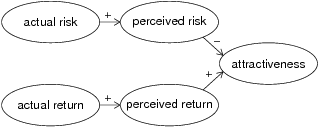
| Figure 1: The bottom-up model of risk perception. |
Judgment and Decision Making, vol. 3, no. 4, April 2008, pp. 317-324.
On the perception and operationalization of risk perceptionYoav Ganzach,* Shmuel Ellis, Asya Pazy, |
We compare and critique two measures of risk perception. We suggest that a single question — “How risky is the situation?” — captures the concept of risk perception more accurately than the multiple-item measure used by Sitkin and Weingart (1995). In fact, this latter measure inadvertently captures notions of attractiveness or expected return, rather than risk perception. We further propose that the error underlying the construction of Sitkin and Weingart’s measure is explained in terms of a top-down model of risk perception, in which perceived risk and perceived return are consequences, rather than determinants, of attractiveness. Two studies compare the validity of the two alternative measures.
Keywords: behavioral decision making; risk perception; judgment;
heuristics and biases; behavioral economics.
The concepts of risk, return and attractiveness are distinct concepts in the theory of decision making. Therefore, the empirical measurement of perceived risk should apply special care to avoid its contamination with perceived return and global evaluation (attractiveness), and to guard against inadvertent replacing of one kind of meaning with another. To demonstrate the ease by which these three concepts can be confused, and to understand the reasons for this confusion, we examine a measure of risk perception that was developed by Sitkin and Weingart (1995, to be abbreviated SW), and critique its validity as a measure of the concept of risk perception.1 We explain the erroneous construction of this measure within the framework of a top-down model of risk perception (Alhakami & Slovic, 1994; Finucane, Alhakami, & Slovic, 2000; Ganzach 2000), and we suggest that the error in constructing the measure reflects the inadvertent replacement of a top-down with a bottom-up perception of the relationships between perceived risk, perceived return and attractiveness. Empirical data provide support for these suggestions. We conclude with a discussion regarding the sources of confusion that occur in the conceptualization and operationalization of risk perception in behavioral research.
Figure 1 presents the standard prescriptive model for the relationships between perceived risk, expected return (to be abbreviated as return) and attractiveness under risk aversion (see, for example, Markowitz, 1953; Jia & Dyer, 1996; Sarin & Weber, 1993). In this bottom-up model of risk perception, perceived risk and return, which reflect actual risk and return, are the determinants of attractiveness: The lower the perceived risk and the higher the return, the more favorable will be the global evaluation or attractiveness.
This view is consistent with the common prescriptive distinction between risk and attractiveness in which risk connotes with and uncertainties, and is conceptually independent of return, whereas attractiveness connotes with global evaluation and preference, and is related both to risk and to expected return.
Recently, a number of researchers (Alhakami & Slovic, 1994; Finucane Alhakami, & Slovic, 2000; Ganzach 2000; Slovic & Peters, 2006) argued that perceptions of risk and return could often be understood by a top-down model of risk perception. The top-down model is consistent with the notion that a basic affective reaction underlies complex evaluations (the “affect heuristic.” See Kahneman, 2003; Slovic, Finucane, Peters, & MacGregor, 2002), and with the common view in psychology that specific perceptions and judgments are often derived from a global assessment (e.g., Bargh, 2002; Ledoux, 2000; Zajonc, 1998). The model, presented in Figure 2, suggests that perceptions of risk and return of a risky prospect are derived from an overall assessment of the prospect, an assessment which is based on a global attitude and preference towards the prospect. That is, according to this model, risky prospects are unidimensionally perceived on a continuum ranging from “good” to “bad.” If a prospect is perceived as good, it will be judged to have both high return and low risk, whereas if it is perceived as bad, it will be judged to have both low return and high risk.
Figure 1: The bottom-up model of risk perception.
The major testable hypothesis of the top-down model is that the correlation between perceived risk and perceived return is negative, regardless of the relationship between their actual risk and actual return, even though the environmental correlation between the two is usually positive. Alhakami and Slovic (1994) and Fincucane et al. (2000) tested and confirmed this hypothesis in the context of the perception of risk and benefits of advanced technologies, and Ganzach (2000) tested and confirmed this hypothesis in the context of the perception of the risk and return of financial assets. The current paper provides further evidence supporting this hypothesis.
