| Figure 1: Median decision times across levels of the number of reasons in line with the PH (error bars represent one standard error). |
Judgment and Decision Making, vol. 3, no. 6, August 2008, pp. 457-462
One-reason decision making in risky choice? A closer look at the priority heuristicBenjamin E. Hilbig* |
Although many models for risky choices between gambles assume that information is somehow integrated, the recently proposed priority heuristic (PH) claims that choices are based on one piece of information only. That is, although the current reason for a choice according to the PH can vary, all other reasons are claimed to be ignored. However, the choices predicted by the PH and other pieces of information are often confounded, thus rendering critical tests of whether decisions are actually based on one reason only, impossible. The current study aims to remedy this problem by manipulating the number of reasons additionally in line with the choice implied by the PH. The results show that participants’ choices and decision times depend heavily on the number of reasons in line with the PH — thus contradicting the notion of non-compensatory, one-reason decision making.
Keywords: priority heuristic, prospect theory, non-compensatory
strategy, one-reason decision making, fast and frugal heuristics, risky
choice.
The adaptive toolbox metaphor, put forward by Gigerenzer and co-workers (Gigerenzer, 2001; Gigerenzer, Todd, & The ABC Research Group, 1999), implies that decision makers possess and use a collection of simple rules of thumb — the so-called fast-and-frugal heuristics — to achieve very good results with very little effort. Since it was originally formulated, the toolbox has been rapidly growing and new heuristics are introduced almost regularly. Despite Bröder’s (2003) criticism that “inventing more and more new heuristics may soon become futile if they are not seriously tested empirically” (p. 622) the adaptive toolbox was recently extended to preferential decisions by means of the priority heuristic (PH, Brandstätter, Gigerenzer, & Hertwig, 2006) — a simple lexicographic rule for choices between gambles. Although the idea of adaptive decision making in choice is, in itself, not novel (e.g. Payne, Bettman, & Johnson, 1993), the PH represents a new development in this area.
Brandstätter et al. (2006) concluded that the PH outperforms both normative and other heuristic models in predicting participants choices. Also, they claim that it represents a process model of choice, describing the sequence of steps taken by a decision maker’s cognitive apparatus. Both claims have been seriously questioned and substantial debates about the properties of the PH (Birnbaum, 2008a; Brandstätter, Gigerenzer, & Hertwig, 2008; Johnson, Schulte-Mecklenbeck, & Willemsen, 2008; Rieger & Wang, 2008) and, more generally, the plausibility of the fast-and-frugal-heuristics approach (Dougherty, Franco-Watkins, & Thomas, 2008; Gigerenzer, Hoffrage, & Goldstein, 2008) have arisen.
One serious caveat to studies investigating the PH lies in the selection of gambles used: The choice predicted by the PH and the gamble favored by other pieces of information are often confounded. Thus, adherence rates to the PH, or modal choices as studied by Brandstätter et al. (2006) might be biased measures of whether participants’ decisions are truly based on one reason only, as claimed by the PH. The current study aims to remedy this problem. First, the choice rule of the PH will be introduced along with a description of the problem of confounded information in gamble-pairs. Then, an experiment will be reported in which the number of pieces of information confounded with the choice predicted by the PH was systematically varied to test whether participants actually base their choices on one piece of information only.
In the simple case of non-negative two-outcome gambles comprising a minimum gain, a maximum gain, and according probabilities, the PH claims that the following steps are taken by a decision maker: First, an aspiration level is computed which is 1/10 of the largest maximum gain (rounded to the nearest prominent number, Brandstätter et al., 2006). If the difference between the minimum gains exceeds this aspiration level, the gamble with the larger minimum gain is chosen; thus, information search is stopped after one piece of information has been examined (henceforth PH1 case) and all probabilities and maximum gains are ignored. If this is not the case, the probabilities (of the minimum gains) are considered: should these differ by at least .10 the gamble with the smaller probability (for the minimum gain) is chosen. So, search is terminated after the second reason has been examined (thus labeled PH2 case) and a choice is made ignoring all gains. Finally, if the probabilities yield no such difference, the maximum gains are considered (PH3 case) and the gamble comprising the larger maximum gain is chosen. No trade-offs are made and thus there is no integration of information in the process.
