feature Centrality, RESEARCH
Sloman, S. A. and Malt, B. C. (2003).
Artifacts are not ascribed essences, nor are they treated as
belonging to kinds.
Language and Cognitive Processes, 18(5-6):563--582.
[ bib ]
We evaluate three theories of categorisation in the domain of artifacts.
Two theories are versions of psychological essentialism; they posit
that artifact categorisation is a matter of judging membership in
a kind by appealing to a belief about the true, underlying nature
of the object. The first version holds that the essence can be identified
with the intended function of objects. The second holds that the
essence can be identified with the creator's intended kind membership.
The third theory is called "minimalism". It states that judgements
of kind membership are based on beliefs about causal laws, not beliefs
about essences. We conclude that each theory makes unnecessary assumptions
in explaining how people make everyday classifications and inductions
with artifacts. Essentialist theories go wrong in assuming that the
belief that artifacts have essences is critical to categorisation.
All theories go wrong in assuming that artifacts are treated as if
they belong to stable, fixed kinds. Theories of artifact categorisation
must contend with the fact that artifact categories are not stable,
but rather depend on the categorisation task at hand.
Slovic, P. (1995).
The construction of preference.
American Psychologist, 50:364--371.
[ bib ]
Smiley, S. and Brown, A. (1979).
Conceptual preferences for thematic or taxonomic relations: A
nonmonotonic age trend from preschool to old age.
Journal of Experimental Child Psychology, 28:249--257.
[ bib ]
Smith, E. (1978).
Theories of semantic memory, pages 1--56.
Erlbaum.
[ bib ]
Smith, E., Balzano, G., and Walker, J. (1978).
Nominal, perceptual, and semantic codes in picture
categorization, pages 137--168.
Erlbaum.
[ bib ]
Smith, E. and Medin, D. (1981).
Categories and concepts.
Harvard University Press.
[ bib ]
Smith, E. and Osherson, D. (1984).
Conceptual combination with prototype concepts.
Cognitive Science, 8:337--361.
[ bib ]
Smith, E., Osherson, D., Rips, L., and Keane, M. (1988).
Combining prototypes: A selective modification model.
Cognitive Science, 12:485--527.
[ bib ]
Smith, E., Rips, L., and Shoben, E. (1974a).
Semantic memory and psychological semantics, pages 1--45.
Academic Press.
[ bib ]
Smith, E., Shafir, E., and Osherson, D. (1993).
Similarity, plausibility, and judgments of probability.
Cognition, 49:67--96.
[ bib ]
Smith, E. and Sloman, S. (1994).
Similarity- versus rule-based categorization.
Memory & Cognition, 22:377--386.
[ bib ]
Smith, E. E., Shoben, E. J., and Rips, L. J. (1974b).
Structure and process in semantic memory: A featural model for
semantic decisions.
Psychological Review, 81:214--241.
[ bib ]
Smith, J. and Minda, J. (1998).
Prototypes in the mist: The early epochs of category learning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 24:1411--1436.
[ bib ]
Smith, J. and Minda, J. (2000).
Thirty categorization results in search of a model.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 26:3--27.
[ bib ]
Smith, J. and Minda, J. (2001).
Journey to the center of the category: The dissociation in amnesia
between categorization and recognition.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 27:984--1002.
[ bib ]
Smith, J. D., Murray, M. J., and Minda, J. P. (1997).
Straight talk about linear separability.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 23:659--680.
[ bib ]
One enduring principle of rational inference is category inclusion:
Categories inherit the properties of their superordinates. In five
experiments, I show that people do not consistently apply this principle
when evaluating categorical arguments involving natural categories
and a single nonexplainable predicate such as all electronic equipment
has pal-ts made of germanium, therefore all stereos have parts made
of germanium. Participants frequently did not apply the category
inclusion rule despite affirming the relevant categorical relation
(e.g., stereos are electronic equipment). They failed to apply the
rule even when categories were universally quantified unambiguously.
Instead, judgments tended to be proportional to the similarity between
premise and conclusion categories. Neglect of category inclusion
relations was observed using arguments concerning natural kinds,
artifacts, and social kinds. (C) 1998 Academic Press.
Smith, L. and Heise, D. (1992).
Perceptual similarity and conceptual structure, pages 233--272.
Elsevier.
[ bib ]
Smith, L. B. and Samuelson, L. K. (1997).
Perceiving and remembering: Category stability, variability and
development.
In Lamberts, K. and Shanks, D., editors, Knowledge, concepts,
and categories, chapter Perceiving and remembering: Category stability,
Variability and Development, pages 161--195. Psychology Press, East Sussex,
UK.
[ bib ]
Smits, D. J. M., De Boeck, P., and Hoskens, M. (2003).
Examining the structure of concepts: Using interactions between
items.
Applied Psychological Measurement, 27(7):415--439.
[ bib ]
Smits, T., Storms, G., Rosseel, Y., and De Boeck, P. (2002).
Fruits and vegetables categorized: An application of the generalized
context model.
Psychonomic Bulletin & Review, 9:836--844.
[ bib ]
Smoke, K. (1932).
An objective study of concept formation.
Psychological Monographs, XLII (whole No. 191):--.
[ bib ]
Smolensky, P. (1987).
The constituent structure of connectionist mental states: A reply to
fodor and pylyshyn.
The Southern Journal of Philosophy, Supplement, 26:137--161.
[ bib ]
Smolensky, P. (1988).
On the proper treatment of connectionism.
Behavioral and Brain Sciences, 11:1--74.
[ bib ]
Sober, E. (1980).
Evolution, population thinking, and essentialism.
Philosophy of Science, 47: 350-383:--3833.
[ bib ]
Sober, E. (1995).
Natural selection and distinctive explanation: A reply to neander.
British Journal for the Philosophy of Science, 46(3):
384-397):--397.
[ bib ]
Keywords: BIOLOGY, EXPLANATION, NATURAL SELECTION, SCIENCE, SELECTION, SEX,
SPECIES
Sober, E. (2004).
Likelihood, model selection, and the duhem-quine problem.
Journal of Philosophy, 101(5): 221-241):--241.
[ bib ]
Soja, N., Carey, S., and Spelke, E. (1991).
Ontological categories guide young children's inductions of word
meaning: Object terms and substance terms.
Cognition, 38:179--211.
[ bib ]
Söllner, A., Bröder, A., Glöckner, A., and Betsch, T. (2014).
Single-process versus multiple-strategy models of decision making:
Evidence from an information intrusion paradigm.
Acta Psychologica, 146:84--96.
[ bib ]
Solomon, G., Johnson, S., Zaitchik, D., and Carey, S. (1996).
Like father, like son: Young children's understanding of how and why
offspring resemble their parents.
Child Development, 67:151--171.
[ bib ]
Solomon, K. and Barsalou, L. (2001).
Representing properties locally.
Cognitive Psychology, 43:129--169.
[ bib ]
Spalding, T. and Murphy, G. (1999).
What is learned in knowledge-related categories? evidence from
typicality and feature frequency judgments.
Memory & Cognition, 27:856--867.
[ bib ]
Spalding, T. and Ross, B. (1994).
Comparison-based learning: Effects of comparing instances during
category learning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 20:1251--1263.
