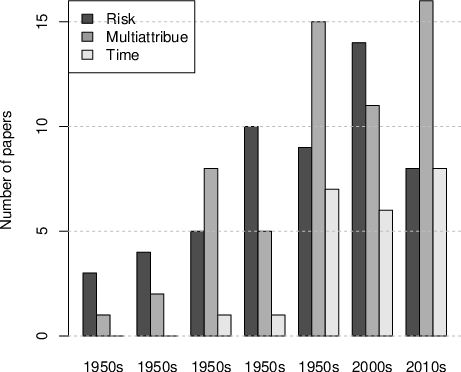
| Figure 1: The number of papers publishing unique decision models discussed in our synthesis, based on decade of publication. |
Judgment and Decision Making, Vol. 16, No. 6, November 2021, pp. 1324-1369
Establishing the laws of preferential choice behaviorSudeep Bhatia* Graham Loomes# Daniel Read$ |
Abstract: Mathematical and computational decision models are powerful tools for studying choice behavior, and hundreds of distinct decision models have been proposed over the long interdisciplinary history of decision making research. The existence of so many models has led to theoretical fragmentation and redundancy, obscuring key insights into choice behavior, and preventing consensus about the essential properties of preferential choice. We provide a synthesis of formal models of risky, multiattribute, and intertemporal choice, three important domains in decision making. We identify recurring insights discovered by scholars of different generations and different disciplines across these three domains, and use these insights to classify over 150 existing models as involving various combinations of eight key mathematical and computational properties. These properties capture the main avenues of theoretical development in decision making research and can be used to understand the similarities and differences between decision models, aiding both theoretical analyses and empirical tests.
Keywords: decision making, mathematical and computational modeling, risky choice, multiattribute choice, intertemporal choice
Decision making is a central topic in psychology, cognitive science, neuroscience, economics, finance, marketing, health, environmental sciences, and management (Barberis & Thaler, 2003; Baron, 2008; Bazerman & Moore, 2008; Camerer et al., 2011; Glimcher & Fehr, 2013; Kaplan & Frosch, 2005; Oppenheimer & Kelso, 2015; Seip & Wenstop, 2006; Simonson et al., 2001). Decision research is now also a significant driver of government policy (Halpern, 2016; Thaler & Sunstein, 2009). A major goal of decision research has been to describe, predict, and prescribe human choice behavior. This goal is often pursued by developing mathematical and computational decision models. These models transform the set of choice options available to the decision maker into deterministic or probabilistic choices. Much theoretical research has been devoted to generating new decision models, each making own assumptions about how payoffs, attribute levels, probabilities, time delays, and other components of choice options are transformed and combined to explain observed patterns of choice.
There is a profusion of such models. In preparing this paper, we identified over 150 distinct mathematical and computational models published before 2018 which are aimed at modeling choices. Typically, the choices modelled are binary (between two options) and the options themselves have only a few payoffs or attribute values. Inevitably, when there are so many models using so few inputs to predict a small set of choice patterns, the models overlap in their key properties. Moreover, with so many related models, often expressed using different terminology and notation, and interpreted using different intuitive psychological mechanisms, it is difficult for scholars to acquire a comprehensive view of the field and to keep up with the proliferation of new variants. This may result in redundancy and makes it difficult for new researchers to see the wood for the trees. Indeed, despite all this model development, unified theories of choice have not emerged, even over the relatively small set of behavioral regularities documented in the empirical literature.
The purpose of this paper is to synthesize seven decades of interdisciplinary theoretical decision making research, to provide a road map of existing decision models and to enable new and established researchers to locate their work on this map. We do this by identifying eight core mathematical and computational properties at play in preferential choice and using these to classify existing models. Our classification provides a way to identify similarities and differences between models and can be used to aid both theoretical analyses and empirical tests. It can also shed light on trends and patterns that have so far guided theoretical developments in decision research. More importantly, current and future researchers will be able to use our framework to increase their theoretical efficiency and encourage them to build on, rather than re-invent, the work of previous generations.
The great majority of ‘real-world’ decisions involve options that combine multiple attributes with a range of costs and benefits over time and various degrees of risk and uncertainty. In the face of such complexity, the approach adopted by decision researchers has been to subdivide the task and develop models in three domains, each focused on one aspect of overall choice. Typically, therefore, multiattribute choice models concern the values placed on objects or events with several characteristics, risky choice models concern how we weigh those values as a function of how likely they are to occur, and intertemporal choice models concern how we weigh those values as a function of when they occur. The models we discuss in this paper therefore form part of the constructive or “divide and conquer” approach to decision modeling, in that researchers systematically strive to understand each aspect of choice, before ultimately attempting to “put it all together” (Lichtenstein & Slovic, 2006).
As a consequence of this divide and conquer approach, decision researchers have mostly focused on simple choice tasks, rarely more complex than those shown in Table 1. The role of simple tasks like these has been likened to that of fruit flies in genetics, since they provide stripped-down scenarios that represent basic components of the choices people make in their everyday lives (Kahneman, 2000).
Table 1: Structure of a typical choice problem, with two choice options X and Y. The column labels represent events, moments in time, or attributes, and the individual cells, denoted xi and yi, are the resolutions for these columns (e.g. payoffs contingent on different events, payoffs obtained at different time periods, or realizations of different attributes).
The available options (the choice set) are represented by the rows labelled X and Y. Researchers have predominantly focused on cases where only one item can be chosen from a choice set. The interpretation of the columns depends on the domain: in multiattribute choice, they denote option attributes, features, or commodities; in the context of risk, they denote either collectively exhaustive and mutually exclusive states of the world, or collectively exhaustive and mutually exclusive probabilities; and in the context of intertemporal choice they denote specific moments in continuous time. To refer to the characterisations collectively, we will simply use the term column, but when the column has specific characteristics we will mention them. (Although our review will be limited to multiattribute choice, risky choice and intertemporal choice, the Table 1 structure is in fact rather more general: see Baron (2008) and Wakker (2010, Appendix D) for a similar approach that extends to other domains, including welfare theory and normative analysis.)
For each option, the contents of each cell are what we will call a column resolution, or simply a resolution. This term is new, but we chose it because several terms have been adopted to refer to similar concepts in various contexts (Wakker, 2010 appendix D), and we sought a new term to embrace all concepts. Roughly, it is the consequence/outcome of receiving or experiencing the option, given the column. In multiattribute choice, the column denotes a class of attributes, features, dimensions, or commodities and the column resolution is a qualitative or quantitative level of that column. For instance, in a choice set of cars, the columns could denote paint colour, fuel efficiency, and so on. The column resolutions would contain specific instantiations of the corresponding attributes, such as “Red” or “40 miles per gallon” (depending on the column).
In the case of intertemporal choice, the column resolutions are the outcomes occurring at that moment in time for each option in the choice set. As time is continuous, any table (and, typically in experiments, any option description) specifies only moments when something happens for at least one option. For instance, consider the choice between $100 now and $0 in one year, or $0 now and $150 in one year. A table representation for this choice typically specifies two columns, corresponding to now and one year from now, but does not explicitly represent what happens at every moment in between and beyond these points in time.
The columns in risky choices are often described as events or states of the world (e.g., raining tomorrow versus not raining tomorrow), or as event probabilities with the nature of the events unspecified but column headings adding up to 1, such as 25%, 30%, 45%. The option “if it is sunny tomorrow, we go to the seaside” is of the first type: the column is “sunny tomorrow”, the resolution is “go to the seaside”. An alternative presentation is “you have a 25% chance of going to the seaside” in which the column is “a 25% chance”. Note that in some risky choice experiments, options are described just in terms of the probabilities of different resolutions that may or may not be independent of one another. For example, decision makers could be asked to choose between a 20% chance of $40 and nothing otherwise, or a 50% chance of $15 and nothing otherwise. but may not be told how these sums of money are positioned in various states of the world. In this case the same set of options could be represented in different ways in table form, depending on different assumptions about gamble independence. Although some models regard all such representations as equivalent, there are other models where the differences in how the resolutions across events or states of the world are juxtaposed would allow for different patterns of choice. One strength of using a framework based on a table format is that it helps us to identify when such considerations do or do not matter for the implications of a model.
Behavioural models of multiattribute choice, intertemporal choice and risky choice are often contrasted against a baseline model with a functional form corresponding to a weighted sum. Each resolution xi has a subjective value v(xi); these values are assigned a decision weight wi based on what the column is; and the overall value of option X is given as: V(X) = Σwiv(xi). For a given choice set, the option with the highest weighted subjective value is assumed to be chosen.
In risky choice, the baseline model is expected utility theory, where weights are state probabilities and values of resolutions are represented by utility indices (Von Neumann & Morgenstern, 1944). In intertemporal choice, the baseline model is discounted utility (Samuelson, 1937), according to which the present value of dated consumption utility decreases exponentially with its delay. In the baseline model of multiattribute choice, the weights capture the subjective importance of the attributes and values of resolutions depend on attribute-specific utility functions (Keeney & Raiffa, 1993). These models are sometimes considered to be normative because their functional forms can be derived from consistency axioms that appeal to assumed principles of rationality. However, the normative status of baseline models (and indeed many other axiomatically-based models) is controversial, since most axioms have been challenged not only on empirical, but also on normative grounds.
As predictors of choice, the baseline models have turned out to be inadequate: almost from the moment they were first formulated, empirical patterns of behavior contradicted them. These failures stimulated the development of descriptive models, usually by modifying the baseline model through the addition of assumptions about the computations involved in transforming and aggregating columns and their resolutions. The rate at which these models were developed received a huge boost with the publication of (original) prospect theory (Kahneman & Tversky, 1979). This watershed event led to alternative models of choice, not limited to risky choice, being produced on an almost industrial scale. Starmer (2000) described how there was a “hunt for a descriptive theory of choice under risk” during the last two decades of the 20th century. He discussed more than twenty models drawn primarily from economics (to which he might have added another twenty, primarily from psychology). Even in 2000 it might have seemed strange that a relatively small number of choice patterns involving a few simple options could support the production of so many differentiated models. But far from running out of steam, the theory production process has continued unabated. We suggest four reasons for this (recognising that there may be others).
First, the same choice patterns can be interpreted and explained by a variety of functional forms and/or diverse psychological insights. Second, the pursuit of model parsimony can restrict the permissible degrees of freedom so much that while each model can account for some behavioral phenomena, none can account for all. Third, researchers often focus on one or a few choice phenomena, and even small changes in what the researcher wants to explain can lead to different models. Finally, and perhaps most importantly, because rewards in science are heavily weighted toward developing new models and demonstrating their accuracy, the development of these models (rather than testing existing models or consolidating “old” ones) has been the priority of most researchers.
So instead of an increasingly streamlined and consolidated and integrated set of choice models, we are now faced with a patchwork of competing models offering seemingly novel assumptions and generating a variety of nuanced behavioral predictions. In all three domains of choice – risky, intertemporal and multiattribute – behavior has not been captured by a small number of agreed core principles.
This problem already existed half a century ago. The pioneering mathematical psychologists Krantz, Atkinson, Luce and Suppes (1974) excluded preferential choice research from their seminal survey of mathematical psychology arguing that while “there is no lack of technically excellent papers in this area … they give no sense of any real accumulation of knowledge.” They then asked a question that has still not been answered: “what are the established laws of preferential choice behavior?” (pg. 7). In this paper we hope to make some progress towards establishing, if not the laws themselves, a framework for such laws.
One consequence of the abundance of decision models relating to a restricted domain is that models overlap. Researchers draw on highly similar mechanisms to achieve highly similar empirical predictions, often independently and often without drawing links between the models. As an example, consider the following models which treat desirability differences between pairs of options as being (at least over some range) convex in the differences between resolutions within the same Table 1 column: regret theory (Loomes & Sugden, 1982), salience theory (Bordalo et al., 2012), the importance sampling model (Lieder et al., 2017), the similarity contrast model (Mellers & Biagini, 1994), random regret minimization (Chorus et al., 2008), the similarity overlap model (Restle, 1961), the feature matching model (Houston et al., 1989), the focusing model (Kőszegi & Szeidl, 2013), the tradeoff model (Scholten & Read, 2010), the lexicographic semiorder model (Tversky, 1969), and the generalized similarity model (Leland, 1994, 2002; Rubinstein, 1988, 2003). The first three models focus on risky choice, the next four on multiattribute choice, the next three on intertemporal choice, and the last two have been applied to all three domains. The risky choice models give disproportionate importance to larger differences between resolutions (typically payoffs) in the same state of the world; the intertemporal choice models give greatest importance to the largest within-time-period differences in resolutions (again, typically payoffs); and the multiattribute models give the greatest importance to the attribute categories on which resolutions (typically attribute levels) differ most.
These models are not identical in their mathematical representation, and they may appeal to different psychological mechanisms to justify the key idea, including emotions, perceptual discrimination, and attention. However, despite any differing psychological justifications, all the models share a central insight about choice behavior. The fact that so many researchers have independently proposed models that give disproportionate importance to larger differences between column resolutions suggests that this idea might capture if not a law, then at least a property of preferential choice behavior.
Due to the large number of existing models, as well as the cross-disciplinary nature of decision research and because models may diverge in their psychological interpretation while having similar underlying mathematical assumptions (and consequently behavioral predictions), many instances of overlap are not immediately obvious. This restricts the opportunity for researchers to build on each other’s insights, and scientific energy is likely to be dispersed in repeatedly rediscovering the same set of core theoretical insights (see He et al., in press, a, for a complementary computational investigation of model overlap).
We offer a stylised and high-level map of the world of decision modeling. This map characterizes the basic mathematical and computational properties from which models are formed and suggests a metatheoretical structure whose dimensions represent the main avenues of theoretical insights and developments in decision making research. These dimensions are currently our best approximations to the laws of preferential choice behavior requested by Krantz et al. (1974).