Although the PH can be easily extended to multiple-outcome and negative-outcome gambles, its niche is limited by the following bounding conditions: The expected values of the gambles may differ by a maximal ratio of 2:1, thus rendering choices adequately difficult (Brandstätter et al., 2006, 2008). Moreover, cases of strict dominance are excluded (Brandstätter et al., 2006), even though such cases could be expected to be handled smoothly by any heuristic (Rieger & Wang, 2008). Taken together, these bounding conditions limit the PH’s applicability to less than 50% of a randomly generated set of gamble-pairs as shown through simulation (Birnbaum, 2008a). However, this limitation by no means rules out that the process predictions of the PH are adequate in those cases to which it is argued to apply.
As Brandstätter et al. (2006) demonstrate, the PH is successful at predicting majority choices in different sets of gambles. Specifically, the authors show that it can predict modal choices better than quite a number of other models — including the most recognized: cumulative prospect theory (Tversky & Kahneman, 1992). However, these results have been challenged and others have shown that cumulative prospect theory and the transfer of attention exchange model (e.g., Birnbaum, 2004) are likely to outperform the PH when more diagnostic gambles are used and when competing models are allowed appropriate parameter fitting (Birnbaum, 2008a, 2008b; Glöckner & Betsch, in press). In sum, whenever the PH and competing models made different predictions, choices were mostly in line with the latter.
However, there is an inherent problem in some investigations of whether participants adhere to the PH: Often, multiple pieces of information imply the same choice as the PH. As a consequence, it is not always possible to conclude which piece of information — or which combination of the latter — led to a given choice. The following example illustrates this problem: Considering gambles A (4,000; .50; 1,300; .50) and B (3,900; .35; 1000; .65) the PH would predict choice of gamble A since it comprises the more attractive probabilities (and since the minimum gains differ by less than 1/10 of the largest maximum gain). However, the minimum gains, the maximum gains, and the expected values (which are 2,850 and 1,430, respectively) all imply the same decision as the PH. Thus, choice of gamble A cannot imply that (only) the probabilities were considered in the decision process. By contrast, one can construct gamble-pairs for which the choice implied by the PH is not in line with any other piece of information. Deciding between gambles C (4,000; .40; 1,200; .60) and D (3,150; .50; 950; .50) is such an example: The PH would predict choice of gamble D in line with the probabilities (for the same reason as in the former example). However, the minimum gains, the maximum gains, and the expected values (which are 2,640 and 2,050, respectively) all imply choice of gamble C.
Since the PH claims that choices are always based on one piece of information only, the number of other reasons in line with the choice implied by the PH should be inconsequential. Stated bluntly, participants’ adherence to the PH should not depend on the number of additional reasons in line the PH — since these additional reasons are claimed to be ignored. So, in the above examples, choice of gamble A over B should be just as likely as choice of gamble D over C. By contrast, any strategy which integrates different pieces of information would predict that choices in line with the PH should increase with the number of reasons additionally in line with the PH’s prediction.
Moreover, according to the PH, participants’ decision times should also not be affected by the number of reasons in line with the PH: in the above examples, decision makers should first consider the minimum gains, then move on to the probabilities (since the minimum gains do not differ sufficiently in both cases), and upon doing so stop search and make a choice. Thus, they should take equally long to choose A over B and D over C. Alternatively, one might claim that the choice between gambles A and B should afford less time than choice between gambles C and D since in the former case all reasons imply the same decision (gamble A) whereas in the latter case the probabilities (speaking for gamble D) contradict the choice implied by all other pieces of information (gamble C).