[ bib ]
Spalding, T. L. and Murphy, G. L. (1996).
Effects of background knowledge on category construction.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 22(2):525--538.
[ bib |
http ]
Keywords: Knowledge
Spellman, B. A., Mandel, and R, D. (1999).
When possibility informs reality: Counterfactual thinking as a cue to
causality.
Current Directions in Psychological Science, 8:120 -- 123.
[ bib ]
Spencer, J., Quinn, P., Johnson, M., and Karmiloff-Smith, A. (1997).
Heads you win, tails you lose: Evidence for young infants
categorizing mammals by head and facial attributes.
Early Development and Parenting, 6:113--126.
[ bib ]
Sperber, D., Cara, F., and Girotto, V. (1995a).
Relevance theory explains the selection task.
Cognition, 57(1):31--95.
Population Group: Human. Adulthood (18 yrs & older).; Form/Content
Type: Empirical Study; Update Code: 19960701.
[ bib |
http ]
Proposes a predictive explanation of the Wason Selection Task (for
testing a conditional rule) based on reanalysis of the task, and
Relevance Theory. Four experiments on reasoning were conducted on
187 Ss in Italy and France to compare relevance (RC) and irrelevance
conditions (IC). Ss were to understand the problem of 2 situations
P and Q so that P-and-(not Q) situation will hold true in RC and
not in IC. Results show that Ss inferred from the rule directly testable
consequences in their order of accessibility, and stopped when the
resulting interpretation of the rule met their expectations of relevance.
Order of accessibility of the consequences and expectations may vary
with the content and context of the rule. Ss selected the cards that
may test the directly testable consequences they have inferred from
the rule. By devising appropriate rule-context pairs, correct performance
can be elicited in any conceptual domain. (PsycINFO Database Record
(c) 2004 APA, all rights reserved)
Keywords: reanalysis of Wason Selection Task based on Relevance Theory, college
students, Italy & France; Cognition; Reasoning; Task Analysis; Theories
Sperber, D., Premack, D., and Premack, A. J., editors (1995b).
Causal cognition: A multidisciplinary debate.
Clarendon Press/Oxford University Press, New York, NY, US.
[ bib ]
(from the jacket) An understanding of cause-effect relationships is
fundamental to the study of cognition. In this book, . . . specialists
from comparative psychology, social psychology, developmental psychology,
anthropology, and philosophy present the newest developments in the
study of causal cognition and discuss their different perspectives.
They reflect on the role and forms of causal knowledge, both in animal
and human cognition, on the development of human causal cognition
from infancy, and on the relationship between individual and cultural
aspects of causal understanding. (PsycINFO Database Record (c) 2004
APA, all rights reserved); (Abbreviated) List of participants Introduction
[by] Dan Sperber Part I: Causal representation in animal cognition
* Instrumental action and causal representation / Anthony Dickinson
and David Shanks * Causal knowledge in animals / Hans Kummer Part
II: Causal understanding in naive physics * Infants' knowledge of
object motion and human action / Elizabeth S. Spelke, Ann Phillips
and Amanda L. Woodward * The acquisition of physical knowledge in
infancy / Renee Baillargeon, Laura Kotovsky and Amy Needham Part
III: Causal understanding in naive psychology * A theory of agency
/ Alan M. Leslie * Distinguishing between animates and inanimates:
Not by motion alone / Rochel Gelman, Frank Durgin and Lisa Kaufman
* Intention as psychological cause / David Premack and Ann James
Premack Part IV: Causal understanding in naive biology * Causal constraints
on categories and categorical constraints on biological reasoning
across cultures / Scott Atran * The growth of causal understandings
of natural kinds / Frank C. Keil * On the origin of causal understanding
/ Susan Carey Part V: Understanding social causality * Anthropology,
psychology, and the meanings of social causality / Lawrence A. Hirschfeld
* The looping effects of human kinds / Ian Hacking Part VI: The legitimacy
of domain-specific causal understandings: Philosophical considerations
* Causality at higher levels / Philip Pettit * The role of content
in the explanation of behaviour / Pierre Jacob Part VII: Domain-general
approaches to causal understanding * The role of coherence in differentiating
genuine from spurious causes / Patricia W. Cheng and Yunnwen Lien
* Logic and language in causal explanation / Denis J. Hilton Part
VIII: Causal understanding in cross-cultural perspective * Ancient
Greek concepts of causation in comparativist perspective / Geoffrey
Lloyd * The articulation of circumstance and causal understandings
/ Gilbert Lewis * Causal attribution across domains and cultures
/ Michael W. Morris, Richard E. Nisbett and Kaiping Peng * Causal
understandings in cultural representations: Cognitive constraints
on inferences from cultural input / Pascal Boyer Afterword [by] David
Premack and Ann James Premack Biographical notes on the contributors
Subject index
Sperber, D. and Wilson, D. (1995).
Relevance: Communication and cognition (2nd ed.).
Blackwell Publishers, Malden, MA, US.
[ bib ]
(from the preface) In this book, . . . we present a new approach to
the study of human communication. This approach . . . is grounded
in a general view of human cognition. Human cognitive processes,
we argue, are geared to achieving the greatest possible cognitive
effect for the smallest possible processing effort. To achieve this,
individuals must focus their attention on what seems to them to be
the most relevant information available. To [verbally] communicate
is to claim an individual's attention: hence to communicate is to
imply that the information communicated is relevant. This fundamental
idea . . . that communicated information comes with a guarantee of
relevance [is referred to as the] communicative principle of relevance.
We argue that this principle of relevance is essential to explaining
human communication, and show . . . how it is enough on its own to
account for the interaction of linguistic meaning and contextual
factors in utterance interpretation. (PsycINFO Database Record (c)
2004 APA, all rights reserved); (Abbreviated) Preface to second edition
List of symbols Communication Inference Relevance Aspects of verbal
communication Postface Notes to first edition Notes to second edition
Notes to postface Bibliography Index
Keywords: principle of relevance & interaction of linguistic meaning & contextual
factors & cognitive processes in verbal communication; Cognition;
Cognitive Processes; Verbal Communication; Attention; Inference;
Psychosocial Factors; Verbal Meaning
Spirtes, P., Glymour, C., and Scheines, R. (2000).
Causation, Prediction, and Search,.
New York, N.Y.: MIT Press., 2nd ed. edition.
[ bib ]
Spitzer, M. (1997).
A cognitive neuroscience view of schizophrenic thought disorder.
Schizophrenia Bulletin, 23:29--50.
[ bib ]
Spring, J. (1992).
Nine ways to play.
American Demographics, 14:26--33.
[ bib ]
Springer, K. and Keil, F. (1991).
Early differentiation of causal mechanisms appropriate to biological
and nonbiological kinds.
Child Development, 62:767--781.
[ bib ]
Springer, K. and Murphy, G. (1992).
Feature availability in conceptual combination.
Psychological Science, 3:111--117.
[ bib ]
Starkey, D. (1981).
The origins of concept formation: Object sorting and object
preference in early infancy.
Child Development, 52:489--497.
[ bib ]
Stein, G. (1922/1992).
Geography and Plays.
The University of Wisconsin Press.