We built this map by observing similarities across a wide set of existing models of risky, intertemporal, and multiattribute choice. Our list of models spans seven decades of theoretical research, and includes models from a wide array of fields, including psychology, cognitive science, economics, management, marketing, and neuroscience. We compiled this list using a multistage process. We began by searching Google Scholar for published models with search queries “risky choice model”, “risky decision model”, “intertemporal choice model”, “intertemporal decision model”, “multiattribute choice model”, and “multiattribute decision model”. To this list we added models discussed in regular review papers published in outlets such as the Annual Review of Psychology and the Journal of Economic Literature (Becker & McClintock, 1967; Edwards, 1954, 1961; Einhorn & Hogarth, 1981; Frederick et al., 2002; Hastie, 2001; Oppenheimer & Kelso, 2015; Payne et al., 1992; Pitz & Sachs, 1984; Rapoport & Wallsten, 1972; Simonson et al., 2001; Slovic et al., 1977; Starmer, 2000; Weber & Johnson, 2009). We then used citation chaining to obtain all papers citing our models or cited by our models, and from these papers, extracted additional models that were not present in our initial list. Finally, we circulated our list of models to the mailing list of the Society for Judgment and Decision Making, and with feedback from our colleagues, were able to add some additional model to this list. Note that our approach is likely to exclude very recent models, which is why we manually searched prominent psychology, economics, management, marketing, and neuroscience journals, for decision models published from 2015 until 2018.
Bearing in mind the breadth of the domains we consider, and the abundance of proposed models, we made our theoretical synthesis manageable by focusing on formally specified mathematical and computational models of multiattribute, risky, and intertemporal preference that have specific functional representations. We only considered models designed to describe choices (and other expressions of ordered preference) given choice sets that can be expressed in a version of Table 1, and whose parameters can be “fit” using choice data. These include behavioral utility-based models such as prospect theory, axiomatically derived models which nonetheless have, or are commonly given, clear functional representations, such as expected utility theory, and cognitive models which depict choices as the product of processes other than utility maximization, such as heuristic models and accumulator models.
We did not include qualitative theories which do not make explicit the mathematical structure of the computations they believe are at play in the decision process. We also excluded very general axiomatic theories (e.g., Machina, 1982) which do not place functional restrictions on the computations they propose. Another important omission involves stochastic choice models that merely specify how noise influences choice, without restricting the utility function that is perturbed by that noise. These include strong utility models (Fechner, 1860/1912; Luce, 1959; Thurstone, 1927), random preference models (Becker et al., 1963), as well as other variations of this approach (see Baltas & Doyle, 2001; Bhatia & Loomes, 2017; Hutchinson, 1986; Wilcox, 2008 for reviews).
We also excluded models whose main goal is to characterize the learning processes involved in choice (e.g., Rieskamp & Otto, 2006), models of experience-based (rather than description-based) choice (e.g., Gilboa & Schmeidler, 1995; Hertwig & Erev, 2009), models that attempt to describe the influence of anchors, reference points, frames, response modes, or other salient contextual features of the choice task (e.g., Goldstein & Einhorn, 1987; Tversky & Kahneman, 1991), models pertaining to choice deferral, choice confidence or related choice variables (e.g., Bhatia & Mullett, 2016; Pleskac & Busemeyer, 2010), as well as models of social and strategic decision making (e.g., Camerer, 2003; Fehr & Schmidt, 1999), risk perception (e.g., Slovic, 1987), and ambiguity-based choice (e.g., Gilboa & Marinacci, 2016; Trautmann & van de Kuilen, 2015). These models often use the computations discussed in this paper. However, they also feature additional assumptions due to the more complex nature of the behavior they describe. We also excluded models of social judgment, perceptual judgment, categorization, reasoning, and memory (see Holyoak & Morrison, 2012), and applications of decision models such as multi-criteria decision analysis and conjoint analysis (see Green & Srinivasan, 1978; Triantaphyllou, 2013). Models in these and related domains can be extended to describe multiattribute choice, but need to be excluded for tractability and manageability.
Despite these restrictions, our synthesis involves over 150 different mathematical and computational models of risky, intertemporal, and multiattribute decision making, and is based on the largest and most comprehensive list of decision models in existence. Please see the appendix for the full list of models discussed in this paper.
We limit our analysis to properties thought to be at play when evaluating the canonical options that can be described using Table 1. Recall that baseline models such as expected utility theory, the weighted additive model, and the discounted utility model, define the total value of an option in terms of the sum of independent values assigned to each resolution, weighted by some function of the column, summed over all columns. Alternative decision models have been constructed by permitting more complex interactions, transformations, and operations involving the rows and columns of Table 1. We divide these computations into three categories of properties.
The first category relates to the types of interactions between the components of choice options that are permitted by the models. Baseline models entail (a) independence of irrelevant alternatives (IIA), and (b) independence of outcomes (or separability). In this paper, IIA is an axiom of revealed preference, entailing that the value placed on an option is not influenced by the other options available. Under common assumptions, it is equivalent to transitivity. Otherwise, adding unchosen options to a choice set could potentially change which option is chosen (see Rieskamp et al., 2006 for a detailed overview). This condition should not be confused with Arrow’s (1951) social choice condition which has the same name but is formally different. The independence – also referred to as the separability – of outcomes implies, under common assumptions, that the value of an option is a weighted sum of independent values placed on each resolution of that option. Many alternative models drop one or both assumptions. Some allow for the resolutions of one option to influence the transformation and aggregation of other resolutions within the same option, hence potentially violating independence of outcomes (within-option interaction). Others allow for the resolutions of one option to influence how resolutions of other options are treated, potentially violating independence of irrelevant alternatives (between-option interaction).
The second category pertains to the types of transformations: that is, whether the models modify how resolutions are transformed, or whether they modify how the columns (probabilities, time delays, and attribute categories) are transformed and weighted.
The third and final category considers the operations used to implement the various interactions and transformations: that is, whether models involve computations of ranks, or similarities, or gains and losses, or transformations based on the statistical distributions (e.g., average, variance, or range) of resolutions or columns.
Table 2: An overview of the properties proposed as part of this synthesis.
- Within-option interactions: Components of a choice option influence how other components of the same option are evaluated
- Between-option interactions: Components of a choice option influence how components of other options are evaluated
- Value transformations: Column resolutions (such as payoffs and attribute amounts) are modified
- Weight transformations: Probabilities, delays, and attribute weights are modified
- Ordinality: Rankings of resolutions or column weights play a role in determining choice
- Gains and losses: Positive and negative quantities are evaluated differently
- Similarity and dissimilarity: Choices involve processing of resolution and weight differences within or across options
- Statistical distributions: The mean, variance, range and other distributional characteristics of the options influence choice
These three categories of model properties play a fundamental role in characterizing choice models. Models classified in the same way in all three categories will often have similar theoretical underpinnings and entail similar behaviors. We consider a total of eight different properties across these three categories, as summarised in Table 2. As we shall see, there is substantial overlap among models in the use of (subsets of) these properties, suggesting that they capture important recurring insights into the nature of preferential choice.
We first consider interactions between the components of a single choice option. The interaction can be between columns (and therefore between the weights assigned to each resolution) or between the resolutions themselves. These interactions lead to violations of independence of outcomes conditions or axioms which entail that an option can be treated as the sum of the independent utilities of each resolution, weighted by an independent function of its column attributes (see the discussion in Fishburn & Wakker, 1995). The best-known independence of outcomes condition is the sure-thing principle (Savage, 1972), which holds that preferences over gambles should not depend on common components: that is, a shared resolution within the same column. For instance, in Table 1, imagine that gambles X and Y yield the same resolution for the third event: that is, x3 = y3. The condition states that preferences between these gambles will be unaffected by this shared value, so that replacing x3 = y3 with some other identical resolution x3´ = y3´ will not alter the decision maker’s relative ranking of X and Y.
The same condition in multiattribute choice states that preferences over options do not depend on shared attributes (Keeney & Raiffa, 1993). It is called separability in consumer theory. Similarly, in intertemporal choice, independence implies that if a common dated outcome is added to two options, preferences between those options will be unaltered (Read & Scholten, 2012). In intertemporal choice, independence axioms imply additive separability, meaning that the present value of consumption at a given point does not depend on what is before or after that point (e.g., Koopmans, 1960; see discussion in Loewenstein & Prelec, 1993).
In contrast to the predictions of independence axioms, many decision models assume within-option interactions, often that the column weight depends in some way on the resolutions within that column. The best known such model is cumulative prospect theory (Tversky & Kahneman, 1992), which is equivalent to Luce and Fishburn’s (1991) rank and sign-dependent model, and which holds that probability weighting depends on the within-option rank of the resolutions corresponding to each probability for each option. For example, in Table 1 the weight placed on column 3 for gamble X may be influenced by how x3 ranks relative to x1 and x2. Models exploring and elaborating this idea with varying assumptions regarding how probabilities are transformed (Gonzalez & Wu, 1999; Lattimore et al., 1992; Prelec, 1998) also share this property, as do third generation prospect theory (Schmidt et al., 2008), anticipated utility (Quiggin, 1982), dual theory (Yaari, 1987), the security-potential/aspiration model (Lopes, 1987) and the gains decomposition utility model (Marley & Luce, 2001). Within-option interaction is also a core property of the rank-affected multiplicative weights and transfer of exchange models (Birnbaum & Chavez, 1997; Birnbaum, 2008), venture theory (Hogarth & Einhorn, 1990), the skew-symmetric bilinear theory and the weighted utility theory (Chew, 1983; Fishburn, 1982).
Variance-based models, including risk-value models (Dyer & Jia, 1997; Markowitz, 1959), the coefficient-of-variance model (Weber et al., 2004), and variance-skewness models (Coombs & Pruitt, 1960; Hagen, 1979), also incorporate within-option interactions. In these models, value is partly determined by the overall dispersion of the resolutions (usually monetary payoffs) within a gamble. This generates interactions within the gamble payoffs and consequent violations of independence.
Disappointment-based models of risk are those in which each resolution in a risky option is compared to some function of the other resolutions for the same option. There is a risk of disappointment if the realized resolution is worse than those that might have happened but did not. In many disappointment-based models (Bell, 1985; Jia et al., 2001; Loomes & Sugden, 1986; Mellers et al., 1999), the utility of any single payoff is evaluated relative to the overall expected value or expected utility of the gamble. Other disappointment-based models compare individual payoffs with the certainty equivalent of the gamble (Gul, 1991), with the best possible payoff (Grant & Kajii, 1998), or even with every other payoff (Delquié & Cillo, 2006). A class of reference-dependent models, in which gambles serve as their own reference points, also utilizes disappointment-like calculations to generate within-option interactions (Kőszegi & Rabin, 2007).
Within-option interactions also enter indirectly into models of risky choice that assume that individual outcome probabilities (the columns) are compared to what would happen if those probabilities were uniformly distributed over all columns, so that the weight assigned to a given probability depends on the number of states of the world. These models include prospective reference theory (Viscusi, 1989), the dual-system model of risk (Mukherjee, 2010), the dual-system model of affect and deliberation (Loewenstein et al., 2015), the noisy retrieval model (Marchiori et al., 2015) and distracted decision field theory (Bhatia, 2014). Aspiration-level models (Diecidue & Van de Ven, 2008) which add further calculations based on the total probability of surpassing target payoffs also indirectly permit within-option interactions. Original prospect theory (Kahneman & Tversky, 1979) incorporates within-option interactions through its assumption that probabilities associated with identical payoffs in the same gamble may be combined during editing (before being assigned a decision weight).
Finally, within-option interactions appear in heuristic models of risky choice, such as Payne and Braunstein’s (1971) information processing model, the priority heuristic (Brandstätter et al., 2006), several of Thorngate’s (1980) heuristics and the BEAST model (Erev et al., 2017). These models often involve the identification of the largest or smallest resolution in a gamble or the most likely or least likely resolutions in a gamble, so that changing one probability or resolution can affect how other probabilities and resolutions in the same gamble are evaluated.
In contrast to risky choice, the modeling of specific within-option interactions is relatively rare in multiattribute choice models. This may seem remarkable because this is a domain in which within-option interactions are ubiquitous (for example, in the form of attribute complementarity or substitutability), and much work has been done in decision analysis to develop ways of measuring utility over multiattribute bundles, and to analyse the effects of known patterns of interdependence (e.g., Keeney & Raiffa, 1993). One reason for not modeling these interactions is no doubt because it is difficult to create descriptive behavioral models with interactions between resolutions that take the form of often incommensurable attributes (e.g., a car with the resolution of red chassis in one column, and 40 miles per gallon in another). When interactions are modelled, it is assumed that attributes can be mapped onto comparable scales, such as scores on different aspects of the same test, or present/absent ratings. Interdependencies based on these conditions feature in configural weight models, which can allow for multiplicative (Birnbaum, 1974), rank-based (Birnbaum & Zimmermann, 1998), or range-based (Birnbaum & Stegner, 1979) interactions between resolutions. As with the above risky choice models, these models can violate independence of outcomes. Ganzach’s (1995) attribute scatter model assumes that people prefer a high degree of scatter within an option rather than options with the same mean but less scatter – which might mean a slow but very reliable car is preferred to one that is a bit faster and a bit less reliable. Within-option interactions are also central to neural network models such as the parallel constraint satisfaction model of heuristic choice (Glöckner & Betsch, 2008) and the Co3/ECHO model (Holyoak & Simon, 1999) which allow for attributes to influence the activation of other attributes. Lastly, conjunctive and disjunctive heuristics, which assume that decision makers focus on the best or worst resolutions within a choice option (Dawes, 1964), can display these interactions, as can approximations of these heuristics that represent the decision process with a non-linear utility function (Einhorn, 1970).