In a widely cited work, Sitkin and his colleagues presented (Sitkin & Pablo, 1992) and tested (Sitkin & Weingart, 1995) a model of risk perception.2 In particular, Sitkin and Weingart (SW, 1995) examined the relationship between risk perception and decision under risk in two studies by presenting participants with a case involving a business risk in which the consequences of the decisions were presented as risky prospects with explicit probabilities and monetary outcomes. Perceived risk was measured by SW with a four-item instrument (α = 0.75). The first three items were answers to the question: “How would you characterize the decision?” given on three seven-point Likert type scales, the first ranging from significant opportunity (1) to significant threat (7), the second from potential for loss (1) to potential for gains (7) (reverse coded), and the third from positive situation (1) to negative situation (7). The fourth item was an answer to a question regarding the likelihood of success given on a seven-point Likert scale ranging from very unlikely (1) to very likely (7) (reversed coded).
Our critique of this instrument begins by illustrating the problematic validity of this 4-item scale through a very simple example. Consider two investments: Investment A offers a sure profit of $10. Investment B offers 50% probability of a profit of $100, and 50% probability of no profit (a profit of $0). Thus, investment A has no risk and offers low expected return, while investment B has both higher risk and higher expected return. It is clear that people perceive investment A as less risky (perfectly safe) than investment B. However, most people will also rate investment B as lower than A on SW’s instrument of “perceived risk.” That is, B is likely to be perceived as offering more opportunity, more potential for gain and as more positive than A, which, in SW’s scale, signifies lower risk. This example suggests that SW’s instrument might not be appropriate for measuring perceived risk (the riskier investment is rated lower on this instrument), but captures information about global evaluation or perhaps perceived return rather than perceived risk.
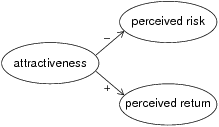
Figure 2: The top-down model of risk perception.
In the current paper we argue that the problem with SW’s measure of risk perception is that it measures global attitude or perceived return more than perceived risk. The four dimensions on which SW’s measure is based — opportunity-threat, gain-loss, positive-negative and success-failure — are all associated with an attitude of positive-negative evaluation, as well as (particularly the gain-loss continuum) with perceived return. However, these dimensions are inconsistent with the prescriptive notion of risk. In its prescriptive sense, a risky situation may involve opportunities as well as threats, potential for gains as well as potential for losses, negative as well as positive elements, and possibilities for success as well as possibilities for failure. Thus the face validity of SW’s instrument is, in our view, not clear at all.
To test the construct validity of the SW measure, we compare it to that of another commonly used measure, the single item measure of risk perception (e.g., Coombs, 1975; Payne, 1975; Pollatsek & Tversky, 1970; Shapira, 1995; Weber, Eblais & Betz, 2002). This measure consists of a single question: “How risky is the prospect?” accompanied by a Likert type scale ranging from “not at all risky” to “very risky.” The construct validity of the single item measure was supported in a number of studies. The results indicated that — at least with regard to risky prospects with explicit probabilities and outcomes — judgments of risk on this measure are correlated with standard features of risky prospects that are useful in making decisions (e.g., Mellers & Chang, 1994; Mellers, Chang, Birnbaum & Ordonez, 1992; Weber, Anderson & Birnbaum, 19923). In the following study, we use this single-item measure of risk perception as one of the criteria to which the validity of SW’s measure is compared.
We designed two experiments that provide a way to test the construct validity of the SW measure. Participants were presented with investment opportunities described as prospects with two or three outcomes, each having a well defined probability. These prospects have two advantages: (1) they have standard indicators of risk (and return), and (2) they were widely used in the risk perception literature (e.g. Payne, 1975, Weber et al., 1992).
Each of the experiments consisted of three conditions. In the first condition, participants judged the prospects on SW’s instrument of perceived risk (to be labeled SWrisk). In the second condition, they judged the prospect on the Single item measure of perceived risk (to be labeled Srisk). In the third condition, they judged the prospect on a Single item measure of perceived Return (to be labeled Sreturn). This design allows an examination of the construct validity of SW’s instrument. For this instrument to be a valid measure of risk perception, it should be highly correlated both with standard measures of risk (e.g., magnitude of loss, standard deviation of outcomes) and with the single item measure of risk perception. Furthermore, in the absence of a correlation between risk and return, it should also have low or no correlation either with a standard measure of return (e.g., expected value) and with the single item measure of perceived return.