[ bib ]
Stewart, N. and Brown, G. D. A. (2004).
Sequence effects in categorizing tones varying in frequency.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 30:416--430.
[ bib ]
Stewart, N. and Brown, G. D. A. (2005).
Similarity and dissimilarity as evidence in perceptual
categorization.
Journal of Mathematical Psychology, 49:403--409.
[ bib ]
Stewart, N., Brown, G. D. A., and Chater, N. (2002).
Sequence effects in categorization of simple perceptual stimuli.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 28:3--11.
[ bib ]
Stewart, N. and Morin, C. (2007).
Dissimilarity is used as evidence of category membership in
multidimensional perceptual categorisation: A test of the
similarity-dissimilarity generalised context model.
Quarterly Journal of Experimental Psychology, 60:1337--1346.
[ bib ]
Steyvers, M. and Malmberg, K. J. (2003).
The effect of normative context availability on recognition memory.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 29:760--766.
[ bib ]
Storms, G. and De Boeck, P. (1997).
Formal models for intracategoricalstructure that can be used for
data-analysis.
In Lamberts, K. and Shanks, D., editors, Knowledge, concepts,
and categories, chapter Formal models for intracategoricalstructure that can
be used for data-analysis, pages 439--459. UCL Press, London.
[ bib ]
Storms, G., De Boeck, P., Hampton, J. A., and Van Mechelen, I. (1999).
Predicting conjunction typicalities by component typicalities.
Psychonomic Bulletin & Review, 6:677--684.
[ bib ]
Storms, G., De Boeck, P., and Ruts, W. (2001).
Categorization of novel stimuli in well-known natural concepts: A
case study.
Psychonomic Bulletin & Review, 8:377--384.
[ bib ]
Storms, G., De Boeck, P., Van Mechelen, I., and Ruts, W. (1996).
The dominance effect in concept conjunctions: Generality and
interaction aspects.
Journal of Experimental Psychology: Learning, Memory, &
Cognition, 22:1--15.
[ bib ]
Storms, G., Navarro, D. J., and Lee, M. D. (2010).
Introduction to the special issue on formal modeling of semantic
concepts.
Acta Psychologica, 133:213--215.
[ bib ]
Strange, W., Keeney, T., Kessel, F., and Jenkins, J. (1970).
Abstraction over time of prototypes from distortions of random dot
patterns.
Journal of Experimental Psychology, 83:508--510.
[ bib ]
Strauss, M. (1979).
Abstraction of prototypical information by adults and 10-month-old
infants.
Journal of Experimental Psychology: Human Learning and Memory,
5:618--632.
[ bib ]
Strevens, M. (2000).
The essentialist aspect of naive theories.
Cognition, 74(2):149 -- 175.
[ bib |
DOI ]
Recent work on children's inferences concerning biological and chemical
categories has suggested that children (and perhaps adults) are essentialists
? a view known as psychological essentialism. I distinguish three
varieties of psychological essentialism and investigate the ways
in which essentialism explains the inferences for which it is supposed
to account. Essentialism succeeds in explaining the inferences, I
argue, because it attributes to the child belief in causal laws connecting
category membership and the possession of certain characteristic
appearances and behavior. This suggests that the data will be equally
well explained by a non-essentialist hypothesis that attributes belief
in the appropriate causal laws to the child, but makes no claim as
to whether or not the child represents essences. I provide several
reasons to think that this non-essentialist hypothesis is in fact
superior to any version of the essentialist hypothesis.
Strevens, M. (2001).
Only causation matters: reply to ahn et al.
Cognition, 82(1):71 -- 76.
[ bib |
DOI ]
Stukken, L., Verheyen, S., Dry, M. J., and Storms, G. (2009).
A new investigation of the nature of abstract categories.
In Taatgen, N. A. and van Rijn, H., editors, Proceedings of
the 31st Annual Conference of the Cognitive Science Society, pages
2438--2443. Cognitive Science Society, Austin, TX.
[ bib ]
Sutcliffe, J. P. (1993).
Concepts, class, and category in the tradition of aristotle.
In Van Mechelen, I., Hampton, J. A., Michalski, R. S., and Theuns,
P., editors, Categories and concepts: Theoretical views and inductive
data analysis, chapter Concepts, class, and category in the tradition of
Aristotle, pages 35--65. Academic Press, London, UK.
[ bib ]
Sweetser, E. (1990).
From etymology to pragmatics: Metaphorical and cultural aspects
of semantic structure.
Cambridge University Press.
[ bib ]
Swoyer, C. (1996).
Theories of properties: From plenitude to paucity.
Philosophical Perspectives, 10:243--264.
[ bib ]
Tabossi, P. (1988).
Effects of context on the immediate interpretation of unambiguous
nouns.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 14:153--162.
[ bib ]
Tanaka, J. and Taylor, M. (1991).
Object categories and expertise: Is the basic level in the eye of the
beholder?
Cognitive Psychology, 15:121--149.
[ bib ]
Tarrant, M. and North, A. C. (2004).
Explanations for positive and negative behavior: The intergroup
attribution bias in achieved groups.
Current Psychology, 23(2):161--172.
ID: 15537523; M3: Article; Accession Number: 15537523; Tarrant, Mark
1North, Adrian C. 1; Affiliations: 1: University of Leicester; Source
Information: Summer2004, Vol. 23 Issue 2, p161; Thesaurus Term: SOCIAL
groups; Subject Term: ATTRIBUTION (Social psychology)Subject Term:
BEHAVIORSubject Term: GROUP identitySubject Term: GROUPS; Number of Pages:
12p; Illustrations: 2 charts, 3 graphs; Document Type: Article.
[ bib |
http ]
Previous research into intergroup attribution has addressed mainly
the behavior of groups to which members are ascribed (e.g. gender,
race). The attribution processes of groups of which membership is
achieved (e.g. friendship groups) is less well understood, and the
current study sought to address this. Fifty-five undergraduate participants
were asked to explain the positive and negative behavior of a member
of the in-group and a member of the out-group. As predicted, the
participants attributed an in-group member's positive behavior more,
and their negative behavior less, to internal. global, and specific
causes than they did the corresponding behavior of an out-group member.
There was also evidence that the participants employed a strategy
of out-group derogation in their attributions: they made a higher
internality rating for an out-group member's negative behavior than
they did for that person's positive behavior. It is proposed that
the current study's use of achieved groups maximized participants'
levels of group identification, and that this in turn motivated behavioral
strategies aimed at protecting that identity.ABSTRACT FROM AUTHOR
Keywords: SOCIAL groups; ATTRIBUTION (Social psychology); BEHAVIOR; GROUP identity;
GROUPS
Taylor, J. (1995).
Linguistic categorization: Prototypes in linguistic theory (2nd
ed.).
Oxford University Press.
[ bib ]
Thagard, P. (1994).
Explaining scientific change: Integrating the cognitive and the
social.
Proceedings of the Biennial Meetings of the Philosophy of
Science Association, 2: 298-303:--3033.
[ bib ]
Keywords: SOCIAL
Thagard, P. (1996).
The representational and the presentational: An essay on cognition
and the study of mind : Benny shanon, hemel hempstead, harvester wheatsheaf,
1993.