Just as in multiattribute choice, relatively few intertemporal choice models accommodate within-option interactions between resolutions even though intertemporal preferences seem highly likely to display interactions. One related line of modelling involves habit formation, found in the model of rational addiction (Becker & Murphy, 1988), the discounted utility model under habit formation Wathieu (1997), the satiation model (Baucells & Sarin, 2007), and the satiation and habit formation model (Baucells & Sarin, 2010). A classic claim is that improving sequences are valued over worsening ones, as if the more proximate experience of plenty will be worsened by the anticipated experience of subsequent poverty (e.g., Loewenstein & Sicherman, 1991). For monetary choices, preferences over resolution sequences also display dominance violations, analogous to those observed when applying (say) original prospect theory to gambles having more than two possible resolutions with the same sign (see Scholten et al., 2016). Additional models that predict interactions between resolutions include the conditional utility independence model (Bell, 1977), the preferences over sequence model (Loewenstein & Prelec, 1993), the mental accounting model of savings and debt (Prelec & Loewenstein, 1998), the monotone model (Blavatskyy, 2016), the extended tradeoff model (Read & Scholten, 2012) and the extended tradeoff model with cumulative weighting of time (Scholten et al., 2016). It should be emphasized, however, that much empirical research into intertemporal choice has circumvented the issue of intertemporal separability by focusing on choices where within-option interactions cannot occur: that is, choices involving a single smaller-sooner and larger-later option, with only one column per option associated with a non-zero resolution.
The preceding section considered models that allow for interactions between the resolutions and columns of a single option. If these are the only interactions, then a given option still has its ‘own’ subjective value to a decision maker, irrespective of whatever alternative options are available. Consequently, preferences between X and Y in Table 1 will not be affected by the presence or absence of any other option Z. Nor will the decision maker display any cyclical or intransitive pattern of choice (such as a preference for X over Y, Y over Z, and Z over X).
By contrast, allowing for the components of an option to interact with components of other options generates violations of independence of irrelevant alternatives, specified earlier as the principle whereby the preference between any two options should be independent of any other options available in the choice set (see e.g., Keeney & Raiffa, 1993). This is tantamount to saying that each and every option has its ‘own’ subjective value to an individual, entailing transitivity.
Allowing between-option interactions means that the column weight(s) assigned to the resolution(s) of a single option, or the value assigned to those resolutions, can be influenced by the weights or resolutions of other options, either in the same or different columns. Consequently, adding or removing otherwise irrelevant options from a choice set can lead to reversals of preference orderings between the existing options. When the choice set expands to more than three options, modelling the impact of the interactions may become very complex.
The great majority of decision models that assume interdependence between options limit this interdependence to that between resolutions for different options within the same column. Using the notation from Table 1, these models allow interactions between xi and yi but not between xi and yj for i ≠ j. Multiattribute models that assume between-option interactions include many lexicographic and lexicographic semiorder heuristic models (e.g., Fishburn, 1974; Tversky, 1969), heuristic models that involve comparing good and bad attribute resolutions with weights (Huber, 1979) and without weights (Russo & Dosher, 1983), the options as information model (Sher & McKenzie, 2014), the rank-weighted leaky accumulator (Tsetsos et al., 2012), the subjective dominance model (Ariely & Wallsten, 1995), the random dominance model (Hogarth & Karelaia, 2005), and a wide range of heuristic models considered by Marewski and Mehlhorn (2011). In all these models, choice is influenced by ordinal rankings of the options on different attributes, which leads to interactions between the resolutions of different choice options. Thus, for example, the desirability of a car with a given level of fuel efficiency may depend crucially on whether that level of fuel efficiency is the highest out of all the cars in the choice set.
Between-option interactions are also present in multiattribute choice models that emphasize the role of option similarity, such as the similarity overlap model (Restle, 1961), the feature matching model (Houston et al., 1989), the focusing model (Kőszegi & Szeidl, 2013), the similarity contrast model (Mellers & Biagini, 1994), the comparison grouping model (Guo & Holyoak, 2002), multiattribute salience theory (Bordalo et al., 2013), the sparse-max model (Gabaix, 2014), the multi-alternative linear ballistic accumulator (Trueblood et al., 2014), the stochastic difference model (González-Vallejo, 2002), the random-regret minimization model (Chorus et al., 2008), the contextual utility model (Rooderkerk et al., 2011), the comparative judgment model (Bhargava et al., 2000), the contextual concavity model (Kivetz et al., 2004), and various models that incorporate the additive difference rule (Tversky, 1969). All these models predict that adding or removing options from the choice set alters the perceived similarities of the remaining options, which, in turn, may alter the choice between them.
We can also observe between-option interactions in multiattribute models based on loss aversion, such as the componential context model (Tversky & Simonson, 1993), the contextual loss aversion model (Kivetz et al., 2004), the loss aversion-based leaky competitive accumulator (Usher & McClelland, 2004), and the conflict-mediated choice model (Scholten, 2002). All these models assume that choice options are treated as gains and losses relative to some other options in the choice set. Additionally, multiattribute models that utilize the distribution of resolutions observed on a single attribute (e.g., the range of values for that attribute in the choice set) to normalize the utilities of different options, display these types of interactions. These models include range-frequency theory (Parducci, 1974; Wedell & Pettibone, 1996), the neurocomputational range-normalization model (Soltani et al., 2012), the Bayesian model of fair market value (Shenoy & Yu, 2013), the Bayesian model of context sensitive value (Rigoli et al., 2017), and the similarity in context model (Dhar & Glazer, 1996). In these models, the distribution of resolutions in a choice set can be changed by adding or removing choice options.
Cognitive models that assume inhibitory interactions between different options and attributes also display between-option interactions. These include multi-alternative decision field theory (Roe et al., 2001), loss aversion-based leaky competitive accumulation (Usher & McClelland, 2004), the cortical attractor network model (Wang, 2002), the hierarchical competition model (Hunt et al., 2014), the divisive normalization model (Louie et al., 2013), the 2n-ary choice tree model (Wollschläger & Diederich, 2012), the dynamic threshold neural network (Usher & Zakay, 1993), and the accumulator rules model (Bhatia, 2017). Between-option interactions can also be observed in the associative accumulation model (Bhatia, 2013), the parallel constraint satisfaction model of decision making (Glöckner & Betsch, 2008), and the Co3/ECHO model (Holyoak & Simon, 1999). These form a related class of cognitive models, in which the attribute resolutions in the choice options dynamically determine the weights associated with different attributes. As well as inhibitory effects between options, some of these models predict between-option interactions due to momentary fluctuations of attention (e.g., Bhatia, 2013; Roe et al., 2001; Usher & McClelland, 2004; also see attentional drift diffusion models – Fisher, 2017; Krajbich et al., 2010).
A closely related class of decision models based on threshold decision making also predict between-option interactions. These include elimination by aspects and the preference tree model (Tversky, 1972), the matching heuristic (Dhami & Harries, 2001), the elimination by least attractive heuristic (Montgomery & Svenson, 1976), and the satisficing heuristic (Simon, 1955). Although threshold models do not explicitly feature interactions, by allowing the resolutions of one option to influence the resolutions of another, they can produce violations of independence of irrelevant alternatives. Many behavioral stochastic choice models, such as the contextual utility model (Wilcox, 2011) and the wandering vector model (Carroll & De Soete, 1991), similarly permit between-option interactions (typically as a function of option similarity), and thus violate the stochastic axioms pertaining to independence of irrelevant alternatives.
Some risky choice models allow for between-option interactions, primarily based on computations of similarity or dissimilarity. Examples include regret theory (Bell, 1982; Fishburn, 1982; Loomes & Sugden, 1982), the expected loss ratio model (Edwards, 1956), the perceived relative argument model (Loomes, 2010), salience theory (Bordalo et al., 2012), the importance sampling model (Lieder et al., 2017), decision affect theory (Mellers et al., 1999), and the similarity models of Leland (1994) and Rubinstein (1988). These models utilize nonlinear transformations of differences between the payoffs and/or probabilities in pairs of options to compute preferences.
Heuristic models often involve between-option interactions. These include the minimax and maximax heuristics (Thorngate, 1980), the minimax regret heuristic (Thorngate, 1980), as well as the low payoff and low expected payoff elimination heuristics (Thorngate, 1980), the information processing model (Payne & Braunstein, 1971), the priority heuristic (Brandstätter et al., 2006), the consequence counting heuristic (Birnbaum, 2005), and the most probable winner heuristic (Blavatskyy, 2006). Because these heuristic models typically involve ordinal comparisons between resolutions and probabilities across different gambles, they can violate independence of irrelevant alternatives. The BEAST model (Erev et al., 2017) and the decision-by-sampling model (Stewart et al., 2006), which rely on some of these heuristics, also display such between-option interactions. The editing phase of original prospect theory (Kahneman & Tversky, 1979), during which identical probability-payoff combinations across gambles are cancelled out, also allows between-option interactions, as does a reference-dependent extension of prospect theory in which different gambles can serve as reference points for each other (Kőszegi & Rabin, 2007). Finally, the computationally rational choice model allows for ordinal comparisons across gambles, mediated by expected value calculation, to influence choice (Howes et al., 2016).
In intertemporal choice, attribute-based models have been proposed in which the differences between resolutions determine preference. This is the case with the tradeoff model (Scholten & Read, 2010) and the extended tradeoff model (Read & Scholten, 2012), the proportional difference model (Cheng & González-Vallejo, 2016), the absolute and relative differences dynamic models (Dai & Busemeyer, 2014), as well as difference and ratio similarity-based models such as those of Leland (2002 -- see also Cubitt et al.’s (2018) and Kőszegi and Szeidl’s (2013) models, which feature a related property for multiattribute intertemporal choices). Likewise, both the ITCH model (Ericson et al., 2015) and the DRIFT model (Read et al., 2013) involve between option interactions, in that preference for an option is determined by the rate of return provided by that option compared to other options on the table, as well as differences between the resolutions of different options. Additionally, the various interval discounting models (Read, 2001; Scholten & Read, 2006; Scholten et al., 2014), the ASAP model (Kable & Glimcher, 2010), and the common-aspect attention model (Green et al., 2005) propose the discount rate for any given option depends on the delays to all options.
While most models assume either between-option or within-option interactions, a small (but important) group do neither. Many of these models involve simplifications (rather than generalizations) of expected utility theory, the weighted additive model or the discounted utility model. For example, Dawes’ (1979) equal weights heuristic, as suggested by the name, aggregates a subset of attributes democratically without considering which attribute is a better predictor (unselected attributes get weights of 0). Similarly, the equiprobable heuristic in risky choice (Thorngate, 1980), and the additive model of risky decision making (Slovic & Lichtenstein, 1968), assume choices are made without attending to probabilities.
This category also includes the subjective expected utility model of risky choice (Edwards, 1955), which permits non-linear transformations of probabilities and payoffs, but does not allow for interactions between the various components of the gamble, as well as certainty equivalence theory (Handa, 1977) and the odds-based subjective weighted utility model (Karmarkar, 1978). Finally, some risk-value models such as in Fishburn (1977) compute risk using fixed exogenous target values, rather than expected values, thus avoiding within-option interactions.
Many intertemporal choice models predict no interactions between the components of the choice options while assuming non-exponential discount functions, usually a variant of declining patience. These include the hyperbolic discounting model (Mazur, 1987), the generalized hyperbolic model (Loewenstein & Prelec, 1992), the quasi-hyperbolic model (Laibson, 1997), the hyperbolic with value transformation model (Scholten et al., 2014), the fixed cost model (Benhabib et al., 2010), the additive discounting model (Killeen, 2009), the dual-systems model of affect and deliberation (Loewenstein et al., 2015), the double exponential model (McClure et al., 2004), the constant-sensitivity model (Ebert & Prelec, 2007), the proportional discounting model (Harvey, 1994), and the exponential time model (Roelofsma, 1996).
Finally, many dynamic decision models propose neither within- nor between-option interactions. These include the ordinal and continuous multiattribute counter models (Aschenbrenner et al., 1984), the descriptive multiattribute utility model (Weiss et al., 2010) and the sequential accumulation model (Lee & Cummins, 2004).
Having discussed the classification of models according to the nature of any interactions they allow, we now consider how models may be clustered according to which dimensions they transform.
Decision models often transform the resolutions of a choice option based on other resolutions of the same option, or resolutions of different options. Many of these transformations apply only to the values attached to the payoffs or attributes of the various options, that is v(xi).
Risky choice models that involve value-based transformations include models of regret (Bell, 1982; Fishburn, 1982; Loomes & Sugden, 1982) and disappointment (Bell, 1985; Delquié & Cillo, 2006; Jia et al., 2001; Loomes & Sugden, 1986; Mellers et al., 1999), in which payoffs are evaluated relative to other payoffs in the same state of the world or other payoffs in the same gamble, respectively. Decision affect theory (Mellers et al., 1999), which models both regret and disappointment, also involves value-based transformations. Likewise, value transformations are found in models that utilize the variance of a gamble to compute the gamble’s utility (Coombs & Pruitt, 1960; Dyer & Jia, 1997; Fishburn, 1977; Markowitz, 1959; Weber et al., 2004). These models penalize payoffs that diverge strongly from the mean, as do others which factor skewness into the evaluation (Hagen, 1979).
We also find value transformations in models of intertemporal choice, including the tradeoff and extended tradeoff models (Read & Scholten, 2012; Scholten & Read, 2010), the DRIFT model (Read et al., 2013), the proportional difference model (Cheng & González-Vallejo, 2016), the absolute and relative differences dynamic models (Dai & Busemeyer, 2014), and the ITCH model (Ericson et al., 2015). These particular models apply transformations to differences or ratios between resolution amounts across options. Value transformations are also a feature of sequence models of intertemporal choice (Loewenstein & Prelec, 1993), in which people have preferences for increasing, decreasing, and dispersed sequences of consumption. Relatedly, the mental accounting model of savings and debt (Prelec & Loewenstein, 1998) assumes that resolutions in certain time periods can influence the value of resolutions in other periods, which generates various implicit value-based transformations (see also Baucells & Sarin, 2007, 2010).