Thirty six first-year undergraduate business students in an introductory psychology course participated in the experiment as part of a class requirement.
Participants received a questionnaire describing 8 risky prospects, presented as investment opportunities (see Table 1). The prospects involved two positive outcomes and one negative outcome, all with equal probabilities (1/3), and were designed to have a correlation of about zero between their risk (the size of the negative outcome) and expected return. The instructions to the participants were as follows: “Assume that you are an investor facing 8 possible investment possibilities. Each of these investments involves two gains and one loss. The loss stems from expenses associated with the investment, and the gains are net gains. Your task is to evaluate each of the investments on 6 scales. Before making your evaluations, please review all investments so you will be able to assess their relative value.”
Table 1: The experimental stimuli in Study 1.
Prospect Gain 1 Gain 2 Loss 1 120000 140000 30000 2 40000 60000 30000 3 110000 20000 60000 4 50000 160000 80000 5 70000 110000 50000 6 130000 240000 80000 7 150000 190000 50000 8 100000 190000 60000
Participants rated each of the 8 investments on 7-point Likert type scales. Two of the scales measured perceived risk and perceived return on single item measures. The anchors of the perceived risk scale (Srisk) were low risk (1) and high risk (7); the anchors of the perceived return scale (Sreturn) were low return (1) and high return (7). The other four scales measured perceived risk using the SW instrument (SWrisk) described above. A random half of the participants received the scales in this order and the other half in the reverse order. In addition, half of the participants received the 8 investments in one order and the other half in the reverse order.
Our first analysis involves the relationships between the standard measures of risk and return and the perception of risk, measured either by the Srisk or by SWrisk, as well as the perception of return, measured by Sreturn. For each participant we calculated the correlations of Srisk, SWrisk and Sreturn with the Expected Value of the investment (EV), and the loss associated with the investment (Loss), across the 8 investments he or she rated. The average correlations and their standard errors are given in Table 2.
The data in this table question the construct validity of SW instrument. In particular, the average (absolute) correlation between SWrisk and EV is 0.54, whereas the correlation between SWrisk and Loss is only .23 [t(35)=3.44 , p<0.005 for the difference between these two correlations.4], which suggests that SWrisk is more a measure of perceived return than of perceived risk.
Two additional findings are of interest in the data of Table 2. First, the average (absolute) correlation between Srisk and EV (0.38) does not differ significantly from the average correlation between Srisk and Loss (0.34), [t(35)=0.4, p>0.7]. Thus, although Srisk is not as biased towards EV as SWrisk, this result may question the validity of Srisk in this experiment. Second, the data in Table 2 support the validity of the single item measure of perceived return (Sreturn), because its average correlation with EV is high (0.68), whereas its average correlation with Loss is low (0.08).
Our second analysis involves the relationships between perception of risk, as measured either by the Srisk or by SWrisk, and the perception of return, as measured by Sreturn. For each participant we calculated the correlations between these three variables across the 8 prospects he or she rated. The average correlation between SWrisk and Sreturn was −0.63 (STDERR=0.04) whereas the average correlation between SWrisk and Srisk was even lower, 0.58 (STDERR=0.06), suggesting that the SW instrument does not discriminate between perceived return and perceived risk (at least when they are measured on the single item scales). The average correlation between Srisk and Sreturn was also somewhat high, 0.43 (STDERR= 0.06), but in absolute terms this correlation was significantly lower than the correlation between SWrisk and SRE, −0.64 (STDERR=0.04 [t(35)=3.51, p<0.00 for the difference between the two correlations], suggesting less bias.
Table 2: Means (standard errors) of the correlations between the standard measures of risk and return and their perceptions.