Acta Psychologica, 91(1):96--97.
[ bib |
http ]
Thagard, P. (1998).
Explaining disease: Correlations, causes, and mechanisms.
Minds and Machines, 8(1): 61-78):--78.
[ bib ]
Thagard, P. (2000).
Explaining disease: Correlations, causes and mechanisms.
In Keil, F. and Wilson, R., editors, Explanation and Cognition,
chapter 10, pages 255--276. MIT, Cambridge, MA.
[ bib ]
(from the chapter) This chapter discusses why some features of concepts
are more central than others. The authors begin with a review of
possible determinants of feature centrality, then focus on one important
determinant, the effects of causal background knowledge on feature
centrality. The different approaches to understanding feature centrality
(content-based, statistical, and theory-based) are addressed, then
a general introduction is made to the Causal Status hypothesis. The
authors present their rationale for predicting the causal status
effect and empirical results supporting the hypothesis under various
contexts. They describe previous categorization studies that can
be accounted for by this hypothesis, and discuss moderating factors
for the effect. Finally, they examine the potential consequences
of focusing only on causal relations among features in study the
effect of lay theories on feature centrality. (PsycINFO Database
Record (c) 2003 APA, all rights reserved)
Thagard, P. and Smythe, W. E. (2001).
Coherence in thought and action.
Canadian Psychology, 42(3):240--241.
[ bib |
http ]
Thagard, P. and Verbeurgt, K. (1998).
Coherence as constraint satisfaction.
Cognitive Science, 22(1):1--24.
[ bib |
http ]
This paper provides a computational characterization of coherence
that applies to a wide range of philosophical problems and psychological
phenomena. Maximizing coherence is a matter of maximizing satisfaction
of a set of positive and negative constraints. After comparing five
algorithms for maximizing coherence, we show how our characterization
of coherence overcomes traditional philosophical objections about
circularity and truth
Keywords: Truth
THAGARD, P. R. (1978).
The best explanation: Criteria for theory choice.
Journal of Philosophy, 75: 76-92:--922.
[ bib ]
Keywords: EXPLANATION, THEORY
Thissen, D. and Steinberg, L. (1986).
A taxonomy of item response models.
Psychometrika, 51:567--577.
[ bib ]
Thomas, R. D. (1998).
Learning correlations in categorization tasks using large,
ill-defined categories.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 24:119--143.
[ bib ]
Thompson, C. (1999).
New word order: The attack of the incredible grading machine.
Lingua Franca, 9(5):28--37.
[ bib ]
Trout, J. D. (2002).
Scientific explanation and the sense of understanding.
Philosophy of Science, 69:212 -- 233.
[ bib ]
Tuerlinckx, F. and De Boeck, P. (2004).
Models for residual dependencies.
In De Boeck, P. and Wilson, M., editors, Explanatory item
response models: A generalized linear and nonlinear approach, chapter Models
for residual dependencies, pages 289--316. Springer, New York, NY.
[ bib ]
Tuerlinckx, F. and De Boeck, P. (2005).
Two interpretations of the discrimination parameter.
Psychometrika, 70:629--650.
[ bib ]
Tuerlinckx, F., Molenaar, D., and van der Maas, H. L. J. (2014).
Diffusion-based response time modeling.
In Handbook of modern item response theory (Vol. 2). Chapman
& Hall.
[ bib ]
Tversky, A. (1977).
Features of similarity.
Psychological Review, 84:327--352.
[ bib ]
Tversky, A. and Gati, I. (1982).
Similarity, separability, and the triangle inequality.
Psychological Review, 89:123--154.
[ bib ]
Tversky, A. and Kahneman, D. (1973).
Availability: A heuristic for judging frequency and probability.
Cognitive Psychology, 5:207--232.
[ bib ]
Tversky, A. and Kahneman, D. (1982).
Judgments of and by representativeness, pages 84--98.
Cambridge University Press.
[ bib ]
Tversky, A. and Kahneman, D. (1983).
Extensional versus intuitive reasoning: The conjunction fallacy in
probability judgment.
Psychological Review, 90:293--315.
[ bib ]
Keywords: Judgment
Tversky, B. and Hemenway, K. (1983).
Categories of environmental scenes.
Cognitive Psychology, 15:121--149.
[ bib ]
Tversky, B. and Hemenway, K. (1984).
Objects, parts, and categories.
Journal of Experimental Psychology: General, 113:169--193.
[ bib ]
Twilley, L. C., Dixon, P., Taylor, D., and Clark, K. (1994).
University of Alberta norms of relative meaning frequency of 566
homographs.
Memory & Cognition, 22:111--126.
[ bib ]
Vallecher, R. and Wegner, D. (1987).
What do people think they're doing? action identification and human
behavior.
Psychological Review, 94:3--15.
[ bib ]
Vallée-Tourangeau, F., Anthony, S. H., and Austin, N. G. (1998).
Strategies for generating multiple instances of common and ad hoc
categories.
Memory, 6:555--592.
[ bib ]
van Deemter, K. (2010).
Not exactly: In praise of vagueness.
Oxford University Press, New York, NY.
[ bib ]
Van den Noortgate, W. and Paek, I. (2004).
Person regression models.
In De Boeck, P. and Wilson, M., editors, Explanatory item
response models: A generalized linear and nonlinear approach, chapter Person
regression models, pages 167--187. Springer, New York, NY.
[ bib ]
Van Fraassen, B. C. (1980).
The Scientific Image.
Oxford : Clarendon.
[ bib ]
Keywords: Explanation, Logic, Philosophy, Philosophy of Science, Science - Philosophy
Van Mechelen, I. and Storms, G. (1995).
Analysis of similarity data and Tversky's contrast model.
Psychologica Belgica, 35:85--102.
[ bib ]
Van Ravenzwaaij, D., Moore, C. P., Lee, M. D., and Newell, B. R. (2014).
A hierarchical Bayesian modeling approach to searching and stopping
in multi-attribute judgment.
Cognitive Science, 38:1384--1405.
[ bib ]
Vandekerckhove, J., Verheyen, S., and Tuerlinckx, F. (2010).
A crossed random effects diffusion model for speeded semantic
categorization decisions.
Acta Psychologica, 133:269--282.
[ bib ]
Vanpaemel, W., Ameel, E., and Storms, G. (2011).
Is prototypical typical? An investigation using semantic concepts.
Manuscript submitted for publication.
[ bib ]
Vanpaemel, W. and Navarro, D. J. (2007).
Representational shifts during category learning.
In McNamara, D. and Trafton, G., editors, Proceedings of the
29th Annual Conference of the Cognitive Science Society, pages
1599--1604. Erlbaum, Mahwah, NJ.
[ bib ]
Verbeemen, T., Storms, G., and Verguts, T. (2003).
Determinants of speeded categorization in natural concepts.
Psychologica Belgica, 43:139--151.
[ bib ]
Verbeemen, T., Vanoverberghe, V., Storms, G., and Ruts, W. (2001).
The role of contrast categories in natural language concepts.
Journal of Memory and Language, 44:618--643.
[ bib ]
Verbeemen, T., Vanpaemel, W., Pattyn, S., Storms, G., and Verguts, T. (2007).