Multiattribute models that feature value transformations include the componential context model (Tversky & Simonson, 1993), the loss-averse leaky competitive accumulator model (Usher & McClelland, 2004), and the contextual loss aversion model (Kivetz et al., 2004). Here the attribute resolutions for one option are evaluated based on whether they are gains or losses relative to the (same column) resolutions for other options. Many other multiattribute models also involve transformations of attributes based on pairwise comparisons with other attributes in the choice set. These include the additive difference rule (Tversky, 1969), the similarity contrast model (Mellers & Biagini, 1994), the random regret minimization model (Chorus et al., 2008), the contextual concavity model (Kivetz et al., 2004), the multi-alternative linear ballistic accumulator (Trueblood et al., 2014), the comparative judgment model (Bhargava et al., 2000), the stochastic difference model (González-Vallejo, 2002), the nonlinear model (Einhorn, 1970), the options as information model (Sher & McKenzie, 2014), and the decision by sampling model (Stewart et al., 2006). Range-based multiattribute models include the range-frequency theory (Parducci, 1974; Wedell & Pettibone, 1996), the neurocomputational range-normalization model (Soltani et al., 2012), and the similarity in context model (Dhar & Glazer, 1996). Variation-based models such as the attribute scatter model (Ganzach, 1995), also often apply transformations to value rather than decision weights.
It is possible for payoffs and attributes to be transformed, such as through a utility function, even if this transformation does not involve any within or between-option interaction. For example, expected utility theory imposes a (typically concave) transformation on monetary payoffs, whereas prospect theory assumes that this transformation is concave in the gain domain, convex in the loss domain, and that the disutility from losses is greater than the utility from equivalent gains. Other utility functions include those of Friedman and Savage (1948) and Markowitz (1952). Virtually all decision models incorporate some such basic transformations. For expositional simplicity we do not provide a complete list of these models.
Decision models that assume weight-based transformations modify the weights put on each column based on the other columns of the same option, or the resolutions of other options. Thus, the weight put on a single payoff or attribute – that is, wi – can be transformed based both on the weights on other payoffs and attributes, wj, and the specific payoffs and attribute levels, xi.
Risky choice models that involve weight-based transformations incorporate the many variants of cumulative prospect theory (Gonzalez & Wu, 1999; Lattimore et al., 1992; Prelec, 1998; Tversky & Kahneman, 1992; Wakker & Tversky, 1993) and the rank and sign-dependent utility model (Luce & Fishburn, 1991), third generation prospect theory (Schmidt et al., 2008), the gains decomposition utility model (Marley & Luce, 2001), dual theory (Yaari, 1987), the security-potential/aspiration model (Lopes, 1987), and rank-dependent probability weighting theory (Quiggin, 1982). Probability weighting in these models often depends on the rank of the payoff that they correspond to, compared to the other payoffs in the same gamble. Many such weight transformations do not involve only the probability itself, but rather differences in weighted cumulative probabilities.
Other risky choice models with weight-based transformations are salience theory (Bordalo et al., 2012) and the importance sampling model (Lieder et al., 2017), in which probability weights depend on the differences between the resolutions in the corresponding state of the world. Likewise, models such as weighted utility theory (Chew, 1983), the rank-affected multiplicative weights and transfer of exchange models (Birnbaum, 1997, 2008), and venture theory (Hogarth & Einhorn, 1990) transform probability weights, based on the structure of payoffs and probabilities in the gamble in consideration.
Finally, as with value-based transformations, some models of risky choice transform the weights on a payoff independently of the payoffs of the choice options. Prominent examples include the subjective expected utility model (Edwards, 1955), and various derivatives such as the odds-based subjective weighted utility model (Karmarkar, 1978), original prospect theory applied to more than two outcomes (Kahneman & Tversky, 1979), and certainty equivalence theory (Handa, 1977). Models such as prospective reference theory (Viscusi, 1989), the dual-systems model of risk (Mukherjee, 2010), the dual-systems model of affect and deliberation (Loewenstein et al., 2015), the noisy retrieval model (Marchiori et al., 2015) and distracted decision field theory (Bhatia, 2014), which modify probabilities by combining them with a uniform distribution, can also be seen as applying a probability-based transformation.
Many multiattribute choice models also feature weight transformations. For example, the associative accumulation model weighs attributes based on the presence or absence of these attributes in other choice options (Bhatia, 2013). This is also a feature of recurrent neural network models of multiattribute choice, in which this type of relationship is dynamic, and depends on the preferences for the options in consideration (Glöckner & Betsch, 2008; Holyoak & Simon, 1999). Other models of multiattribute choice that involve weight transformations include the feature matching model (Houston et al., 1989), the sparse-max model (Gabaix, 2014). and multiattribute salience theory (Bordalo et al., 2013), which assume that attributes that involve large differences are more salient and subsequently given higher weights. Finally, configural weight theories with multiplicative (Birnbaum, 1974), rank-based (Birnbaum & Zimmermann, 1998), or range-based interactions (Birnbaum & Stegner, 1979) across attributes apply these interactions to attribute weights.
Intertemporal choice theories that utilize weight-based transformations include models which compare time delays of the options with each other, such as the tradeoff and extended tradeoff models (Read & Scholten, 2012; Scholten & Read, 2010), the proportional difference model (Cheng & González-Vallejo, 2016), the ITCH model (Ericson et al., 2015), the focusing model (Kőszegi & Szeidl, 2013), the interval discounting model (Read, 2001), the weighted multiattribute intertemporal choice model (Cubitt et al., 2018), the ASAP model (Kable & Glimcher, 2010), and the common-aspect attention model (Green et al., 2005). These models all transform delay weights based on the other delays (or columns) in the choice set. Many other intertemporal choice models also apply weight transformations in the form of time discounting without assuming any type of within or between-option interactions. To maintain our focus we do not discuss these theories in this section.
There are also some models that do not involve any value or weight transformations. These are usually highly simplified baseline models, such as the net present value model of intertemporal choice for money, and the expected value model of risky choice. Certain multiattribute and risky choice heuristics also involve the simple aggregation of resolutions, without transforming weights or values (such as payoffs or attribute levels) (Dawes, 1979; Thorngate, 1980). Note that many other heuristics do involve transformations of the available choice options, but these transformations cannot be easily categorized as involving values and weights. These heuristics do often cause certain payoffs or attribute levels to play a disproportionately more important role in the choice but whether this importance stems from increased value or an increased weight depends on subjective interpretations of the algorithms implemented by the models.
Now we will examine four specific types of operations that decision modellers have utilized to perform these interactions and transformations. Although different models may instantiate each operation in different ways, these four operations capture the most general types of assumptions regarding the influence of attribute levels, payoffs, importance weights, time delays, or probabilities, on the choice process. Each type of operation can apply to within- and between-option comparisons, and to value and weight-based transformations, and there is considerable overlap between risky, multiattribute, and intertemporal models in their use of these different operations.
Perhaps the simplest type of operation involves replacing cardinal with ordinal information. Recall that baseline models assume the weighted aggregation of cardinal utilities. Models that utilize ordinal operations instead specify choice as the product of “best” or “worst” (or more generally, ranked) comparisons between resolutions both within and between options. Rational choice models based on ordinal information have a long history in economics (e.g., Arrow, 1951; Hicks, 1939).
The lexicographic heuristic (e.g., Fishburn, 1974) is among the most studied of heuristics. It assumes that decision makers consider only a single column attribute and then select the option with the most preferred resolution in that column. Similar ordinal comparisons are also at play with weighted and non-weighted variants of the tallying heuristic that assume decision makers rank resolutions in every column and then select the option that is the best on the largest number of these attributes (Huber, 1979; Russo & Dosher, 1983). Likewise, there is the elimination by least attractive heuristic (Montgomery & Svenson, 1976) which assumes that decision makers consider columns sequentially but then successively weed out options that are the worst in each column. The dominance heuristic (Ariely & Wallsten, 1995; Hogarth & Karelaia, 2005) selects options only if they outperform at least one option in every column. The heuristics outlined by Marewski and Mehlhorn (2011) also feature ordinal comparisons, as do conjunctive and disjunctive heuristics (Dawes, 1964), which apply ordinal comparisons within the attributes of an option.
Ordinal rules are also found in risky choice. The minimax, maximax and minimax regret rules (Thorngate, 1980), for example, choose options by comparing their absolute worst or absolute best resolutions. Likewise, the information processing model (Payne & Braunstein, 1971), the BEAST model (Erev et al., 2017), and the priority heuristic (Brandstätter et al., 2006) feature a sequence of these ordinal comparisons, involving, for example, comparisons of minimum gain. The most probable winner heuristic (Blavatskyy, 2006) applies ordinal comparisions to probabilities. Thorngate (1980) outlines several other heuristic rules that draw on ordinal rather than cardinal comparisons. These include the low payoff elimination heuristic, the better than average heuristic, the most likely heuristic, the least likely heuristic, the probable heuristic, and the low expected payoff elimination heuristic.
Many non-heuristic models also rely on ordinal comparisons. For example, in multiattribute choice, the options as information model (Sher & McKenzie, 2014) uses ranks in pairwise comparisons between columns to determine the desirability of options, and the rank-based configural weight models (Birnbaum & Zimmermann, 1998) use the ranks of resolutions within an option to determine attribute weights (e.g., assigning higher or lower weights to attributes if they are the best or worst attributes of an option). Ordinal processing is also found in range-frequency models (Parducci, 1974; Wedell & Pettibone, 1996) where the rank of a resolution within a column affects how that resolution is evaluated.
In risky choice, decision by sampling (Stewart et al., 2006) determines a given resolution’s desirability based on its rank amongst all resolutions experienced previously. Likewise, expected value calculations in the computationally rational choice model allows for ordinal comparisons across gambles (Howes et al., 2016). Other similar examples include the rank-affected multiplicative weights and transfer of exchange models (Birnbaum, 1997, 2008), which rely on resolution ranks within a gamble to determine column weights. The rank-weighted leaky accumulator aggregates resolutions weighted by their ranks in the decision sample (Tsetsos et al., 2012). Aspiration-level models (Diecidue & Van de Ven, 2008) also use ordinal comparisons to evaluate the total probability of surpassing target payoffs. Finally, rank-dependent utility and related approaches, such as cumulative prospect theory, assign probability weights based on the relative rank of payoffs within a gamble (Lopes, 1987; Luce & Fishburn, 1991; Quiggin, 1982; Schmidt et al., 2008; Tversky & Kahneman, 1992; Yaari, 1987).
Intertemporal choice models have not considered the importance of ranks within columns. But some models have considered ranking between columns, on the time dimension. They assume that discounting begins when the earliest outcome is received (even if the earliest outcome is delayed). These include two subadditive discounting models (Read, 2001), the interval discounting model (Scholten & Read, 2006) and the ASAP model (Kable & Glimcher, 2010). Likewise, the proportional difference model (Cheng & González-Vallejo, 2016) uses the highest payoffs and delays to normalize payoff and delay differences.
Many models assume that negative and positive quantities are processed differently. This is a key assumption of both original and cumulative prospect theory (Kahneman & Tversky, 1979; Tversky & Kahneman, 1992), according to which decision makers evaluate resolutions as gains and losses relative to some reference point, with losses of a given size having more impact than gains of the same magnitude (an assumption known as loss aversion). The idea of loss aversion is ubiquitous. It has been applied to between-option comparisons, both in risky choice, as with the reference-dependent model (Kőszegi & Rabin, 2007) and third generation prospect theory (Schmidt et al., 2008), and in multiattribute choice, as with the riskless reference dependence model and its extensions (Bleichrodt et al., 2009; Tversky & Kahneman, 1991; Weingarten et al., 2019), the componential context model (Tversky & Simonson, 1993) and the loss-averse leaky competitive accumulation model (Usher & McClelland, 2004). In these models, decision makers perform pairwise comparisons between the resolutions of pairs of options and place a greater emphasis on the differences between negative options than between positive options. The disappointment model without expectation also features pairwise comparisons between gamble resolutions, with higher weights on negative comparisons relative to positive comparisons (Delquié & Cillo, 2006). In intertemporal choice, loss aversion is found in the tradeoff and extended tradeoff models (Scholten & Read, 2010; Read & Scholten, 2012) and in the reference-dependent intertemporal choice model (Loewenstein & Prelec, 1992).
Cumulative prospect theory also differentiates between gains and losses in terms of probability weighting. Particularly, the rank-dependent probability weighting function is applied separately for gains and for losses, so that payoffs of identical magnitude can be weighted differently based on whether they are positive or negative (Tversky & Kahneman, 1992). The same idea is found in the rank and sign-dependent utility model (Luce & Fishburn, 1991) and in third generation prospect theory (Schmidt et al., 2008).
Other models assume that the evaluations of positive vs. negative quantities differ but apply this assumption not to differences between pairs of resolutions but rather differences between one resolution and the average of all. In risky choice, for instance, disappointment theory assumes that decision makers evaluate negative deviations from expectations differently from positive ones (Bell, 1985; Jia et al., 2001; Loomes & Sugden, 1986; Mellers et al., 1999). A similar assumption underlies the contextual loss aversion model for between-option multiattribute comparisons (Kivetz et al., 2004).
Other models that permit differences between gains and losses includes the expected loss ratio model (Edwards, 1956) and the expected loss minimization model (Sheng et al., 2005) which assume that decision makers use only expected losses (that is, negative differences in resolutions) while making choices. The additive model of risky decision making (Slovic & Lichtenstein, 1968) also permits different weights for winning and losing resolutions in gambles. Dominance-based models are also in this class. These models assume that options superior to others on every column (i.e., dominant options) are evaluated differently to options inferior to others on every column (i.e., dominated options), which in turn are evaluated differently to options without any consistent dominance relationship (Ariely & Wallsten, 1995; Hogarth & Karelaia, 2005). The multi-alternative linear ballistic accumulation model, in which dominance dimensions are given higher weights than indifference dimensions, can also be seen as possessing this property (Trueblood et al., 2014).