EV Loss Sreturn 0.68*** (0.05) 0.08 (0.05) Srisk −0.38*** (0.05) 0.35*** (0.05) SWrisk −0.54*** (0.06) 0.22*** (0.05) *** p<0.001 Srisk — single item measure of perceived risk Sreturn — single item measure of perceived return SWrisk — judgments on SW’s instrument EV — Prospects’ expected value Loss — Value of loss
The results of the study indicate that SW’s instrument is not a valid measure of risk perception. It had a stronger association with an standard measure of expected return (EV) than with an standard measure of risk (Loss), and its relationship with perceived return (measured by Sreturn) was about the same as its relationship with perceived risk (measure by Srisk).
The single item measure of perceived risk was superior to SW’s instrument with regard to its association with standard measures of risk and return, and it had a weaker association with perceived return than the SW instrument, indicating that Srisk is a more valid measure of perceived risk than SWrisk.
Notwithstanding this comparison between Srisk and SWrisk, the results of Study 1 also raise questions regarding the validity of Srisk as a measure of perceived risk, since Srisk had a significant correlation both with Sreturn and EV. We note, however, that a correlation between a measure of perceived risk and standard/subjective measures of return does not necessarily compromise the validity of the measure since – consistent with the affect heuristic — expected returns often influence the perception of risk (e.g., Finucane et al, 2000).
Table 3: The experimental stimuli in Study 2.
Prospects’ group Low variance High variance Low EV High EV Low EV High EV 1 40, 60 120, 140 20, 80 100, 160 2 70, 110 110, 150 50, 130 90, 170 3 30, 50, 70 90, 110, 130 10, 50, 90 70, 110, 150 Note: EV stands for Expected Value. The numbers are the $ outcomes. The probabilities of the outcome of each prospect are 50% for the two outcome prospects and 33.3% for the three outcome prospects.
Study 2 differs from Study 1 in two main aspects. First, in Study 2 we use a between participants design. A within participants design may be problematic since the order in which risk and return judgments are made may have an important impact on the judgments. For example, Ganzach (2000, Experiment 2) found that the correlation between risk judgments and return judgments are positive (negative) when the risk judgments are made before (after) the return judgments. Second, whereas in Study 1 losses were explicit, in Study 2 all outcomes are positive and losses are implied. This makes prospects’ evaluation in this study similar to what is suggested by prescriptive utility theory, in which prospects are represented in terms of total wealth and utilities receive only positive value (in relation to a base-line of zero). It also allows us to use the most commonly used measure of risk of financial investments — the standard deviation of the outcomes — as our measure of standard risk (using the standard deviation when both positive and negative outcomes exist is problematic, because of the different weights that these two types of outcomes receive in risk perception).
Fifty-nine first-year undergraduate business students in an introductory psychology course participated in the experiment as part of a class requirement. The participants were randomly assigned to the three conditions.
Participants received a questionnaire describing 12 risky prospects presented as investment opportunities. They were asked to assume that they are managers of a corporation that face a number of business opportunities. Each of the opportunities involves a potential loss, since it requires the investment of company resources (such as labor, travel, equipment etc), but promise a positive stream of earnings after the investment of these resources.
The prospects involved two or three possible positive outcomes with equal probabilities, 50% in the two-outcome prospects and 33.3% in the three-outcome prospects. The prospects were designed to have a zero correlation between their risk and expected return: each prospect had one corresponding prospect with the same expected value but different variance, and another corresponding prospect with the same variance but a different expected value. Three groups of four prospects were thus created, so that within each group expected value and variance were orthogonal. The prospects are presented in Table 3.
Participants in the Srisk condition judged each of the 12 prospects on the single item measure of risk perception. Participants in the Sreturn condition judged the prospects on the single item measure of perceived. Participants in the SWrisk condition completed, for each prospect, a 3-item version of SW’s instrument from which the fourth item had been omitted. The fourth item was omitted because success likelihood was irrelevant to our experimental stimuli5.
For each participant we calculated two correlations: The correlation between her judgments and the expected value of the prospects and the correlation between her judgments and the standard deviation of the prospects (for the participants in the SWrisk condition we averaged the judgment of the three SW’s items). The means and standard errors of these correlations are given in Table 4.
Table 4: Average correlations (standard errors) between expected value, standard deviation and judgments in Study 2.