Beyond exemplars and prototypes as memory representations of natural
concepts: A clustering approach.
Journal of Memory and Language, 56:537--554.
[ bib ]
Verdoux, H. and van Os, J. (2002).
Psychotic symptoms in non-clinical populations and the continuum of
psychosis.
Schizophrenia Research, 54:59--65.
[ bib ]
Verguts, T., De Boeck, P., and Storms, G. (1998).
Analyzing experimental data using the Rasch model.
Behavior Research Methods, 30:501--505.
[ bib ]
Verheyen, S., Ameel, E., Rogers, T. T., and Storms, G. (2008).
Learning categories at different levels of abstraction.
In Love, B. C., McRae, K., and Sloutsky, V. M., editors,
Proceedings of the 30th Annual Conference of the Cognitive Science
Society, pages 751--756. Cognitive Science Society, Austin, TX.
[ bib ]
Verheyen, S., Ameel, E., and Storms, G. (2011a).
Overextensions that extend into adolescence: Insights from a
threshold model of categorization.
In Carlson, L., Hölscher, C., and Shipley, T. F., editors,
Proceedings of the 33rd Annual Conference of the Cognitive Science
Society, pages 2000--2005. Cognitive Science Society, Austin, TX.
[ bib ]
Verheyen, S., De Deyne, S., Dry, M. J., and Storms, G. (2011b).
Uncovering contrast categories in categorization with a probabilistic
threshold model.
Journal of Experimental Psychology: Learning, Memory, &
Cognition, 37:1515--1531.
[ bib ]
Verheyen, S., Hampton, J. A., and Storms, G. (2010).
A probabilistic threshold model: Analyzing semantic categorization
data with the Rasch model.
Acta Psychologica, 135:216--225.
[ bib ]
Verheyen, S. and Storms, G. (2007).
Modeling individual differences in learning hierarchically organised
categories.
Psychologica Belgica, 47:219--234.
[ bib ]
Verheyen, S. and Storms, G. (2013).
A mixture approach to vagueness and ambiguity.
PLoS ONE, 8(5):e63507.
[ bib ]
Verheyen, S. and Storms, G. ().
Does a single dimension govern categorization in natural language
categories?
In Karmiloff-Smith, A., Kokinov, B., and Nersessian, N., editors,
Proceedings of the European Conference on Cognitive Science.
[ bib ]
Verheyen, S., Storms, G., and De Neys, W. (2009).
Confirmatory factor analysis of the three-factor structure of the
flemish schizotypal personality questionnaire.
Manuscript in preparation.
[ bib ]
Verheyen, S., Stukken, L., De Deyne, S., Dry, M. J., and Storms, G. ().
The generalized polymorphous concept account of graded structure in
abstract categories.
Memory & Cognition.
[ bib ]
Von Davier, M. and Yamamoto, K. (2004).
Partially observed mixtures of IRT models: An extension of the
generalized partial-credit model.
Applied Psychological Measurement, 28:389--406.
[ bib ]
von Eckardt, B. (1993).
What is cognitive science?
MIT Press, Cambridge, MA.
[ bib ]
Voorspoels, W., Storms, G., and Vanpaemel, W. (2013).
Similarity and idealness in goal-derived categories.
Memory & Cognition, 41:312--327.
[ bib ]
Voorspoels, W., Vanpaemel, W., and Storms, G. (2008).
Modeling typicality: Extending the prototype view.
In Love, B. C., McRae, K., and Sloutsky, V. M., editors,
Proceedings of the 30th Annual Conference of the Cognitive Science
Society, pages 757--763. Cognitive Science Society, Austin, TX.
[ bib ]
Voorspoels, W., Vanpaemel, W., and Storms, G. (2010a).
Ideals in a similarity space.
In Ohlsson, S. and Catrambone, R., editors, Proceedings of the
32nd Annual Conference of the Cognitive Science Society, pages
2290--2295. Cognitive Science Society, Austin, TX.
[ bib ]
Voorspoels, W., Vanpaemel, W., and Storms, G. (2010b).
Ideals in similarity space.
In Ohlsson, S. and Catrambone, R., editors, Proceedings of the
32nd Annual Conference of the Cognitive Science Society, pages
2290--2295. Cognitive Science Society, Austin, TX.
[ bib ]
Voorspoels, W., Vanpaemel, W., and Storms, G. ().
Contrast in natural language concepts: An exemplar-based approach.
In Carlson, L., Hölscher, C., and Shipley, T. F., editors,
Proceedings of the 33rd Annual Conference of the Cognitive Science
Society.
[ bib ]
Vosniadou, S. and Brewer, W. F. (1994).
Mental models of the day/night cycle.
Cognitive Science, 18:123--183.
[ bib ]
Investigated elementary school children's explanations of the day/night
cycle (DNC). 20 1st-, 20 3rd-, and 20 5th-grade Ss (aged 6-21 yrs)
were asked to explain certain phenomena, such as the disappearance
of the sun during the night, the disappearance of stars during the
day, the movement of the moon, and the alteration of day and night.
The majority of Ss consistently used relatively well-defined mental
models (MMs) of the earth, the sun, and the moon to explain the DNC.
These MMs were empirically accurate, logically consistent, and revealed
some sensitivity to issues of simplicity of explanation. Younger
Ss formed initial MMs that provided explanations of the DNC cycle
based on everyday experience. Older Ss constructed synthetic MMs
that represented attempts to synthesize the culturally accepted view
with aspects of their initial models. A few of the older Ss appeared
to have constructed a DNC MM similar to the scientific one. (PsycINFO
Database Record (c) 2003 APA, all rights reserved)
Keywords: *Age Differences, *Cognitive Processes, *Models, 1st vs 3rd vs 5th
graders, Adulthood (18 yrs & older), Childhood (birth-12 yrs), Cognitive
& Perceptual Development [2820]., Cognitive science, Empirical Study,
Explanation, Human, mental models for explanation of day/night cycle,
Models, School Age (6-12 yrs), Science
Vygotsky, L. (1965).
Thought and language.
MIT Press.
[ bib ]
Ward, T. (1993).
Processing biases, knowledge, and context in category
formation, pages 257--282.
Academic Press.
[ bib ]
Ward, T., Becker, A., Hass, S., and Vela, E. (1991).
Attribute availability and the shape bias in children's category
generalization.
Cognitive Development, 6:143--167.
[ bib ]
Wason, P. C. (1966).
Reasoning.
In Foss, B. M., editor, New horizons in psy- chology. Penguin,
H a r m o n d s w o r t h.
[ bib ]
Wattenmaker, W. (1993).
Incidental concept learning, feature frequency, and correlated
properties.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 19:203--222.
[ bib ]
Wattenmaker, W. (1995).
Knowledge structures and linear separability: Integrating information
in object and social categorization.
Cognitive Psychology, 28:274--328.
[ bib ]
Wattenmaker, W., Dewey, G., Murphy, T., and Medin, D. (1986).
Linear separability and concept learning: context, relational
properties, and concept naturalness.
Cognitive Psychology, 18:158--194.
[ bib ]
Waxman, S. (1990).