Models that specify similarity-based operations within or between options magnify or diminish the differences between columns or resolutions based on the differences between them. To illustrate, the editing phase of original prospect theory (Kahneman & Tversky, 1979) allows differences between payoffs or probabilities to be ignored if they are very small. Similarity operations are an important feature of risky choice models that account for violations of outcome independence using between-option interactions. Regret theory (Loomes & Sugden, 1982) generalizes the minimax regret rule (Thorngate, 1980) by allowing the psychological differences between pairs of resolutions in a single state of the world to grow with objective differences in an accelerating manner. The same idea is found in salience theory (Bordalo et al., 2012) and the importance sampling model (Lieder et al., 2017), except that these models amplify differences between resolutions by assigning disproportionately larger weights to those states of the world with larger resolution differences.
An amplification of between-option differences is also a feature of numerous multiattribute choice theories. For example, the similarity contrast model (Mellers & Biagini, 1994) assumes that the weight on a given column increases with differences between options in that column. The same basic idea appears in multiattribute salience theory (Bordalo et al., 2013) the sparse-max model (Gabaix, 2014), and the random regret minimization model (Chorus et al., 2008). Likewise, the feature matching model (Houston et al., 1989) and the similarity overlap model (Restle, 1961) assume that attributes that are common across pairs of options are ignored. This leads to higher relative importance for attributes that are uniquely present in the two options. In intertemporal choice, we observe similar assumptions in the focusing model (Kőszegi & Szeidl, 2013), in which attention is determined by attribute differences within time periods, and related models (Cubitt et al., 2018).
Interestingly, some multiattribute models assume the opposite effect of similarity. Instead of increasing the weight on columns when options differ greatly, these models increase the importance of columns in which options differ least. The multiattribute linear ballistic accumulator (Trueblood et al., 2014) is one such model. This type of pattern is also often generated by the stochastic difference model (González-Vallejo, 2002), which normalizes attribute differences by the maximum attribute amount compared. Likewise, the contextual concavity model (Kivetz et al., 2004) assumes that decision makers apply a concave function to the difference between the attribute level of a given option and the minimum level on that attribute in the choice set. This leads to an emphasis on similarity rather than dissimilarity, as concave functions have a higher slope at lower values.
Similarity can also influence processing in other ways. The similarity in context model (Dhar & Glazer, 1996), for example, suggests that the similarity between pairs of options in a given column can affect how other options are evaluated within the same column. The comparison grouping model, in contrast, first examines options that are similar to each other, before considering other options in the choice space (Guo & Holyoak, 2002). Multi-alternative decision field theory also uses global measures of similarity through its assumption of similarity-based lateral inhibition in the connections between the preferences for choice options (Roe et al., 2001). Likewise, the contextual utility model assumes that options that are globally similar to others are less desirable compared to relatively unique options (Rooderkerk et al., 2011). It is also useful to note that models that sample attributes sequentially such as decision field theory and its variants (Bhatia, 2013; Busemeyer & Townsend, 1993; Roe et al., 2001; Usher & McClelland, 2004) indirectly emphasize attribute dimensions with a large dispersion in resolutions, even though attribute weighting and attention probabilities are independent of attribute similarities. Additionally, stochastic models such as the contextual utility model (Wilcox, 2011) and the wandering vector model (Carroll & De Soete, 1991) allow for similarity-based noise effects.
Finally, lexicographic semiorders, which only consider attributes on which the available options are different enough, also emphasize dissimilarity on attributes. This is the case for such models in multiattribute choice (Tversky, 1969), risky choice (Leland, 1994; Rubinstein, 1988), and variants of these models in intertemporal choice (Leland, 2002; Rubinstein, 2003). The more general additive difference model is also based on this assumption (Tversky, 1969). The PRAM model (Loomes, 2010) allows for ‘smoother’ similarity/dissimilarity effects on both the probability and the payoff dimensions.
Models often draw on distributional information about columns and resolutions, especially when these are expressed in quantitative form such as probabilities or monetary payoffs. One important class of models uses payoff averages to normalize payoff values. In disappointment based models (Bell, 1985; Jia et al., 2001; Loomes & Sugden, 1986; Mellers et al., 1999), for example, decision makers compare each gamble payoff with the expected value of the gamble, and evaluate payoffs worse than the expected value differently than payoffs better than the expected value. In multiattribute choice, the contextual loss aversion model assumes that decision makers compute the average attribute levels of the options in a choice set and, like other loss aversion models, give greater importance to negative deviations from the average compared to positive deviations within attribute columns (Kivetz et al., 2004). The Bayesian model of context sensitive value (Rigoli et al., 2017) also uses sequentially computed averages to normalize attribute values prior to aggregation.
Intertemporal choice models of sequences have used normalization (Loewenstein & Prelec, 1993). These theories compare the payoff in a time period with the average payoffs provided by the choice option. Relatedly, normalization comes into play in the ITCH model (Ericson et al., 2015) which assumes that differences between choice components (either payoffs or time delays) are divided by the average component offered in the choice set. The DRIFT model (Read et al., 2013), makes the same assumption, as does the proportional difference model (Cheng & González-Vallejo, 2016).
Many models use averages for purposes other than normalization. These assume that the average resolution for a column influences the weight assigned to that column. These operations are commonly at play in theories of multiattribute choices which assume a bidirectional relationship between the choice options available to the decision maker and the attributes. These theories include the ECHO model (Holyoak & Simon, 1999), the parallel constraint satisfaction model for decision making (Glöckner & Betsch, 2008; Glöckner et al., 2014), as well as the associative accumulation model (Bhatia, 2013). A related use of attribute averages is adopted by the contextual utility model to study the compromise effect (Rooderkerk et al., 2011). In intertemporal choice, the endogenous determination of time preference model (Becker & Mulligan, 1997) also assumes the discount rate for an option is inversely related to the average of the resolutions of that option.
Other models utilize the variance of the distribution of payoffs to judge the total value of options. Indeed, models in this class are some of the oldest in the area of risky choice (Coombs & Pruitt, 1960; Dyer & Jia, 1997; Markowitz, 1959), due in large part to the importance of outcome variance as a driver of the famous Allais paradox (Allais, 1953). These models assume that decision makers dislike gambles with high variance payoffs. Models utilizing the coefficient of variation (Weber et al., 2004) combine this idea with normalization, by dividing the standard deviation by the expected value. The use of variance is also involved in multiattribute choice theories, such as the attribute scatter model (Ganzach, 1995) which proposes people like options having more dispersed resolutions – showing a preference for variance rather than an aversion to it.
Many models hold that the perceptions, weights and evaluations of columns and resolutions can be affected by their range. Models that apply range-based operations generally assume that increasing the range of values reduces the perceived difference between any pair of values. This type of operation is perhaps best known as the range principle of range-frequency theory, which states that utilities and desirability ratings are spaced out in equal segments of the attribute range (Parducci, 1974; Wedell & Pettibone, 1996). A range-based operation is a key feature of the range-normalization model, which is inspired by the neurocomputational processes known to be at play in perception and other psychological domains (Soltani et al., 2012). The range of probabilities and payoffs within a gamble is also used in some configural weight models (Birnbaum & Stegner, 1979). Finally, a closely related type of normalization is performed by the stochastic difference model (González-Vallejo, 2002), which uses the maximum (but not the minimum) of the range of values in calculating values. Range also plays a similar role in the normalized contextual concavity model, which assumes that an attribute is evaluated by taking the ratio of its difference with the smallest level on that attribute, to the range of levels on that attribute (Kivetz et al., 2004).
The four operations identified above do not capture all of the diverse ways in which decision models transform, compare, and aggregate the various components of the choice options. There are some other operations that we haven’t considered that are specific to one of the three domains. For example, some intertemporal choice models allow decision makers to evaluate increasing vs. decreasing payoff sequences across time periods differently (e.g., Loewenstein & Prelec, 1993); such operations do not play a role in risky or multiattribute choice because they, unlike time, usually have no natural ordering of the columns. Additionally, there are types of operations that only exist within certain disciplines or modeling frameworks. For example, a large class of models in psychology involve the sequential sampling and aggregation of resolutions over time (e.g., Busemeyer & Townsend, 1993); these models are relatively uncommon in other fields (though their popularity is growing). Despite these omissions, our taxonomy is a valuable starting point for understanding the elemental computational operations involved in preferential decision making, as it identifies a core set of recurring insights and assumptions shared by models across the domains of risk, time, and multiattribute choice, and across diverse disciplines.
When Krantz et al. (1974) explained why they excluded preferential choice research from their seminal survey of mathematical psychology, they argued that while the field had many excellent papers and ideas, these neither built on one another, nor yielded cohesive theoretical insights, nor gave any sense of an accumulation of knowledge.
Five years later, Kahneman and Tversky (1979) published prospect theory. This paper had a profound multidisciplinary impact, influencing psychology, economics, marketing, management, finance, cognitive science, and neuroscience. It is usually taken as the birth of the behavioral approach in decision theory. It triggered the development of a large number competing models of preferential choice behavior, each based on a seemingly unique set of assumptions and each yielding a seemingly differentiated set of behavioral predictions. The net result is that now there may be even less of a sense of refinement and unification than when Krantz et al. commented upon it almost half a century ago.
A single unified decision theory may not be feasible but we have attempted to provide a framework for characterising models by means of a set of core properties that can be argued to be at play in preferential choice (see also He et al., in press a, for a complementary computational investigation of this problem). At an early stage in the evolution of this paper, we had thought that this approach may be able to yield something akin to a decision-theory analogue of Barlow and Morgenstern’s (1948) Dictionary of Musical Themes. That dictionary proposed a notation scheme that allowed someone, hearing a tune that is unfamiliar to them, to check for its prior existence and to locate it with respect to other tunes that are similar to it. We had initially hoped to find some system that would, by identifying core model properties, enable us to assign the equivalent of a ‘barcode’ to any model in the domains we have considered. The idea was that two models sharing the same barcode would, in effect, be identical in terms of underlying assumptions and behavioral predictions.
However, it became clear that such an approach would not take us very far. For example, it transpired that two models could appear to be quite closely aligned on many core properties (sharing much of the barcode) and yet have substantially different implications, depending on the particular way a certain property is specified (e.g., whether similarity attracts greater weight or whether similar features are ignored), and the way it is interpreted (e.g., whether it is seen to be a product of attention or emotion or a neurocognitive mechanism). So, we adopted a less digital and more qualitative approach involving more general properties, as summarised in Table 2 (also see He et al., 2021 – a, for computational approach for addressing this problem). While these properties may be less precise and more open to interpretation than a tight codification, we believe they form the blocks with which decision models of choice are most often built. Importantly, as these properties are drawn from recurring insights in decision modeling (insights shared by a large number of different models), they can be assumed to capture a theoretical consensus regarding where the “laws of preferential choice” are likely to reside.
It is useful to briefly revisit what these properties imply about choice behavior, starting with Category 1 in Table 2. “Violations” of independence axioms or assumptions, some of which entail preference reversals and intransitive choice cycles, are perhaps the most striking and most widely discussed decision biases. These include the Allais-type paradoxes, various context effects in multiattribute choice, and sequence effects in intertemporal choice. All attempts to model these phenomena do so by assuming interactions within or between the components of the choice options. The ubiquity of these choice patterns, and the difficulty of seeing how they could be produced without some kind of interactions, suggest that those laws of choice behavior we eventually settle on will include such interactions.
The laws of choice behavior are also likely to make room for transformations of both the values of the resolutions of the choice options (e.g., attributes or payoffs), and of the probabilities, weights, and time delays associated with these resolutions. These two types of transformations reflect different intuitions regarding the determinants of behavior.
Transformations of values often involve an affective component. Indeed, the values ascribed to resolutions are often assumed to reflect the pleasure or displeasure they are expected to generate, and decision models that involve transformations of these values, such as models of disappointment, regret, aspiration, and loss aversion, often emphasize this affective (or utilitarian) underpinning. For instance, if people are likely to experience regret, or disappointment, then it is arguably rational to act on those anticipations in risky choice. Or, if they will savour the prospect of positive future experiences and dread negative ones, then again, these sources of utility or disutility should rationally be taken into account when making intertemporal choices.
By contrast, many operations modifying decision weights involve a perceptual or cognitive component – underweighting and/or overweighting probabilities and redistributing attention and judgments of relative importance to different time horizons or different attributes. Arguably these may (in some cases at least) be regarded as errors since they may lead to dynamic inconsistency and to choices of options that may, on reflection, be regarded as suboptimal.
Category 3 identifies four broad types of operations frequently involved in transforming and aggregating the components of choice options. These types of operation each have something to tell us about how decision makers process the choice problem. Computations of ordinality, for example, are often seen as reflecting the use of cognitive shortcuts and most of the models that we classify as involving ordinal computations are heuristics. Even ordinality-based models that are not heuristics often rely on comparisons that ignore magnitude-based information and simplify the choice problem.
Likewise, the differential evaluation of gains and losses has been incorporated into decision theory most prominently via its role in prospect theory (Kahneman & Tversky, 1979), and many of the models we classify as involving these operations are extensions of prospect theory. There are also models in this category that are not directly related to prospect theory. However, in their use of gain- and loss-based information, these models share important computational similarities with prospect theory models and could even be seen as utilizing some of the same cognitive and affective mechanisms as prospect theory.
The use of similarity-based operations stems from the importance of differences between resolutions, the perception of these differences, and the effect of these differences on attention and emotion. Arguably, being able to identify the elements that require little or no attention and focus mental effort on those involving the greatest relative gains and losses, is a more efficient use of finite cognitive resources. This is closely related to our fourth type of operation, which involves transforming values or weights based on the statistical properties of the choice problem. The use of these statistical properties – mean, variance, skewness, range – reflects the fact that perceptions and evaluations are sensitive to the distributions of the variables in consideration. Similarity and distribution-based operations reflect fundamental psychological insights about cognition, which extend beyond decision making research, and it is common to see these types of computations in formal models of social judgment, perception, categorization, and memory.
Although the baseline model in the three domains we have considered essentially proposes no within-option interactions (other than the combination of values and weights required to produce a weighted average) and no between-option interactions (at all), we have seen that a wide variety of interactions have been proposed; and that these can be defended either on normative grounds (mostly where second-order preferences, involving regret, disappointment, aspiration, and other affective states, are involved) or on descriptive grounds (especially where particular comparisons or operations may reflect the finite cognitive resources deployed by non-specialist decision makers participating in experiments).