Condition Correlation with EV Correlation with SD Srisk −0.28** (0.09) 0.53*** (0.07) Sreturn 0.53*** (0.10) 0.13 (0.08) SWrisk −0.52*** (0.09) 0.00 (0.06) *** p<0.001; ** p<0.005 Srisk — single item measure of perceived risk Sreturn — single item measure of perceived return SWrisk — judgments on SW’s instrument EV — Prospects’ expected value SD — Prospects’ standard deviation
The results question the construct validity of SW’s instrument as a measure of risk perception. The judgments on SW’s instrument has a very low correlation with the standard deviation of the prospect’s outcomes (average correlation of 0.00), and it is highly correlated both with the expected value of the prospects (average correlation of −0.52). In fact, these data suggests that SW’s instrument is (when reverse coded) a measure of perceived return rather than a measure of perceived risk.
In contrast, the single item measure of risk perception seems to be a better measure of perceived risk. It is highly correlated with the standard deviation of the prospects (average correlation 0.53). It has, however, also a moderate correlation with expected value (average correlation of −0.28), which suggests that, consistent with the affect heuristic, return has some influence on perceived risk.
Finally, these data also support the validity of the single item measure of perceived return, since its average correlation with expected return is high 0.53 whereas its average correlation with the standard deviation is low, 0.13, and non-significant.
To further examine the construct validity of the two measures of risk perception we correlated (across the 12 prospects) the mean judgment of the Srisk and SWrisk groups with the mean judgments of the Sreturn group. The correlation between the mean judgment of the Srisk group and the mean judgment of the Sreturn group was low and non-significant (r=−0.19), suggesting that the single item of perceived risk is indeed not related to perceived return. On the other hand, the correlation between the mean judgment of the SWrisk group and the mean judgment of the Sreturn group was high (r=−0.81), suggesting again that SW’s instrument is, if anything, a measure of perceived return rather than perceived risk.
The results of the study indicate that SW’s instrument is not a valid measure of risk perception and suggest that it is related more to perceived (and actual) return than to perceived risk. On the other hand, the results also show that the single item measure of perceived risk (and of perceived return) do validly capture the constructs they claim to measure.
The very low correlation SWrisk with perceived risk and its very high correlation with perceived return are somewhat surprising. Although these findings, makes the problem associated with this instrument — aimed at measuring perceived risk and ending a proxy of perceived return — all the more salient, one is still perplexed why SW’s instrument is not more highly correlated with perceived risk, as would be the case if it were a measure of attractiveness. Therefore it seems that within the context of this study, SW’s instrument is more a measure of perceived return than a measure of attractiveness. One reason is that at least one of the SW scales — the gain-loss continuum — is an indicator of perceived return more than an indicator of attractiveness. Another possible reason is that, in the context of this study, which consisted only of positive outcome prospects, perceived return and attractiveness might be highly related. Finally, the zero correlation of SW’s measure with perceived risk could also be explained by the fact that in our experimental stimuli the range of the standard deviations of outcomes was large, although the range of expected values was narrow. Differences in attribute ranges may lead to differences in impact, such that attributes with a larger range have larger impact (Beattie & Baron, 1991; Mellers & Cooke, 1996). Note, however, that all these may potentially be detrimental to valid measures of risk perception as well. Yet, our results (i.e., the sensitivity of the single item measure of risk perception to the standard measure of risk) indicate that they were not detrimental to the single item measure of risk perception. This should increase our confidence in the validity of this latter measure.
The results of the study indicate that SW’s instrument is not a valid measure of risk perception and suggest that it is related more to perceived return than to perceived risk. On the other hand, the results also show that the single item measure of perceived risk (and of perceived return) do better in validly capture the constructs they claim to measure.
Within the framework of the top-down model of risk perception, the source of the error in SW’s measure of perceived risk lies in unduly associating risk with (un)attractiveness, and therefore using items that do not adequately discriminate between perceived risk and perceived return. In this sense the current results are similar to previous evidence regarding lack of discrimination between perceived risk and perceived return (Ganzach 2000). In Ganzach’s (2000) experiments the correlation between perceived return and perceived risk was negative, although the correlation between standard risk and return was positive. Similarly, the current results indicate that the correlation between perceived return and perceived risk, as measured by SW (1995), is negative, although the correlation between standard return and actual risk is about zero. Note, however, that in Ganzach’s (2000) studies, the discrepancy arises from a disparity between actual risk and its perception, whereas in the current study there is no difference between actual risk and its perceptions, and the discrepancy arises from a disparity between risk perception (as well as actual risk) and its measurement by SW’s instrument.
