| Means (SDs): | Simple vs. difficult | Regression results: | Correlations with: | ||||
| Self-reported comparative judgment | Simple | Difficult | effect size (h2) | b Self | b Other | Actual percentile | Actual score |
| Subjective relative self- rating (1-7 scale) | 4.96 (1.06) | 3.30 (1.59) | .29*** | 1.47*** | -0.93*** | .46*** | .66*** |
| Bet | $1.64 (1.02) | $1.01 (1.00) | .10*** | 1.40*** | -1.10** | .50*** | .45*** |
| Percentile rank (objective measure) | 58.8 (24.6) | 39.7 (27.5) | .14*** | 1.34*** | -0.97*** | .54*** | .51*** |
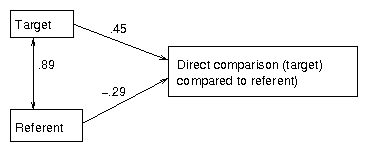
| Indirect comparison | 0.59 (1.34) | -0.77 (1.77) | .17*** | 2.07+ | -1.69+ | 0.47*** | 0.54*** |
Newspapers often tell us that "inflation increased by 2.9%" when they mean that prices increased by that much. The literature on risk effects of pollutants and pharmaceuticals commonly report relative risk, the ratio of the risk with the agent to the risk without it, rather than the difference. Yet, the difference between the two, not their ratio, is most relevant for decision making: if the risk is miniscule, a high relative risk still means very little. (p. 302).Various other research findings show the ways in which people conflate relative with absolute evaluations. Sometimes, people attend to absolute numbers when relative proportions are more meaningful. For example, Denes-Raj and Epstein (1994) found that people prefer to bet on an urn with 9 winning chips out of 100 rather than an urn with 1 winning chip out of 10. Similarly, people are more suspicious of sex discrimination on the grading of an exam when the man who got the highest grade was the only male among 10 test-takers than when he was one of the 10 males in a group of 100 test-takers (Miller, Turnbull, & McFarland, 1990). Other findings highlight the ways in which people attend to relative performance or to proportions when absolute counts are more meaningful. For example, Klein has found that willingness to change driving habits is more strongly influenced when people are told that their risk of accident is 20% above or below average than when they are told that their lifetime risk of being in an accident is 30% or 60% (Klein, 1997, 2002). In a related vein, people are more willing to contribute to the search for a cure that will cure 90% of sufferers than one that will cure 9% of sufferers, holding constant the number of people cured (Baron, 1997). One result of such thinking may be that governments spend a far greater amount of money for each human life saved on risks affecting few people - such as chemical spills or radiation exposure - than on risks that affect many people - such as road safety (McDaniels, 1988). This same reasoning has been implicated in the perceived futility of working to reduce world hunger: Even though helping a large number of people is relatively easy and inexpensive, it can only be a "drop in the bucket" compared to the total problem (Unger, 1996). Clearly, the conflation of relative and absolute quantities can have profound consequences.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||