Once we allow that any and all of these operations may have at least some part to play in at least some choice scenarios, it becomes easy to understand why no single model provides a comprehensive account of the whole gamut of observed behavioral regularities. The value placed on conciseness and elegance in modeling, and the objective of keeping down the degrees of freedom permitted by a model in the interests of refutability, may be laudable tenets for theoretical development; but when a process is as multifaceted and organic as human decision making, some balance needs to be struck between parsimony and realism, and it may be that this balance needs to be adjusted in favour of more degrees of freedom and greater realism.
We are the first to collect and synthesize such large number of distinct decision models, and consequently we are able to provide a unique perspective on trends in decision modeling research. The easiest trend to identify involves the distribution of decision models over time, displayed in Figure 1. This figure summarizes the publication decades of the modeling papers cited in our synthesis (with each paper included only if it presents what we consider to be a model that can be distinguished from any extant model, and if it is the first publication of such a model). Of course, there is some ambiguity regarding the precise numbers in this figure. Firstly, they pertain only to the publication dates of individual papers. It some cases, papers may contain several distinctive features, whereas other papers may be largely seen as refining or extending existing models. Moreover, our synthesis has undoubtedly excluded relevant models, leading to an inadvertent but potentially systematic bias in the precise numbers involved (we expect that most of these exclusions involve older models, which are often difficult to find, but some of the excluded models may also be very recent – i.e. models that have not yet come to our attention). Despite these caveats, Figure 1 indicates there has been a heavy growth in the total number of decision models, and that the number of such models is still growing. Additionally, risky and multiattribute choice models are the earliest and the most popular models. Intertemporal choice models, in contrast, are relatively fewer and much more recent. In total there are more than 100 papers that have published novel or unique risky, multiattribute, and intertemporal decision models, according to our estimates.
Figure 1: The number of papers publishing unique decision models discussed in our synthesis, based on decade of publication.
Figure 2 presents a breakdown of papers publishing decision models by field. Here we have considered four categories, based on the primary focus of the journal the paper is published in: psychology (which includes neuroscience and cognitive science), economics (which includes decision theory and decision analysis), business (which includes management and marketing), and general (which includes books, as well as general interest journals publishing papers from multiple scientific disciplines). We again include a paper only if it presents what we consider to be a unique model, and if it is the first publication of the model. Additionally, the numbers pertain to the published papers, and some papers may have multiple models, which we do not count as separate instances. Thus, as with Figure 1, the numbers in this figure are imprecise. That said, we can note some systematic patterns in this figure. Firstly, the field with the most publications is psychology, followed by economics and business. Additionally, different fields focus on different decision domains. Although all three of the core fields have decision models for all three decision domains, economics involves a much higher proportion of risky decision models (likely due to the central role of risk in finance and economics), and a much smaller proportion of multiattribute decision models. This pattern is reversed for business (likely due to the central role of multiattribute considerations in consumer choice). Psychology also tends to have more multiattribute than risky choice papers, though the distribution is more balanced. Overall, the journal with the most published papers in our synthesis is Psychological Review which has published more than 20 papers with unique decision models over the past seven decades.
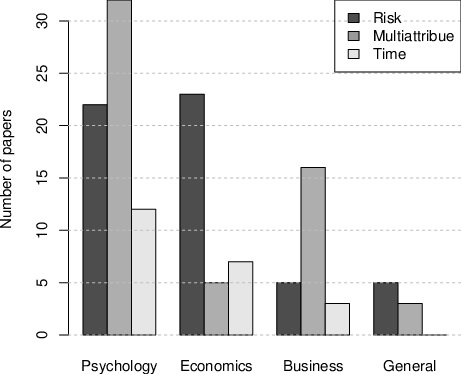
Figure 2: The number of papers publishing unique decision models discussed in our synthesis, based on field.
More interesting than the distribution of models over time, disciplines, and domains, is the distribution of properties across models. It is here that we have noticed some odd patterns. Consider, for example, the fact that models of risky choice largely satisfy between-option independence but not within-option independence, whereas the opposite is the case for models of multiattribute and intertemporal choice. However, it seems that violations of within-option independence are more reasonable in multiattribute and intertemporal tasks. Attributes quite naturally influence each other’s evaluation, and consumption in one time period strongly affects preferences over consumption in future time periods. The same is not so plausibly the case for state-contingent outcomes, in which events are disjoint — certainly von Neumann and Morgenstern’s independence axiom may appear quite compelling for risky choice, but not for its multiattribute and intertemporal counterparts. Thus, if there are differences in behaviors across the tasks, we should expect them to pertain to the increased number of violations of within-option independence in multiattribute and intertemporal tasks. Consequently, we should expect multiattribute and intertemporal models to feature more violations of within-option independence compared to their risky counterparts.
The fact that we observe precisely the opposite pattern points to a somewhat ironic aspect of decision making research. The generation of decision models has been strongly driven by counter-intuitive violations of normative rationality. Within-option dependence is a particularly counter-intuitive violation in risky choice, and thus most decision models of risky choice explicitly feature this dependence. It is not a counter-intuitive violation in multiattribute and intertemporal choice, and is therefore omitted from nearly all corresponding decision models. In trying to explain surprising paradoxes, it seems that decision models may have failed to explain the obvious.
With a large number of models already in existence, and new ones still being proposed, our classification system will enable researchers to understand better the similarities and distinctions between different models and perhaps judge more easily the added value offered by would-be entrants into this already crowded field. Additionally, by providing an easily accessible list of previous models, we hope to encourage more comprehensive model evaluations that compare new models against the full set of previous choice models proposed in a given domain. Such comparisons could be either based on quantitative model fits to choice datasets (Glöckner & Pachur, 2012; He et al., in press b), or on qualitative choice properties that are revealed in experimental tests (see e.g. Birnbaum, 2008). New models may provide a good post hoc explanation for certain findings, but in order to understand their contribution to the field, they need to be evaluated holistically, that is, in combination with all theories that have been proposed for the choice task under consideration.
We would even go so far as to recommend that we avoid building new models with narrow assumptions, and instead concentrate on understanding the general properties (such as those that we have outlined above) that have been previously proposed for preferential choice. Most of these properties are at play in all the three domains that we consider, and it is likely that any model that omits even one of these properties will fail in particular ways or contexts. For example, independence of alternatives (and in turn transitivity) is violated in various risky, multiattribute, and intertemporal decision scenarios so that any model which does not allow for between-option interactions will be descriptively incomplete in those circumstances.
Refocusing scholarly attention on the broader properties that characterize choice behavior, rather than specific functional instantiations of these properties in individual models, would involve performing experimental tests comparing not two specific models, but two sets of properties or two different instantiations of a given property. For example, it would be more reasonable to ask whether the range or variance of resolutions play a bigger role in the evaluation of options, than it would be to directly compare a specific range-based model with a specific variance-based model. On a theoretical level, research could attempt to examine how the above properties are instantiated in the mind and in the brain, or investigate the general behavioral properties implied by these properties. It would not be unreasonable to claim that models that apply the same properties also require the same cognitive and neural processes to be implemented, and additionally, help achieve similar computational and statistical goals.
Of course, we recognize that science has many goals, and that descriptive adequacy and theoretical novelty may not be the only guiding principles for decision modelers (e.g., Glöckner & Betsch, 2011; Oberauer & Lewandowsky, 2019; Roberts & Pashler, 2000; for alternative perspectives). Additionally, scholars in different disciplines may wish to continue developing and refining models that address their particular research problem. Decision theorists, for example, might want to keep exploring the representational implications of various axiomatic restrictions on choice, whereas cognitive psychologists might want to keep exploring new ways to predict attention, memory, response time and other psychological variables. The development of several new theories may also be beneficial for a completely new choice task or behavioral domain. However, it is also clear that continuing to create new models of risky, intertemporal and multiattribute choice, with a narrow set of slightly different assumptions, tweaked to predict a rather specific set of choice patterns, is inefficient and, to the extent that it adds traffic to an already crowded thoroughfare, counterproductive. After many decades of decision modeling, and particularly since the late 1970s, it is perhaps time to pause, reflect on what has been done, and think critically of the ways in which existing models can inform future research. By examining the underlying similarities between a very large group of these models, and using these similarities to uncover the key properties, or laws, of preferential choice behavior, this paper provides a set of organizing principles for such an endeavour.
Allais, M. (1953). L’extension des théories de l’équilibre économique général et du rendement social au cas du risque. Econometrica, 21(4), 269–290.
Ariely, D., & Wallsten, T. S. (1995). Seeking subjective dominance in multidimensional space: An explanation of the asymmetric dominance effect. Organizational Behavior and Human Decision Processes, 63(3), 223–232.
Arrow, K. J. (1951). Alternative approaches to the theory of choice in risk-taking situations. Econometrica, 19(4), 404–437.
Aschenbrenner, K. M., Albert, D., & Schmalhofer, F. (1984). Stochastic choice heuristics. Acta Psychologica, 56(1), 153–166.
Baltas, G., & Doyle, P. (2001). Random utility models in marketing research: a survey. Journal of Business Research, 51(2), 115–125.
Barberis, N., & Thaler, R. (2003). A survey of behavioral finance. Handbook of the Economics of Finance, 1, 1053–1128.
Barlow, H., & Morgenstern, S. (1948). A dictionary of musical themes. Crown.
Baron, J. (2008). Thinking and deciding, 4th ed. Cambridge University Press.
Baucells, M., & Sarin, R. K. (2007). Satiation in discounted utility. Operations Research, 55(1), 170–181.
Baucells, M., & Sarin, R. K. (2010). Predicting utility under satiation and habit formation. Management Science, 56(2), 286–301.
Bazerman, M. H., & Moore, D. A. (2008). Judgment in Managerial Decision Making, 7th ed. Wiley.
Becker, G. M., DeGroot, M. H., & Marschak, J. (1963). Stochastic models of choice behavior. Behavioral Science, 8(1), 41–55.
Becker, G. M., & McClintock, C. G. (1967). Value: Behavioral decision theory. Annual Review of Psychology, 18(1), 239–286.
Becker, G. S., & Mulligan, C. B. (1997). The endogenous determination of time preference. The Quarterly Journal of Economics, 112(3), 729–758.
Becker, G. S., & Murphy, K. M. (1988). A theory of rational addiction. Journal of political Economy, 96(4), 675–700.
Bell, D. E. (1977). A utility function for time streams having inter-period dependencies. Operations Research, 25(3), 448–458.
Bell, D. E. (1982). Regret in decision making under uncertainty. Operations Research,30(5), 961–981.
Bell, D. E. (1985). Disappointment in decision making under uncertainty. Operations Research, 33(1), 1–27.
Benhabib, J., Bisin, A., & Schotter, A. (2010). Present-bias, quasi-hyperbolic discounting, and fixed costs. Games and Economic Behavior, 69(2), 205–223.
Bhargava, M., Kim, J., & Srivastava, R. K. (2000). Explaining context effects on choice using a model of comparative judgment. Journal of Consumer Psychology, 9(3), 167–177.
Bhatia, S. (2013). Associations and the accumulation of preference. Psychological Review, 120(3), 522.
Bhatia, S. (2014). Sequential sampling and paradoxes of risky choice. Psychonomic Bulletin and Review, 21(5), 1095–1111.
Bhatia, S. (2017). Choice rules and accumulator networks. Decision, 4(3), 146–170.
Bhatia, S., & Loomes, G. (2017). Noisy preferences in risky choice: A cautionary note. Psychological Review, 124(5), 678–686.
Bhatia, S., & Mullett, T. L. (2016). The dynamics of deferred decision. Cognitive Psychology, 86, 112–151.
Birnbaum, M. H. (1974). The nonadditivity of personality impressions. Journal of Experimental Psychology Monograph, 102, 543–561.
Birnbaum, M. H. (1997). Violations of monotonicity in judgment and decision making. In A. A. J. Marley (Ed.), Choice, decision, and measurement: Essays in honor of R. Duncan Luce (pp. 73–100). Erlbaum.
Birnbaum, M. H. (2005). A comparison of five models that predict violations of first-order stochastic dominance in risky decision making. Journal of Risk and Uncertainty,31(3), 263–287.
Birnbaum, M. H. (2008). New paradoxes of risky decision making. Psychological Review, 115(2), 463–501.
Birnbaum, M. H., & Chavez, A. (1997). Tests of theories of decision making: Violations of branch independence and distribution independence. Organizational Behavior and Human Decision Processes,71(2), 161–194.
Birnbaum, M. H., & Stegner, S. E. (1979). Source credibility in social judgment: Bias, expertise, and the judge’s point of view. Journal of Personality and Social Psychology, 37(1), 48–74.
Birnbaum, M. H., & Zimmermann, J. M. (1998). Buying and selling prices of investments: Configural weight model of interactions predicts violations of joint independence. Organizational Behavior and Human Decision Processes, 74(2), 145–187.
Blavatskyy, P. R. (2006). Axiomatization of a preference for most probable winner. Theory and Decision, 60(1), 17–33.
Blavatskyy, P. R. (2016). A monotone model of intertemporal choice. Economic Theory, 62, 785–812.
Bleichrodt, H., Schmidt, U., & Zank, H. (2009). Additive utility in prospect theory. Management Science, 55(5), 863–873.
Bordalo, P., Gennaioli, N., & Shleifer, A. (2012). Salience theory of choice under risk. The Quarterly Journal of Economics, 127(3), 1243–1285.
Bordalo, P., Gennaioli, N., & Shleifer, A. (2013). Salience and consumer choice. Journal of Political Economy, 121(5), 803–843.
Brandstätter, E., Gigerenzer, G., & Hertwig, R. (2006). The priority heuristic: making choices without trade-offs. Psychological Review, 113(2), 409–432.
Busemeyer, J. R., & Townsend, J. T. (1993). Decision field theory: a dynamic-cognitive approach to decision making in an uncertain environment. Psychological Review, 100(3), 432–459.