Although earlier publications argued for the usefulness of the concept of perceived risk and for the validity of its measurement (e.g., Weber et al., 1992), the current study is more in line with the idea that risk may have different meanings to different people in different situations (Ganzach, 2000; Finucane et al., 2000; Slovic et al., 2002), and that the context plays a central role in risk judgments. Thus, when judging the risk of lotteries, even naïve participants (e.g. undergraduates with no relevant training, such as the participants in our studies as well as other studies such as Mellers & Chang, 1994, and Mellers et al., 1992) provide risk judgments that are consistent with standard measures of risk and with prescriptive theories about the relationship between risk, return and attractiveness. On the other hand, when judging the risk of financial assets or when attempting to conceptualize risk perception, well-trained experts (e.g., financial analysts with extensive financial education, such as the participants in Ganzach’s, 2000, studies, or expert behavioral researchers of risk behavior such as in Sitkin & Weingart, 1995) provide risk judgments or construct research instruments that are inconsistent with standard measures of risk, and conflict with prescriptive theories about the relationship between risk, return and attractiveness.
As an epilogue we should note that Sitkin & Weingart instrument did not stand the test of time. Despite the wide citation of their work (see footnote 1), only two papers (Mital & Ross, 1998, and Kuvaas & Selart 2004) used their instrument. However, none of these papers used it as a measure of risk perception! Mital and Ross (1998. p. 312) used the (three item version of the) instrument as a measure of issue interpretation, defined as assessments about the degree to which an issue represents a threat or an opportunity (Mital & Ross, p. 299). And interestingly enough, Kuvaas and Selart (2004) used it as a measure of global evaluation (see p. 202). It seems that in a peculiar way Sitkin and Weingrat measure finally came to assess what it validly can assess. Nevertheless, we note that the research that was based on the early conclusions that were derived from SW use of this instrument proliferated (see footnote 2). Thus, it may be the case that even though the literature indeed does not use the measure, it nevertheless continues to develop the ideas derived from it.
Alhakami, A. & Slovic, P (1994) A psychological study of the inverse relationship between perceived risk and perceived benefit. Risk Analysis, 14, 1085–1096.
Bargh, J. A. (1997). The automaticity of everyday life. In R. S. Wyer Jr. (Ed.). The automaticity of everyday life: Advances is social cognition. (Vol. 10, pp 1–61). Mahwah, NJ: Erlbaum.
Beattie, J. & Baron, J. (1991). Investigating the effect of stimulus range on attribute weight. Journal of Experimental Psychology: Human Perception and Performance, 17, 571–585.
Coombs, C. H. & Lehner, P. E. (1981). Evaluation of two alternative models for a theory of risk: I. Are moments of the distributions useful in assessing risk? Journal of Experimental Psychology: Human Perception and Performance, 78, 1110–1123.
Eden, D. (2002). Replication, meta-analysis, scientific progress, and AMJ’s publication policy. Academy of Management Journal, 45, 841–846.
Finucane, M. L., Alhakami, A., Slovic, P. & Johnson, S. M. (2000). The affect heuristic in judgment of risks and benefits. Journal of Behavioral Decision Making, 13, 1–17.
Ganzach, Y. (2000). Judging risk and return of financial assets. Organizational Behavior and Human Decision Processes, 83, 353–370.
Jia, J. M. & Dyer, J. S. (1996). A standard measure of risk and risk-value models. Management Science, 42, 1691–1705
Kahneman, D. (2003). A prospective on judgment and choice. American Psychologist, 58, 697–720.
Kuvaas, M. & Selart B. (2004) Effects of attribute framing on cognitive processing and evaluation. Organizational Behavior and Human Decision Processes, 95, 198–207
Ledoux, J. E. (2000). Emotion circuits in the brain. Annual Review of Neroscience, 23, 155–184.
Lykken, D. T. (1968). Statistical significance in psychological research. Psychological Bulletin, 70, 151–159.
MacCrimmon, K. R. & Wehrung, D. A. (1985). A Portfolio of risk measures. Theory and Decision, 19, 1–29.