The predictions described above were tested in an experiment in which the number of reasons additionally in line with the choice implied by the PH was manipulated within participants. In the different gamble-pairs studied, which comprised the minimum gains, maximum gains, probabilities, and expected values as pieces of information, either none, one, two, or three (all) reasons were additionally in line with the PH. That is, there were four levels of additional reasons in line with the PH which varied within participants.
Gambles were randomly generated with maximum gains ranging from 1,000 to 5,000 (in steps of 50), minimum gains taking values between 0 and 1,500 (also in steps of 50), and probabilities varying from 0 to 1 (in steps of .05). Next, gambles were randomly paired and all pairs comprising dominance or ratios of expected values greater than 2:1 were excluded. Consequently, all gamble-pairs were within the PH’s niche as proposed by Brandstätter et al. (2006). Finally, 36 gamble-pairs were randomly selected: 9 gamble-pairs for each of the four levels of reasons in line with the PH (none, one, two, and three, respectively). Although there was no specific hypothesis concerning the different PH cases (PH1, PH2 and PH3, as described above) the number of these cases was held constant across the four levels of reasons in line with the PH. Thus, a four (levels of reason in line with the PH) by three (PH case — PH1, PH2, or PH3) matrix resulted, with a total of three gamble-pairs per cell. The gambles used are listed in the accompanying data file.1
The experiment was administered by means of a web-based questionnaire. First, participants were familiarized with the structure of the gambles used (all two-outcome, non-negative) and were instructed that their task was to choose which of two gambles they would prefer to play. Then, after an exemplary choice task, all 36 choices between gambles were presented separately, one after the other, in a predetermined randomized order which was the same for all participants. For each gamble the maximum gains, probabilities of maximum gains, minimum gains, and probabilities of minimum gains were presented. The expected values were not presented since this would most likely bias choices. Participants were instructed to respond speedily but to take the time they needed to make their choices. They were also told that there were no correct or false responses.
41 participants (37 female) were recruited from an undergraduate-course in psychology at the University of Mannheim. Participants were aged 19 to 68 (M = 22.8 years, SD = 8.5) and received partial course credit for their participation.
Averaging across all cases, the proportion of choices in line with the PH was M = 63% (SD = 6%) which is significantly above chance level, t(40) = 13.7, p < .001, Cohen’s d = 2.14. However, adherence rates differed substantially depending on the number of reasons in line with the PH: Table 1 shows the proportion of choices in line with the PH separately for the four levels of the number of additional reasons in line with the PH.
Table 1: Mean proportions of choices in line with the PH (standard deviations in parenthesis) for the four levels of the number of additional reasons in line with the PH. t-statistic and Cohen’s d for the difference from chance level (.50) for each of these means.
Mean (SD) t(40) Cohen’s d .19 (.15) –13.4* 2.1 .39 (.13) –5.4* 0.8 .96 (.11) 26.2* 4.1 .96 (.10) 28.4* 4.4 Note. * p < .001
As can be seen, participants adhered to the PH significantly below chance level whenever none or one additional reason was in line with the choice implied by the PH. By contrast, whenever two or three additional reasons implied the same decision as the PH, choices were largely in line with its predictions. All effect sizes can be considered to be large (Cohen, 1988). A repeated-measures ANOVA with adherence to the PH as dependent variable and the number of reasons in line with the PH as independent variable confirmed the differences between these four levels with F(2.2, 86.9)2 = 391.6, p < .001, ηp² = .91. Thus, participants’ choices depended largely on the number of additional reasons in favor of the choice implied by the PH.3
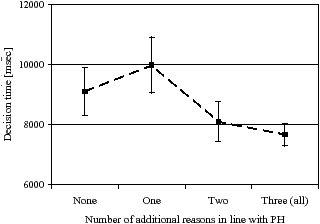
Next, decision times were analyzed. For each participant the median decision time (excluding the first of all 36 decisions) was computed separately for the four levels of the number of additional reasons in line with the PH. As depicted in Figure 1, participants had the longest decision times (M = 9900ms, SE = 930ms) when one additional reason was in line with the PH. Shorter decision times (M = 9100ms, SE = 790ms) were observed when no other piece of information was in line with the PH. The shortest decision times occurred whenever two (M = 8100ms, SE = 660ms) or all (M = 7700ms, SE = 370ms) other reasons predicted the same choice as the PH.