Linguistic biases and the establishment of conceptual hierarchies:
Evidence from preschool children.
Cognitive Development, 5:123--150.
[ bib ]
Waxman, S. and Gelman, R. (1986).
Preschoolers' use of superordinate relations in classification and
language.
Cognitive Development, 1:139--156.
[ bib ]
Waxman, S. and Klibanoff, R. (2000).
The role of comparison in the extension of novel adjectives.
Developmental Psychology, 36:571--581.
[ bib ]
Waxman, S. and Kosowski, T. (1990).
Nouns mark category relations: Toddlers' and preschoolers'
word-learning biases.
Child Development, 61:1461--1473.
[ bib ]
Waxman, S., Lynch, E., Casey, K., and Baer, L. (1997).
Setters and samoyeds: The emergence of subordinate level categories
as a basis for inductive inference in preschool-age children.
Developmental Psychology, 33:1074--1090.
[ bib ]
Waxman, S. and Markow, D. (1995).
Words as invitations to form categories: Evidence from 12- to
13-month-old infants.
Cognitive Psychology, 29:257--302.
[ bib ]
Waxman, S. and Markow, D. (1998).
Object properties and object kind: Twenty-one-month-old infants'
extensions of novel adjectives.
Child Development, 69:1313--1329.
[ bib ]
Waxman, S. and Namy, L. (1997).
Challenging the notion of a thematic preference in young children.
Developmental Psychology, 33:555--567.
[ bib ]
Waxman, S., Shipley, E., and Shepperson, B. (1991).
Establishing new subcategories: The role of category labels and
existing knowledge.
Child Development, 62:127--138.
[ bib ]
Weber, E. U. and Johnson, E. J. (2009).
Mindful judgment and decision making.
Annual Review of Psychology, 60:53--85.
[ bib ]
Wellman, H. (1990).
The child's theory of mind.
MIT Press.
[ bib ]
Wells, H. (1930).
The island of Dr. Moreau.
Dover Books.
[ bib ]
Whittlesea, B. (1987).
Preservation of specific experiences in the representation of general
knowledge.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 13:3--17.
[ bib ]
Wiemer-Hastings, K. and Xu, X. (2005).
Content differences for abstract and concrete concepts.
Cognitive Science, 29:719--736.
[ bib ]
Wilcox, T. and Baillargeon, R. (1998a).
Object individuation in infancy: The use of featural information in
reasoning about occlusion events.
Cognitive Psychology, 37:97--155.
[ bib ]
Wilcox, T. and Baillargeon, R. (1998b).
Object individuation in young infants: Further evidence with an
event-monitoring paradigm.
Developmental Science, 1:127--142.
[ bib ]
Wilson, D. and Sperber, D. (2003).
Relevance theory.
In G., H. L. . W., editor, Handbook of Pragmatics. Blackwell,
Oxford.
[ bib |
www: ]
Wilson, R. and Keil, F. (2000).
The shadows and shallows of explanation, chapter 4, pages
87--114.
Explanation and Cognition. MIT Press, Cambridge, Massachusetts.
[ bib ]
Keywords: Cognition
Wilson, R. A. (1992).
Individualism, causal powers, and explanation.
Philosophical Studies, 68(2):103 -- 139.
[ bib |
DOI |
http ]
Wilson, R. A. and Keil, F. (1998a).
Cognition and explanation.
Minds and Machines, 8(1): 1-5):--5.
[ bib ]
Keywords: COGNITION, EXPLANATION
Wilson, R. A. and Keil, F. (1998b).
The shadows and shallows of explanation.
Minds and Machines, 8(1): 137-159):--159.
[ bib ]
Keywords: EXPLANATION
Wisniewski, E. (1995).
Prior knowledge and functionally relevant features in concept
learning.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 21:449--468.
[ bib ]
Wisniewski, E. (1996).
Construal and similarity in conceptual combination.
Journal of Memory and Language, 35:434--453.
[ bib ]
Wisniewski, E. (1997).
When concepts combine.
Psychonomic Bulletin & Review, 4:167--183.
[ bib ]
Wisniewski, E., Imai, M., and Casey, L. (1996).
On the equivalence of superordinate concepts.
Cognition, 60:269--298.
[ bib ]
Wisniewski, E. and Love, B. (1998).
Relations versus properties in conceptual combination.
Journal of Memory and Language, 38:177--202.
[ bib ]
Wisniewski, E. and Middleton, E. (2002).
Of bucket bowls and coffee cup bowls: Spatial alignment in conceptual
combination.
Journal of Memory and Language, 46:1--23.
[ bib ]
Wisniewski, E. and Murphy, G. (1989).
Superordinate and basic category names in discourse: A textual
analysis.
Discourse Processes, 12:245--261.
[ bib ]
Wisniewski, E. J. and Medin, D. L. (1994).
On the interaction of theory and data in concept learning.
Cognitive Science, 18(2):221--281.
[ bib |
http ]
Standard models of concept learning generally focus on deriving statistical
properties of a category based on data (i.e., category members and
the features that describe them) but fail to give appropriate weight
to the contact between people's intuitive theories and these data.
Two experiments explored the role of people's prior knowledge or
intuitive theories on category learning by manipulating the labels
associated with the category. Learning differed dramatically when
categories of children's drawings were meaningfully labeled (e.g.,
"done by creative children") compared to when they were labeled in
a neutral manner. When categories are meaningfully labeled, people
bring intuitive theories to the learning context. Learning then involves
a process in which people search for evidence in the data that supports
abstract features or hypotheses that have been activated by the intuitive
theories. In contrast, when categories are labeled in a neutral manner,
people search for simple features that distinguish one category from
another. Importantly, the final study suggests that learning involves
an interaction of people's intuitive theories with data, in which
theories and data mutually influence each other. The results strongly
suggest that straight-forward, relatively modular ways of incorporating
prior knowledge into models of category learning are inadequate.
More telling, the results suggest that standard models may have fundamental
limitations. We outline a speculative model of learning in which
the interaction of theory and data is tightly coupled. The article
concludes by comparing the results to recent artificial intelligence
systems that use prior knowledge during learning
Keywords: Knowledge
Wittgenstein, L. (1953).
Philosophical investigations.
Blackwell.
[ bib ]
Wolfe, M., Schreiner, M., Rehder, B., Laham, D., Foltz, P., Kintsch, W., and
Landauer, T. (1998).
Learning from text: Matching readers and texts by latent semantic
analysis.
Discourse Processes, 25:309--336.
[ bib ]
Wolff, P., Medin, D. L., and Pankratz, C. (1999).
Evolution and devolution of folkbiological knowledge.
Cognition, 73(2):177--204.
[ bib |
http ]
In this paper we present evidence in support of the hypothesis that
the average person's knowledge about trees, and about the natural
world in general, has declined during the 20th century. Our investigations
are based on examination of a large sample of written material from
the 16th through 20th centuries contained in the Oxford English Dictionary.
In Analysis 1, we show a precipitous decline in the use of tree terms
after, but not before, the 19th century. In Analysis 2, we analyze
tree terms at different levels of organization and show that the
decline observed in Analysis 1 occurs for all levels of organization.