Camerer, C. (2003). Behavioral game theory: Experiments in strategic interaction. Princeton University Press.
Camerer, C. F., Loewenstein, G., & Rabin, M. (2011). Advances in behavioral economics. Princeton University Press.
Carroll, J. D., & De Soete, G. (1991). Toward a new paradigm for the study of multiattribute choice behavior: Spatial and discrete modeling of pairwise preferences. American Psychologist, 46(4), 342–351.
Cheng, J., & González-Vallejo, C. (2016). Attribute-wise vs. alternative-wise mechanism in intertemporal choice: Testing the proportional difference, trade-off, and hyperbolic models. Decision, 3(3), 190–215.
Chew, S. (1983). A generalization of the quasilinear mean with applications to the measurement of income inequality and decision theory resolving the Allais paradox. Econometrica 51, 1065–1092.
Chorus, C. G., Arentze, T. A., & Timmermans, H. J. (2008). A random regret-minimization model of travel choice. Transportation Research Part B: Methodological, 42(1), 1–18.
Coombs, C. H., & Pruitt, D. G. (1960). Components of risk in decision making: Probability and variance preferences. Journal of Experimental Psychology, 60(5), 265–277.
Cubitt, R., McDonald, R., & Read, D. (2018). Time matters less when outcomes differ: Unimodal vs. cross-modal comparisons in intertemporal choice. Management Science, 64(2), 873–887.
Dai, J., & Busemeyer, J. R. (2014). A probabilistic, dynamic, and attribute-wise model of intertemporal choice. Journal of Experimental Psychology: General, 143(4), 1489.
Dawes, R. M. (1964). Social selection based on multidimensional criteria. The Journal of Abnormal and Social Psychology, 68(1), 104.
Dawes, R. M. (1979). The robust beauty of improper linear models in decision making. American Psychologist, 34(7), 571.
Delquié, P., & Cillo, A. (2006). Disappointment without prior expectation: A unifying perspective on decision under risk. Journal of Risk and Uncertainty, 33(3), 197–215.
Dhami, M. K., & Harries, C. (2001). Fast and frugal versus regression models of human judgement. Thinking & Reasoning, 7(1), 5–27.
Dhar, R., & Glazer, R. (1996). Similarity in context: Cognitive representation and violation of preference and perceptual invariance in consumer choice. Organizational Behavior and Human Decision Processes, 67(3), 280–293.
Diecidue, E., & Van de Ven, J. (2008). Aspiration level, probability of success and failure, and expected utility. International Economic Review, 49(2), 683–700
Dyer, J. S., & Jia, J. (1997). Relative risk—value models. European Journal of Operational Research, 103(1), 170–185.
Ebert, J. E., & Prelec, D. (2007). The fragility of time: Time-insensitivity and valuation of the near and far future. Management Science, 53(9), 1423–1438.
Edwards, W. (1954). The theory of decision making. Psychological Bulletin, 51(4), 380–417.
Edwards, W. (1955). The prediction of decisions among bets. Journal of Experimental Psychology, 50(3), 201–214.
Edwards, W. (1956). Reward probability, amount, and information as determiners of sequential two-alternative decisions. Journal of Experimental Psychology, 52(3), 177–188.
Edwards, W. (1961). Behavioral decision theory. Annual Review of Psychology, 12(1), 473–498.
Einhorn, H. J. (1970). The use of nonlinear, noncompensatory models in decision making. Psychological Bulletin, 73(3), 221–230.
Einhorn, H. J., & Hogarth, R. M. (1981). Behavioral decision theory: Processes of judgement and choice. Annual Review of Psychology,32(1), 53–88.
Erev, I., Ert, E., Plonsky, O., Cohen, D., & Cohen, O. (2017). From anomalies to forecasts: Toward a descriptive model of decisions under risk, under ambiguity, and from experience. Psychological Review,124(4), 369–410.
Ericson, K. M., White, J. M., Laibson, D., & Cohen, J. D. (2015). Money earlier or later? Simple heuristics explain intertemporal choices better than delay discounting does. Psychological Science, 26(6), 826–833.
Fechner, G. T. (1860/1912). Elements of psychophysics. In Rand, Benjamin (Ed.), The Classical Psychologists (pp. 562–572). Houghton Mifflin
Fehr, E., & Schmidt, K. M. (1999). A theory of fairness, competition, and cooperation. Quarterly Journal of Economics, 114(3), 817–868.
Fishburn, P. C. (1974). Lexicographic orders, utilities and decision rules: A survey. Management Science, 20(11), 1442–1471.
Fishburn, P. C. (1977). Mean-risk analysis with risk associated with below-target returns. The American Economic Review, 67(2), 116–126.
Fishburn, P. C. (1982). Nontransitive measurable utility. Journal of Mathematical Psychology, 26(1), 31–67.
Fishburn, P. C., & Wakker, P. (1995). The invention of the independence condition for preferences. Management Science, 41(7), 1130–1144.
Fisher, G. (2017). An attentional drift diffusion model over binary-attribute choice. Cognition, 168, 34–45.
Frederick, S., Loewenstein, G., & O’donoghue, T. (2002). Time discounting and time preference: A critical review. Journal of Economic Literature, 40(2), 351–401.
Friedman, M., & Savage, L. J. (1948). Utility analysis of choices involving risk. Journal of Political Economy, 56(4), 279–304
Gabaix, X. (2014). A sparsity-based model of bounded rationality. The Quarterly Journal of Economics, 129(4), 1661–1710.
Ganzach, Y. (1995). Attribute scatter and decision outcome: Judgment versus choice. Organizational Behavior and Human Decision Processes, 62(1), 113–122.
Gilboa, I., & Marinacci, M. (2016). Ambiguity and the Bayesian paradigm. In Arló-Costa H., Hendricks V., & van Benthem J. (Eds) Readings in Formal Epistemology. Springer Graduate Texts in Philosophy, Vol 1. Springer.
Gilboa, I., & Schmeidler, D. (1995). Case-based decision theory. The Quarterly Journal of Economics, 110(3), 605–639.
Glimcher, P. W., & Fehr, E. (2013). Neuroeconomics: Decision making and the brain. Academic Press.
Glöckner, A., & Betsch, T. (2008). Modeling option and strategy choices with connectionist networks: Towards an integrative model of automatic and deliberate decision making. Judgment and Decision Making, 3(3), 215–-228.
Glöckner, A., & Betsch, T. (2011). The empirical content of theories in judgment and decision making: Shortcomings and remedies. Judgment & Decision Making, 6(8), 711–721.
Glöckner, A., Hilbig, B. E., & Jekel, M. (2014). What is adaptive about adaptive decision making? A Parallel Constraint Satisfaction Account. Cognition, 133, 641–666.
Glöckner, A., & Pachur, T. (2012). Cognitive models of risky choice: Parameter stability and predictive accuracy of prospect theory. Cognition, 123(1), 21–32.
Goldstein, W. M., & Einhorn, H. J. (1987). Expression theory and the preference reversal phenomena. Psychological Review, 94(2), 236–254.
Gonzalez, R., & Wu, G. (1999). On the shape of the probability weighting function. Cognitive Psychology, 38(1), 129–166.
González-Vallejo, C. (2002). Making trade-offs: A probabilistic and context-sensitive model of choice behavior. Psychological Review, 109(1), 137–155.
Grant, S., & Kajii, A. (1998). AUSI expected utility: an anticipated utility theory of relative disappointment aversion. Journal of Economic Behavior and Organization, 37(3), 277–290.
Green, L., Myerson, J., & Macaux, E. W. (2005). Temporal discounting when the choice is between two delayed rewards. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(5), 1121–1133.
Green, P. E., & Srinivasan, V. (1978). Conjoint analysis in consumer research: issues and outlook. Journal of Consumer Research, 5(2), 103–123.
Gul, F. (1991). A theory of disappointment aversion. Econometrica: Journal of the Econometric Society, 59(3), 667–686.
Guo, F. Y., & Holyoak, K. J. (2002). Understanding similarity in choice behavior: A connectionist model. In Proceedings of the twenty-fourth annual conference of the cognitive science society (pp. 393–398).
Hagen, O. (1979). Towards a positive theory of preferences under risk. In Allais, M. and Hagen, O. (editors), Expected Utility Hypotheses and the Allais Paradox (pp. 271–302). Reidel Dordrecht.
Halpern, D. (2016). Inside the nudge unit: how small changes can make a big difference. Ebury Publishing, Penguin Random House.
Handa, J. (1977). Risk, probabilities, and a new theory of cardinal utility. The Journal of Political Economy, 85(1), 97–122.
Harvey, C. M. (1994). The reasonableness of non-constant discounting. Journal of Public Economics, 53(1), 31–51.
Hastie, R. (2001). Problems for judgment and decision making. Annual Review of Psychology, 52(1), 653–683.
He, L., Zhao, W.J., & Bhatia, S. (in press a). An ontology of decision models. Psychological Review.
He, L., Pantelis, P. P., & Bhatia, S. (in press b). The wisdom of model crowds. Management Science.
Hertwig, R., & Erev, I. (2009). The description–experience gap in risky choice. Trends in Cognitive Sciences, 13(12), 517–523.
Hicks, J. R. (1939). Value and Capital: An Inquiry into Some Fundamental Principles of Economic Theory. Clarendon Press.
Hogarth, R. M., & Einhorn, H. J. (1990). Venture theory: A model of decision weights. Management Science, 36(7), 780–803.
Hogarth, R. M., & Karelaia, N. (2005). Simple models for multiattribute choice with many alternatives: When it does and does not pay to face trade-offs with binary attributes. Management Science, 51(12), 1860–1872.
Holyoak, K. J., & Morrison, R. G. (2012). The Oxford handbook of thinking and reasoning. Oxford University Press.
Holyoak, K. J., & Simon, D. (1999). Bidirectional reasoning in decision making by constraint satisfaction. Journal of Experimental Psychology: General, 128(1), 3–31.
Houston, D. A., Sherman, S. J., & Baker, S. M. (1989). The influence of unique features and direction of comparison of preferences. Journal of Experimental Social Psychology, 25(2), 121–141.
Howes, A., Warren, P. A., Farmer, G., El-Deredy, W., & Lewis, R. L. (2016). Why contextual preference reversals maximize expected value. Psychological Review, 123(4), 368–391.
Huber, O. (1979). Nontransitive multidimensional preferences: Theoretical analysis of a model. Theory and Decision, 10(1), 147–165.
Hunt, L. T., Dolan, R. J., & Behrens, T. E. (2014). Hierarchical competitions subserving multiattribute choice. Nature Neuroscience, 17(11), 1613–1622.
Hutchinson, J. W. (1986). Discrete attribute models of brand switching. Marketing Science, 5(4), 350–371.
Jia, J., Dyer, J. S., & Butler, J. C. (2001). Generalized disappointment models. Journal of Risk and Uncertainty, 22(1), 59–78.
Kable, J. W., & Glimcher, P. W. (2010). An “as soon as possible” effect in human intertemporal decision making: behavioral evidence and neural mechanisms. Journal of Neurophysiology, 103(5), 2513–2531.
Kahneman, D. (2000). Preface. In D. Kahneman, A. Tversky, (Eds). Choices, Values and Frames. Cambridge University Press.
Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47(2), 263–291.
Kaplan, R. and Frosch, D. (2005). Decision making in medicine and health care. Annual Review of Clinical Psychology, 1, 525–56.
Karmarkar, U. S. (1978). Subjectively weighted utility: A descriptive extension of the expected utility model. Organizational Behavior and Human Performance, 21(1), 61–72.
Keeney, R. L., & Raiffa, H. (1993). Decisions with multiple objectives: preferences and value trade-offs. Cambridge university press.
Killeen, P. R. (2009). An additive-utility model of delay discounting. Psychological Review, 116(3), 602–619.
Kivetz, R., Netzer, O., & Srinivasan, V. (2004). Alternative models for capturing the compromise effect. Journal of Marketing Research, 41(3), 237–257.
Koopmans, T. C. (1960). Stationary ordinal utility and impatience. Econometrica: Journal of the Econometric Society, 28(2), 287–309.
Kőszegi, B., & Rabin, M. (2007). Reference-dependent risk attitudes. The American Economic Review, 97(4), 1047–1073.
Kőszegi, B., & Szeidl, A. (2013). A model of focusing in economic choice. The Quarterly Journal of Economics, 128(1), 53–104.
Krajbich, I., Armel, C., & Rangel, A. (2010). Visual fixations and the computation and comparison of value in simple choice. Nature Neuroscience, 13(10), 1292–1298.
Krantz, D. H., Atkinson, R. C., Luce, R. D., & Suppes, P. (1974). Contemporary developments in mathematical psychology. W. H. Freeman.
Laibson, D. (1997). Golden eggs and hyperbolic discounting. The Quarterly Journal of Economics, 112(2), 443–478.
Lattimore, P. K., Baker, J. R., & Witte, A. D. (1992). The influence of probability on risky choice: A parametric examination. Journal of Economic Behavior & Organization, 17(3), 377–400.
Lee, M. D., & Cummins, T. D. (2004). Evidence accumulation in decision making: Unifying the “take the best” and the “rational” models. Psychonomic Bulletin & Review, 11(2), 343–352.
Leland, J. W. (1994). Generalized similarity judgments: An alternative explanation for choice anomalies. Journal of Risk and Uncertainty, 9(2), 151–172.
Leland, J. W. (2002). Similarity judgments and anomalies in intertemporal choice. Economic Inquiry, 40(4), 574–581.
Lichtenstein, S., & Slovic, P. (2006). The construction of preference. Cambridge University Press.
Lieder, F., Griffiths, T. L., & Hsu, M. (2017). Overrepresentation of Extreme Events in Decision Making Reflects Rational Use of Cognitive Resources. Psychological Review, 125(1), 1–32.
Loewenstein, G., & Prelec, D. (1992). Anomalies in intertemporal choice: Evidence and an interpretation. The Quarterly Journal of Economics, 107(2), 573–597.