Figure 1: Median decision times across levels of the number of reasons in line with the PH (error bars represent one standard error).
A repeated-measures ANOVA with decision times as dependent variable and the number of reasons in line with the PH as independent variable confirmed the difference between these levels with F(1.6, 63.8) = 6.1, p < .001, ηp² = .132. In sum, decision times were longest whenever the different pieces of information conflicted most strongly (two vs. two); by contrast, decision times were substantially shorter with an increasing number of reasons implying the same choice.
Additionally, the analysis of decision times was repeated including only those cases in which participants adhered to the PH. In line with the previous analysis, median decision times decreased from M = 11086ms (SE = 1370ms) for no additional reason in line with the PH to M = 7491ms (SE = 374ms) when all reasons supported the PH (with M = 9619ms, SE = 1095ms and M = 7958ms, SE = 755ms, for one and two additional reasons, respectively). This effect of the number of reasons in line with the PH was again confirmed by a repeated-measures ANOVA, F(1.5, 64.2) = 6, p = .005, ηp² = .151. Stated simply, decisions in line with the PH afforded less time the more additional pieces of information supported the PH-consistent choice.4
Although the analyses reported clearly reveal an influence of the number of reasons in line with the PH, a plausible caveat needs to be addressed: possibly, individuals differ in the heuristics they use. More specifically, it may be that all participants use some non-compensatory priority-heuristic but that these heuristics differ in the order in which pieces of information are considered. Thus, what may look like compensatory decision-making on the aggregate level, may turn out to be a blend of different non-compensatory process at the individual level. To address this, all possible priority heuristics (with all possible orderings) were modeled and the model fitting each participants’ choices best5 was used for this participant (and will thus be denoted PHBEST in what follows). Table 2 depicts these models along with the number of participants for whom each model fitted best. As can be seen, most participants’ choices were explained best by a priority heuristic (PHiii) which considered differences in probabilities first, followed by differences in minimum gains.
Table 2: Additional priority heuristic models, order in which pieces of information are sampled, and number of participants (proportion in parenthesis) for whom each model fitted best.
Model Ordering N (%) of participants PHi* MinG, Prob., MaxG 1 (2.4) PHii MinG, MaxG, Prob. 9 (22) PHiii Prob., MinG, MaxG 19 (46.3) PHiv Prob., MaxG, MinG 0 PHv MaxG, Prob., MinG 10 (24.4) PHvi MaxG, MinG, Prob. 2 (4.9) Note. MinG = minimum gains, MaxG = maximum gains, Prob. = probabilities. * original PH model.
Next, the analyses concerning the impact of the number of additional reasons were repeated using the individually best-fitting priority heuristic for each participant. Concerning choices, a repeated-measures ANOVA with adherence to the PHBEST as dependent variable and the number of reasons in line with the PHBEST as independent variable revealed a significant and large effect, F(1.8, 70.6) = 194.5, p < .001, ηp² = .829. Specifically, choices in line with the PHBEST increased from M = .27 (SE = .03) when no additional reason was in line with the PHBEST to M = .60 (SE = .02), M = .94 (SE = .01), and M = .96 (SE = .02), for one, two, or three additional reasons, respectively. Thus, choices in line with the best-fitting priority heuristic for each participant were again strongly influenced by the number of additional reasons in line with the PHBEST which conflicts with the claim of one-reason decision making.