MacCrimmon, K. R. & Wehrung, D. A. (1986a). Taking Risks: The Management of Uncertainty. New York: Free Press.
MacCrimmon, K. R. & Wehrung, D. A. (1986b). Assesing risk propensity. In L. Daboni, A. Montesano & M. Lines (Eds.). Recent Developments in the foundations of utility and risk theory, pp. 291–309. Dordrecht: Dordrecht Reidel Publishing Company.
Markowitz, H. M. (1959). Portfolio Selection: Efficient Diversification of Investments. John Wiley & Sons, New Jersey.
Mellers, B. A., Chang, S. (1994). Representations of risk judgments. Organizational Behavior and Human Decision Processes, 57, 167–184.
Mellers, B. A., Chang, S., Birnbaum, M. & Ordonez, L. (1992). Prefernces, prices and rating in risky decision making. Journal of Experimental Psychology: Human Perception and Performance, 18, 347–361.
Mellers, B. A. & Cooke, A. D. J. (1996). The role of task and context in preference measurement. Psychological Science, 7, 76–81.
Mittal, V., & Ross, W. T. J. (1998). The impact of positive and negative affect and issue framing on issue interpretation and risk taking. Organizational Behavior and Human Decision Processes, 76, 298–324.
Nygren, T. E. (1997). The relationship between perceived risk and attractiveness of gambles: A multidimensional analysis. Applied Psychological Measurement, 1, 565–579.
Payne, J. W. (1975). Relation of perceived risk to preferences among gambles. Journal of Experimental Psychology: Human Perception and Performance. 1, 86–94.
Pollatsek, A. & Tversky, A. (1970). A theory of risk. Journal of Mathematical Psychology, 7, 540–553.
Sarin, R, K. & Weber, M. (1993). Risk value models. European Journal of Operational Research, 70 135–149.
Sitkin, S. B. & Pablo, A. L. (1992). Reconceptualizing the determinants of risk behavior. Academy of Management Review, 17, 9–38.
Sitkin, S. B. & Weingart, L. R. (1995). Determinants of risky decision making behavior: A test of the mediating role of risk perceptions and propensity. Academy of Management Journal, 38, 1573–1592.
Slovic, P. (1967 Coombs, C. H. & Lehner, P. E. (1981). Evaluation of two alternative models for a theory of risk: I. Are moments of the distributions useful in assessing risk? Journal of Experimental Psychology: Human Perception and Performance, 78, 1110–1123.
Slovic, P., Finucane, M. , Peters, E., & McCregor, D. G. (2002). The affect heuristic. In T. Gilovich, D. Griffin & D. Hahneman (Eds.). Heuristics and biases (pp. 397–420). New York: Cambridge University Press.
Slovic, P., Finucane, M., Peters, E. & MacGregor, D. (2002). The affect heuristic. In Griffin, D. & Gilovich, T. (Eds). Heuristics and biases: The psychology of intuitive judgment, 397–420. New York: Cambridge University Press.
Slovic, P., & Peters, E. (2006). Risk perception and affect. Current Directions in Psychological Science, 15, 322–325.
Weber, E. U., Anderson, C. J. & Birnbaum, M. H. (1992). A theory of perceived risk and attractiveness. Organizational Behavior and Human Decision Processes, 52, 492–523.
Weber, E. U., Eblais, A. & Betz. N. Y. (2002). A domain-specific risk-attitude scale: Measuring risk perceptions and risk behavior. Journal of Behavioral Decision Making, 15, 263–290.
Weber, E. U. & Milliman, R. A. (1997). Perceived risk attitudes : Relating risk perception to risky choice. Management Science, 43, 123–144.
Wehrung, D. A., Lee, K., Tse, D. K. & Vertinsky, I. B. (1989). Adjusting risky situations: a theoretical framework and empirical test. Journal of Risk and Uncertainty, 2, 189–212.
Zajonc, R. B. (1968). Attitudinal effects of mere exposure. Journal of Personality and Social Psychology Monographs Supplement, 9, 1–27.
Zajonc, R. B. (1998). Emotions. In D. T. Gilbert, S. T. Fiske & G. Linczey (Eds.). Handbook of Social Psycyology (4th ed., Vol. 1, pp. 591–632). New York: Oxford University Press.
This document was translated from LATEX by HEVEA.