This second analysis also reveals that during the 16th to 19th centuries
tree terms became progressively more specific, suggesting that during
these periods knowledge about trees increased. In Analysis 3, we
show similar rates of decline in other folkbiological categories,
indicating that the change in tree terms reflects a general decline
in knowledge about living kinds. Also in Analysis 3, we show that
several non-biological categories have experienced evolution during
the 20th century, indicating that the declines in the 20th century
for folkbiological categories are not an inevitable outcome of the
corpus. Finally, Analysis 4 also shows declines in the frequency
of quotations for which the tree term was not the topic of the sentence,
and thus incidental to the purposes of the writer. The results from
Analysis 4 reassure us that the results from Analyses 1-3 were not
solely due to change in the aims and purposes of writers over the
centuries. In sum, the analyses indicate that in the domain of trees,
there has been a long and sustained period of conceptual evolution
followed by a recent pronounced period of devolution
Keywords: Hypothesis, Knowledge
Woo-kyoung, A. and Kim, N. S. (2000).
Causal status as a determinant of feature centrality.
Cognitive Psychology, 41(4):361--.
[ bib ]
Presents information on a study which examined causal status as a
determinant of feature centrality. Theory-based categorization; Causal
status hypothesis; Reason people weigh causes than effects; What
causal status hypothesis does and does not predict; Methodology;
Results and discussion
Woods, C. M. (2006).
Careless responding to reverse-worded items: Implications for
confirmatory factor analysis.
Journal of Psychopathology and Behavioral Assessment,
28:189--194.
[ bib ]
Woodward, A. and Markman, E. (1998).
Early word learning, pages 371--420.
Wiley.
[ bib ]
Woodward, J. (2003).
Making Things Happen: A Theory of Causal Explanation.
Oxford University Press, Oxford, UK.
[ bib ]
Wright, L. (1973).
Functions.
The Philosophical Review, 82(2):139 -- 168.
[ bib ]
Wright, L. (1976).
Teleological explanations.
University of California Press, Berkeley, CA.
[ bib ]
Keywords: Explanation; Teleology; Function; Causal reasoning; Philosophy of
science
Xu, F. (1997).
From lot's wife to a pillar of salt: Evidence that physical object is
a sortal concept.
Mind & Language, 12:365--392.
[ bib ]
Xu, F. and Carey, S. (1996).
Infants' metaphysics: The case of numerical identity.
Cognitive Psychology, 30:111--153.
[ bib ]
Xu, F. and Carey, S. (2000).
The emergence of kind concepts: A rejoinder to needham and
baillargeon.
Cognition, 74:285--301.
[ bib ]
Xu, F., Carey, S., and Welch, J. (1999).
Infants' ability to use object kind information for object
individuation.
Cognition, 70:137--166.
[ bib ]
Yamauchi, T. and Markman, A. (1998).
Category learning by inference and categorization.
Journal of Memory and Language, 39:124--148.
[ bib ]
Yamauchi, T. and Markman, A. (2000).
Inference using categories.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 26:776--795.
[ bib ]
Yang, L.-X. and Lewandowsky, S. (2003).
Context-gated knowledge partitioning in categorization.
Journal of Experimental Psychology: Learning, Memory, and
Cognition, 29:663--679.
[ bib ]
Younger, B. (1992).
Developmental change in infant categorization: The perception of
correlations among facial features.
Child Development, 63:1526--1535.
[ bib ]
Younger, B. and Cohen, L. (1985).
How infants form categories, pages 211--247.
Academic Press.
[ bib ]
Younger, B. and Gotlieb, S. (1988).
Development of categorization skills: Changes in the nature or
structure of infant form categories?
Developmental Psychology, 24:611--619.
[ bib ]
Zacks, J. and Tversky, B. (2001).
Event structure in perception and cognition.
Psychological Bulletin, 127:3 -- 21.
[ bib ]
Zacks, J. M., Tversky, B., and Iyer, G. (2001).
Perceiving, remembering, and communicating structure in events.
Journal of Experimantal Psychology: General, 130:29 -- 58.
[ bib |
www: ]
How do people perceive routine events, such as making a bed, as these
events unfold in time? Research on knowledge structures suggests
that people conceive of events as goal-directed partonomic hierarchies.
Here, participants segmented videos of events into coarse and fine
units on separate viewings; some described the activity of each unit
as well. Both segmentation and descriptions support the hierarchical
bias hypothesis in event perception: Observers spontaneously encoded
the events in terms of partonomic hierarchies. Hierarchical organization
was strengthened by simultaneous description and, to a weaker extent,
by familiarity. Describing from memory rather than perception yielded
fewer units but did not alter the qualitative nature of the descriptions.
Although the descriptions were telegraphic and without communicative
intent, their hierarchical structure was evident to naive readers.
The data suggest that cognitive schemata mediate between perceptual
and functional information about events and indicate that these knowledge
structures may be organized around object/action units.
Zadeh, L. (1965).
Fuzzy sets.
Information and control, 8:338--353.
[ bib ]
Zadeh, L. (1982).
A note on prototype theory and fuzzy sets.
Cognition, 12:291--297.
[ bib ]
Zeigenfuse, M. D. and Lee, M. D. (2009).
Bayesian nonparametric modeling of individual differences: A case
study using decision-making on bandit problems.
In Taatgen, N. and van Rijn, H., editors, Proceedings of the
31st Annual Conference of the Cognitive Science Society, pages
1412--1417. Cognitive Science Society, Austin, TX.
[ bib ]
Zipf, G. (1945).
The meaning-frequency relationship of words.
Journal of General Psychology, 33:251--256.
[ bib ]
Appendix A: WinBUGS code for the two-groups mixture IRT model
#I<- number of individuals
#O<- number of candidate objects
#G<- number of groups
#z<- group membership
#beta<- idealness
#alpha<- scaling parameter
#theta<- standard
#pi<- probability of group membership
#mu<- mean group standard
model
{
for (i in 1:I) {
for (o in 1:O) {
tt[i,o]<- exp(alpha[z[i],1]*
(beta[z[i],o] - theta[i]))
p[i,o]<-tt[i,o]/(1 + tt[i,o])
r[i,o]~dbern(p[i,o])
}
theta[i] ~ dnorm(mu[z[i]],1)
z[i] ~ dcat(pi[1:G])
}
}
Appendix B: Simulation studies
Both Li et al. [2009] and Cho et al. [2013]
present simulation studies that elucidate certain aspects of mixture
IRT models, including model selection and choice of priors. As
suggested by reviewers, we here describe two additional simulation
studies. The first simulation study pertains to the behavior of the
employed model selection criterion (BIC) when indivduals’ choices are
completely independent. The second simulation study is intended to
elucidate the results for the categories in which the model selection
criterion identified a “rest” group along a group of consistently
behaving individuals (things to put in your car and
wedding gifts). We will show that it is plausible to think of
this “rest” group as a haphazard group of individuals, just like the
individuals from the first simulation study.
Both in simulation study 1 and in simualtion study 2, we simulated
choices of 254 participants for 25 objects. The number of simulated
participants equals the number of participants in our empirical
study. The number of objects equals that of the largest categories in
our empirical study (things not to eat/drink when on a diet
and wedding gifts). The data were generated according to the
model formula in Equation (1). We set α to 1.5 and
varied βo from −3 to 3 in steps of .25. (These values are
representative for the ones we observed in our empirical study.)