Likewise, median decision times for PHBEST showed the exact same pattern as in the previous analyses for the original PH model. That is, decision times were M = 9371ms (SE = 896ms) for no additional reason in line with PHBEST , increased to M = 9977 (SE = 940ms) for one additional reason, and then dropped to M = 8475ms (SE = 652ms) and M = 7673ms (SE = 367ms) for two and three additional reasons, respectively. This effect of the number of reasons additionally in line with PHBEST was confirmed by a repeated-measures ANOVA, F(1.7, 68.8) = 4.9, p = .014, ηp² = .109. Likewise, and in line with the analysis of the original PH model, decision times of only those cases in which participants adhered to the PHBEST dropped linearly across the levels of additional reasons in line with the PHBEST, again corroborated by a repeated-measures ANOVA, F(1.9, 64.2) = 5.5, p = .007, ηp² = .140. In sum, decision times for PHBEST comprised the same pattern reported for the original PH model and thus contradicting a non-compensatory decision process.
The recently proposed and controversially debated priority heuristic (PH, Brandstätter et al., 2006) represents a non-compensatory lexicographic strategy. As such, it claims that choices between gambles are based on the consideration of one piece of information only. In the current study, this notion was tested through disentangling adherence to the priority heuristic from the number of other reasons implying the same choice as the PH. Strictly speaking, reasons additionally in line with the PH should be inconsequential since all other pieces of information are claimed to be ignored. For the same reason, decision times should also not depend on these additional pieces of information.
Both predictions were tested using a set of randomly generated gambles which were all within the PH’s niche, that is, excluding cases of dominance and ratios of expected values greater than 2:1 (Brandstätter et al., 2006, 2008). The results obtained clearly contradict that choices are based on one piece of information only: Adherence to the PH depended substantially on the number of reasons additionally in line with its predictions. Whenever few (none or one) additional reasons implied the same choice as the PH, adherence rates to the heuristic were vastly below chance level. By contrast, whenever two or three (all) additional reasons backed up the PH, choices were virtually always in line with its predictions. It can thus be concluded that good predictive performance of the PH must be attributed to the fact that its prediction and the choices implied by other pieces of information are often confounded.
The results with respect to decision times also conflicted with the predictions derived from the PH: Choices took longest whenever the different pieces of information conflicted most (two implying choice of one gamble, the other two implying the opposite). If, by contrast, all pieces of information favored the same gamble, decisions were made notably faster. Such differences, however, rule out that only one piece of information was decisive, as claimed by the PH. Rather, decision times were well in line with the notion that different pieces of information are integrated and that choices become easier (and thus faster) whenever all reasons favor one option. Likewise, decisions in line with the PH were performed with increasing speed when the number of reasons in line with the PH increased. Theoretical explanations outlining a (potentially compensatory) model accounting for the reported patterns, however, must remain speculative at this point. Most obviously, the degree of conflict between different pieces of information seems to feed into longer decision times. This could, for example, be explained though a process which first determines how many reasons speak for each gamble before comparing options on certain attributes in case of conflict. However, future research advisably using process-tracing methods (e.g. Johnson et al., 2008) is clearly needed since any explanation herein will be post hoc and go untested.
Additionally, a different best-fitting priority heuristic for each individual was examined owing to the possibility that participants might all use non-compensatory priority heuristics which differ in the order in which pieces of information are considered. However, the results with respect to both choices and decision times again contradicted the claim of one-reason decision-making, since the number of additional reasons in line with the prediction of the individually best-fitting model had a substantial impact.
Note, however, that the analyses using the best-fitting priority heuristic for each participant are post-hoc and thus bear some limitations. Most importantly, they are no longer based on an equal number of cases for each level of additional reasons within or across participants and should thus be interpreted with caution. However, the reported results consistently show that even using different priority heuristics for each individual the claim of one-reason decision-making must be refuted.
Finally, it could be argued that the hypothesis and results presented herein are based on a rather literal implementation of the PH with fixed aspiration levels (minimal differences). Consequently, one may claim that allowing these to vary would strongly increase the fit of the PH. Although I readily acknowledge this, it seems unlikely that the effect of the number of additional reasons in line with the PH – especially on decision times — would vanish if these aspiration levels were allowed to vary. Also, letting aspiration levels vary would drastically increase the complexity of the PH model which is exactly what its proponents are aiming to avoid (Brandstätter et al., 2006, 2008).