Individual θi’s were drawn from the standard normal
distribution. To generate data for independent decision makers, the
βo’s were permuted for every new individual. They comprised
all 254 participants in simulation study 1 and 54 participants (21%)
in simulation study 2. The remaining 200 participants in simulation
study 2 were assumed to employ the same criterion for their choices,
but to differ regarding the standard they emposed on it. That is, to
generate data for the consistent individuals the same βo’s
were used (varying between −3 and 3 in steps of .25) and only the
θi’s differed. Five simulated data sets were created in this
manner for simulation study 1 and for simulation study 2. While the
data sets in simulation study 1 are in effect comprised of
independent choices (as evidenced by Kappa coefficients close to
zero), the data sets in simulation study 2 each comprise a subgroup of
heterogeneous decision makers (similar to the study 1 participants)
and a subgroup of consistently behaving decision makers.
Each of the ten data sets was analyzed in the same manner as the
empirical data sets in the main text. For each of the five simulated
data sets in simulation study 1, the BIC favored the one-group
solution, with the averages across data sets for the one- to
five-groups solutions equaling 8540, 8671, 8784, 8906, and 9036. This
result is in line with our intuitive introduction of how the mixture
IRT model works. It relies on consistent behavior across participants
to abstract one or more latent dimensions. Without common ground on
which the decisions are based, the conservative BIC favors the least
complex account of the data. The model parameters and the posterior
predictive distributions in this case testify to the fact that this
group should be considered a haphazard group of individuals. The range
of the mean βo’s, for instance, is rather restricted
([−.63,.70] compared to the “empirical” range [−3,3]), yielding
selection probabilities close to .50 for all objects. The posterior
predictive distributions of the one-group model for the selection
proportions resemble the circular outlines in the lower panel of
Figure 4 (see text below for details). The fact
that these distributions are wide compared to the observed differences
between objects should be a red flag as well.
When the participants are comprised of a consistently behaving group
and a group of heterogeneous decision makers, the BIC is able to pick
up on this. The BIC values in Table 3 favor a
two-groups solution for each of the simulation study 2 data sets. The
solutions are 99% accurate (1262/1270) in allocating individuals to
their respective groups (consistent vs. heterogenous) based on the
posterior mode of zi. Only once was an individual belonging to
the consistent group placed in the heterogeneous group. On seven
occasions an individual from the heterogenous group was placed in the
consistent group. While the former misallocation represents a true
error, the same does not necessarily hold for the latter ones. The
choice pattern of any of the heterogeneous individuals could by chance
resemble the choice pattern of the consistent group. The generating
βo’s are also recovered well. The correlation between the
generating values and the posterior means of the βo’s is
greater than .99 for all five data sets.
Table 3: BIC values for simulation study 2 data sets.
Set
1 group
2 groups
3 groups
4 groups
5 groups
1
6180
5433
5535
5674
5820
2
6142
5368
5497
5631
5774
3
6193
5311
5439
5578
5726
4
6136
5305
5443
5583
5728
5
6176
5334
5455
5591
5734
Figure 4: Posterior predictive distribution of the one-group model
(upper panel) and the two-groups model (lower panel) for data set
1 from simulation study 2. Filled black circles show per object
the selection proportion for the heterogeneous group. Filled gray
squares show per object the selection proportion for the
consistent group. Objects are ordered along the horizontal axes
according to the generating βo values for the consistent
group. Outlines of circles and squares represent the posterior
predictive distributions of selection decisions for the
heterogeneous and consistent group, respectively. The size of
these outlines is proportional to the posterior mass that is given
to the various selection probabilities.
Figure 4 presents the posterior predictive
distributions for data set 1 from simulation study 2 in a similar
manner as Figures 2 and
3 did. Both panels contain for every
object a black circle that represents the selection proportion for the
heterogeneous group and a gray square that represents the selection
proportion for the dominant, consistent group. Unlike the
demonstration in the main text, this division of participants is based
on known group membership, instead of inferred. Objects are ordered
along the horizontal axes according to the generating βo
values for the consistent group. In accordance with the manner in
which the data were generated, the selection proportions for the rest
group are close to .50, while the selection proportions for the
consistent group show a steady increase.
The upper panel in Figure 4 shows the posterior
predictive distributions of selection probabilities that result from
the one-group model. The lower panel shows the posterior predictive
distributions that result from the two-groups model. For every object
the panels include a separate distribution for each subgroup (circular
outlines for the rest group; square outlines for the consistent
group). The size of the plot symbols is proportional to the posterior
mass given to the various selection probabilities. The larger,
consistent group dominates the results for the one-group model. The
posterior predictive distributions tend toward the selection
proportions of this dominant group but are not really centered on the
empirical proportions because the one-group model is trying to
accommodate the choices from the heterogeneous group as
well. Especially for objects with selection proportions that are
considerably smaller or considerably larger than .50, the posterior
predictive distributions are being pulled away from the consistent
selection proportions toward the heterogeneous group’s selection
proportions. The two-groups model, on the other hand, distinguishes
between heterogeneous and consistent responses. The posterior
predictive distributions for the consistent group are tightly centered
around the empirical selection proportions, while the posterior
predictive distributions for the heterogeneous group vary more widely
around a selection proportion of .50 for all objects. Although the
latter distribution is not as wide as in the empirical cases, this
pattern is reminiscent of the one observed in the main text for the
categories things not to eat/drink when on a diet and
wedding gifts. It supports the interpretation that for these
categories the mixture IRT model identified a group of heterogeneous
decision makers, that is best regarded as not following the same
selection principle as the consistent group (a “rest” group). In a
more general sense, the simulation results stress the importance of
inspecting the posterior predictive distributions before turning to a
substantial interpretation of the results.
Faculty of
Psychology and Educational Sciences, Tiensestraat 102 Box 3711, University of Leuven, 3000 Leuven, Belgium. Email:
steven.verheyen@ppw.kuleuven.be.
Steven Verheyen and Wouter Voorspoels are both postdoctoral fellows
at the Research Foundation - Flanders. We would like to thank
Feiming Li for generously providing the details of various model
selection methods for mixture IRT models. We are grateful to Sander
Vanhaute and Thomas Ameel for their help with collecting data.
Figure 1 also
demonstrates that the inter-object differences are not really
pronounced. The respondents appear to agree that the majority of
candidate objects are things you use to bake an apple
pie. This does not leave much opportunity for latent group
differences to be detected. That would require a number of objects
for which opinions regarding their selection differ considerably.
Both the posterior mean of the mixture probability
πg and the posterior mode of zi can be used to assess
the relative importance or size of the groups. For our purposes the
choice is not substantial. For a more elaborate discussion of how
these values can be used see
Bartlema et al. [2014].
Either the members of these two groups have
opposing goals when dieting (e.g., losing weight versus gaining
weight) or the answer pattern of the smaller group may be the result
of carelessness with respect to the negatively-worded category
description (see Barnette [2000], Schmitt and Stuits [1985], and
Woods [2006], for examples of the latter, well-documented
phenomenon).