In sum, one of the PH’s central advantages — its formulation as a process model — is turning out to be its downfall: different studies using different methods have consistently shown that choices between gambles are not based on one piece of information and that the steps claimed by the PH are not likely to be taken by decision makers (Glöckner & Betsch, in press; Hilbig & Markett, 2008; Johnson et al., 2008). Moreover, the heuristic’s predictive power is at least questionable (Birnbaum, 2008a, 2008b; Glöckner & Betsch, in press) and turns out to be rather poor whenever the PH is not backed up by other pieces of information as shown in this article.
Birnbaum, M. H. (2004). Causes of Allais common consequence paradoxes: An experimental dissection. Journal of Mathematical Psychology, 48(2), 87–106.
Birnbaum, M. H. (2008a). Evaluation of the priority heuristic as a descriptive model of risky decision making: Comment on Brandstätter, Gigerenzer, and Hertwig (2006). Psychological Review, 115(1), 253–260.
Birnbaum, M. H. (2008b). New tests of cumulative prospect theory and the priority heuristic: Probability-outcome tradeoff with branch splitting. Judgment and Decision Making, 3(4), 304–316.
Brandstätter, E., Gigerenzer, G., & Hertwig, R. (2006). Making choices without trade-offs: The priority heuristic. Psychological Review, 113(2), 409–432.
Brandstätter, E., Gigerenzer, G., & Hertwig, R. (2008). Risky choice with heuristics: Reply to Birnbaum (2008), Johnson, Schulte-Mecklenbeck, and Willemsen (2008), and Rieger and Wang (2008). Psychological Review, 115(1), 281–289.
Bröder, A. (2003). Decision making with the “adaptive toolbox”: Influence of environmental structure, intelligence, and working memory load. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29(4), 611–625.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, NJ: Lawrence Earlbaum Associates.
Dougherty, M. R., Franco-Watkins, A. M., & Thomas, R. (2008). Psychological plausibility of the theory of Probabilistic Mental Models and the Fast and Frugal Heuristics. Psychological Review, 115(1), 199–213.
Gigerenzer, G. (2001). The adaptive toolbox. In G. Gigerenzer & R. Selten (Eds.), Bounded rationality: The adaptive toolbox (pp. 37–50). Cambridge, MA: The MIT Press.
Gigerenzer, G., Hoffrage, U., & Goldstein, D. G. (2008). Fast and frugal heuristics are plausible models of cognition: Reply to Dougherty, Franco-Watkins, and Thomas (2008). Psychological Review, 115(1), 230–237.
Gigerenzer, G., Todd, P. M., & The ABC Research Group. (1999). Simple heuristics that make us smart. New York, NY: Oxford University Press.
Glöckner, A., & Betsch, T. (in press). Do people make decisions under risk based on ignorance? An empirical test of the priority heuristic against the cumulative prospect theory. Organizational Behavior and Human Decision Processes.
Hilbig, B. E., & Markett, S. A. (2008). On the priority of the priority heuristic: critical tests of a fast and frugal model for risky choice. Unpublished manuscript (submitted).
Johnson, E. J., Schulte-Mecklenbeck, M., & Willemsen, M. C. (2008). Process models deserve process data: Comment on Brandstätter, Gigerenzer, and Hertwig (2006). Psychological Review, 115(1), 263–272.
Payne, J. W., Bettman, J. R., & Johnson, E. J. (1993). The adaptive decision maker. New York, NY: Cambridge University Press.
Rieger, M. O., & Wang, M. (2008). What is behind the priority heuristic? A mathematical analysis and comment on Brandstätter, Gigerenzer, and Hertwig (2006). Psychological Review, 115(1), 274–280.
Tversky, A., & Kahneman, D. (1992). Advances in prospect theory: Cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5, 297–323.
This document was translated from LATEX by HEVEA.