Loewenstein, G., & Prelec, D. (1993). Preferences for sequences of outcomes. Psychological Review, 100(1), 91–108.
Loewenstein, G., & Sicherman, N. (1991). Do Workers Prefer Increasing Wage Profiles? Journal of Labor Economics, 9(1) 67–-84.
Loewenstein, G., O’Donoghue, T., & Bhatia, S. (2015). Modeling the interplay between affect and deliberation. Decision, 2 (2), 55–62.
Loomes, G. (2010). Modeling choice and valuation in decision experiments. Psychological Review, 117(3), 902–924.
Loomes, G., & Sugden, R. (1982). Regret theory: An alternative theory of rational choice under uncertainty. The Economic Journal, 92(368), 805–824.
Loomes, G., & Sugden, R. (1986). Disappointment and dynamic consistency in choice under uncertainty. The Review of Economic Studies, 53(2), 271–282.
Lopes, L. L. (1987). Between hope and fear: The psychology of risk. Advances in Experimental Social Psychology, 20, 255–295.
Louie, K., Khaw, M. W., & Glimcher, P. W. (2013). Normalization is a general neural mechanism for context-dependent decision making. Proceedings of the National Academy of Sciences, 110(15), 6139–6144.
Luce, R. D. (1959). Individual Choice Behavior: A Theoretical Analysis. New York: Wiley.
Luce, R. D., & Fishburn, P. C. (1991). Rank-and sign-dependent linear utility models for finite first-order gambles. Journal of Risk and Uncertainty, 4(1), 29–59.
Machina, M. J. (1982). ” Expected Utility" Analysis without the Independence Axiom. Econometrica: Journal of the Econometric Society, 50(2), 277–323.
Marchiori, D., Di Guida, S., & Erev, I. (2015). Noisy retrieval models of over-and undersensitivity to rare events. Decision, 2(2), 82–106.
Marewski, J. N., & Mehlhorn, K. (2011). Using the ACT-R architecture to specify 39 quantitative process models of decision making. Judgment and Decision Making, 6(6), 439–519.
Markowitz, H. (1952). The utility of wealth. Journal of Political Economy, 60(2), 151–158.
Markowitz, H. (1959). Portfolio selection: Efficient diversification of investments. Wiley.
Marley, A. A., & Luce, R. D. (2001). Ranked-weighted utilities and qualitative convolution. Journal of Risk and Uncertainty, 23(2), 135–163.
Mazur, J.E. (1987). An adjusting procedure for studying delayed reinforcement. In: Commons M.L, Mazur J.E, Nevin J.A, Rachlin H, editors. Quantitative analysis of behavior: Vol. 5. The effect of delay and of intervening events of reinforcement value. Erlbaum; 1987. pp. 55–73.
McClure, S. M., Laibson, D. I., Loewenstein, G., & Cohen, J. D. (2004). Separate neural systems value immediate and delayed monetary rewards. Science, 306(5695), 503–507.
Mellers, B., & Biagini, K. (1994). Similarity and choice. Psychological Review, 101(3), 505–518.
Mellers, B., Schwartz, A., & Ritov, I. (1999). Emotion-based choice. Journal of Experimental Psychology: General, 128(3), 332–345.
Montgomery, H., & Svenson, O. (1976). On decision rules and information processing strategies for choices among multiattribute alternatives. Scandinavian Journal of Psychology, 17(1), 283–291.
Mukherjee, K. (2010). A dual system model of preferences under risk. Psychological Review, 117(1), 243–255.
Oberauer, K., & Lewandowsky, S. (2019). Addressing the theory crisis in psychology. Psychonomic Bulletin & Review, 26(5), 1596–1618.
Oppenheimer, D. M., & Kelso, E. (2015). Information processing as a paradigm for decision making. Annual Review of Psychology, 66(1), 277–294.
Parducci, A. (1974). Contextual effects: A range-frequency analysis. Handbook of Perception, 2, 127–141.
Payne, J. W., Bettman, J. R., & Johnson, E. J. (1992). Behavioral decision research: A constructive processing perspective. Annual Review of Psychology, 43(1), 87–131.
Payne, J. W., & Braunstein, M. L. (1971). Preferences among gambles with equal underlying distributions. Journal of Experimental Psychology, 87(1), 13–18.
Pitz, G. F., & Sachs, N. J. (1984). Judgment and decision: Theory and application. Annual Review of Psychology, 35(1), 139–164.
Pleskac, T. J., & Busemeyer, J. R. (2010). Two-stage dynamic signal detection: a theory of choice, decision time, and confidence. Psychological Review, 117(3), 864–901.
Prelec, D. (1998). The probability weighting function. Econometrica, 66(3), 497–527.
Prelec, D., & Loewenstein, G. (1998). The red and the black: Mental accounting of savings and debt. Marketing Science, 17(1), 4–28.
Quiggin, J. (1982). A theory of anticipated utility. Journal of Economic Behavior and Organization, 3(4), 323–343.
Rapoport, A., & Wallsten, T. S. (1972). Individual decision behavior. Annual Review of Psychology, 23(1), 131–176.
Read, D. (2001). Is time-discounting hyperbolic or subadditive? Journal of Risk and Uncertainty, 23(1), 5–32.
Read, D., Frederick, S., & Scholten, M. (2013). DRIFT: An analysis of outcome framing in intertemporal choice. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(2), 573–588.
Read, D., & Scholten, M. (2012). Tradeoffs between sequences: weighing accumulated outcomes against outcome-adjusted delays. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38(6), 1675–1688.
Restle, F. (1961). Psychology of judgment and choice: A theoretical essay. Wiley.
Rieskamp, J., Busemeyer, J. R., & Mellers, B. A. (2006). Extending the bounds of rationality: Evidence and theories of preferential choice. Journal of Economic Literature, 44(3), 631–661.
Rieskamp, J., & Otto, P. E. (2006). SSL: a theory of how people learn to select strategies. Journal of Experimental Psychology: General, 135(2), 207–236.
Rigoli, F., Mathys, C., Friston, K. J., & Dolan, R. J. (2017). A unifying Bayesian account of contextual effects in value-based choice. PLOS Computational Biology, 13(10), e1005769.
Roberts, S., & Pashler, H. (2000). How persuasive is a good fit? A comment on theory testing. Psychological Review, 107(2), 358–367.
Roe, R. M., Busemeyer, J. R., & Townsend, J. T. (2001). Multialternative decision field theory: A dynamic connectionst model of decision making. Psychological Review, 108(2), 370–392.
Roelofsma, P. H. (1996). Modeling intertemporal choices: An anomaly approach. Acta Psychologica, 93(1), 5–22.
Ronayne, D., & Brown, G. (2017). Multiattribute Decision by Sampling: An account of the attraction, compromise and similarity effects. Journal of Mathematical Psychology, 81, 11–27.
Rooderkerk, R. P., Van Heerde, H. J., & Bijmolt, T. H. (2011). Incorporating context effects into a choice model. Journal of Marketing Research, 48(4), 767–780.
Rubinstein, A. (1988). Similarity and decision-making under risk (Is there a utility theory resolution to the Allais paradox?). Journal of Economic Theory, 46(1), 145–153.
Rubinstein, A. (2003). “Economics and Psychology”? The Case of Hyperbolic Discounting. International Economic Review, 44(4), 1207–1216.
Russo, J. E., & Dosher, B. A. (1983). Strategies for multiattribute binary choice. Journal of Experimental Psychology: Learning, Memory, and Cognition, 9(4), 676–696.
Samuelson, P. A. (1937). A note on measurement of utility. The Review of Economic Studies, 4(2), 155–161.
Savage, L. J. (1972). The foundations of statistics, 2nd edition. Dover.
Schmidt, U., Starmer, C., & Sugden, R. (2008). Third-generation prospect theory. Journal of Risk and Uncertainty, 36(3), 203–223.
Scholten, M. (2002). Conflict-mediated choice. Organizational Behavior and Human Decision Processes, 88(2), 683–718.
Scholten, M., & Read, D. (2006). Discounting by intervals: A generalized model of intertemporal choice. Management Science, 52(9), 1424–1436.
Scholten, M., & Read, D. (2010). The psychology of intertemporal tradeoffs. Psychological Review, 117(3), 925–944.
Scholten, M., Read, D., & Sanborn, A. (2014). Weighing outcomes by time or against time? Evaluation rules in intertemporal choice. Cognitive Science, 38(3), 399–438.
Scholten, M., Read, D., & Sanborn, A. (2016). Cumulative weighing of time in intertemporal tradeoffs. Journal of Experimental Psychology: General, 145(9), 1177–1205.
Seip, K. L., & Wenstop, F. (2006). A Primer on environmental decision making. Springer.
Sheng, S., Parker, A. M., & Nakamoto, K. (2005). Understanding the mechanism and determinants of compromise effects. Psychology & Marketing, 22(7), 591–609.
Shenoy, P., & Yu, A J (2013). A rational account of contextual effects in preference choice: What makes for a bargain? Proceedings of the 35th Annual Cognitive Science Society Conference.
Sher, S., & McKenzie, C. R. (2014). Options as information: Rational reversals of evaluation and preference. Journal of Experimental Psychology: General, 143(3), 1127–1143.
Simon, H. A. (1955). A behavioral model of rational choice. The Quarterly Journal of Economics, 69 (1), 99–118.
Simonson, I., Carmon, Z., Dhar, R., Drolet, A., & Nowlis, S. M. (2001). Consumer research: In search of identity. Annual Review of Psychology, 52(1), 249–275.
Slovic, P. (1987). Perception of risk. Science, 236(4799), 280–285.
Slovic, P., Fischhoff, B., & Lichtenstein, S. (1977). Behavioral decision theory. Annual Review of Psychology, 28(1), 1–39.
Slovic, P., & Lichtenstein, S. (1968). Relative importance of probabilities and payoffs in risk taking. Journal of Experimental Psychology, 78(32), 1–18.
Soltani, A., De Martino, B., & Camerer, C. (2012). A range-normalization model of context-dependent choice: a new model and evidence. PLoS Computational Biology, 8(7), e1002607.
Starmer, C. (2000). Developments in non-expected utility theory: The hunt for a descriptive theory of choice under risk. Journal of Economic Literature, 38(2), 332–382.
Stewart, N., Chater, N., & Brown, G. D. (2006). Decision by sampling. Cognitive psychology, 53(1), 1–26.
Thaler, R. H., & Sunstein, C. R. (2009). Nudge: Improving decisions about health, wealth, and happiness. Penguin.
Thorngate, W. (1980). Efficient decision heuristics. Behavioral Science, 25(3), 219–225.
Thurstone, L. L. (1927). A law of comparative judgment. Psychological Review, 34(4), 273–286.
Trautmann, S., & van de Kuilen, G. (2015). Ambiguity attitudes. In G. Keren & G. Wu (Eds.). The Wiley Blackwell Handbook of Judgment and Decision Making, Blackwell.
Triantaphyllou, E. (2013). Multi-criteria decision making methods: a comparative study. Springer Science & Business Media.
Trueblood, J. S., Brown, S. D., & Heathcote, A. (2014). The multiattribute linear ballistic accumulator model of context effects in multialternative choice. Psychological Review, 121(2), 179–205.
Tsetsos, K., Chater, N., & Usher, M. (2012). Salience driven value integration explains decision biases and preference reversal. Proceedings of the National Academy of Sciences, 109(24), 9659–9664.
Tversky, A. (1969). Intransitivity of preferences. Psychological Review, 76(1), 31–48.
Tversky, A. (1972). Elimination by aspects: A theory of choice. Psychological Review, 79(4), 281–289.
Tversky, A., & Kahneman, D. (1991). Loss aversion in riskless choice: A reference-dependent model. The Quarterly Journal of Economics, 104(4), 1039–1061.
Tversky, A., & Kahneman, D. (1992). Advances in prospect theory: Cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5(4), 297–323.
Tversky, A., & Simonson, I. (1993). Context-dependent preferences. Management Science, 39(10), 1179–1189.
Usher, M., & McClelland, J. L. (2004). Loss aversion and inhibition in dynamical models of multialternative choice. Psychological Review, 111(3), 757–769.
Usher, M., & Zakay, D. (1993). A Neural Network Model for Attribute-Based Decision Processes. Cognitive Science, 17(3), 349–396.
Viscusi, W. K. (1989). Prospective reference theory: Toward an explanation of the paradoxes. Journal of Risk and Uncertainty, 2(3), 235–263.
Von Neumann, J., & Morgenstern, O. (1944). Theory of games and economic behavior. Princeton University Press.
Wakker, P. (2010). Prospect theory: For risk and ambiguity. Cambridge University Press.
Wakker, P., & Tversky, A. (1993). An axiomitization of cumulative prospect theory. Journal of Risk and Uncertainty, 7(2), 147–175.
Wang, X. J. (2002). Probabilistic decision making by slow reverberation in cortical circuits. Neuron, 36(5), 955–968.
Wathieu, L. (1997). Habits and the anomalies in intertemporal choice. Management Science, 43(11), 1552–1563.
Weber, E. U., & Johnson, E. J. (2009). Mindful judgment and decision making. Annual Review of Psychology, 60, 53–85.
Weber, E. U., Shafir, S., & Blais, A. R. (2004). Predicting risk sensitivity in humans and lower animals: risk as variance or coefficient of variation. Psychological Review, 111(2), 430–445.
Wedell, D. H., & Pettibone, J. C. (1996). Using judgments to understand decoy effects in choice. Organizational Behavior and Human Decision Processes, 67(3), 326–344.
Weingarten, E., Bhatia, S., & Mellers, B. (2019). Multiple goals as reference points: One failure makes everything else feel worse. Management Science, 65(7), 2947–3448.
Weiss, J. W., Weiss, D. J., & Edwards, W. (2010). A descriptive multiattribute utility model for everyday decisions. Theory and Decision, 68(2), 101–114.
Wilcox, N. T. (2008). Stochastic models for binary discrete choice under risk: A critical primer and econometric comparison. In James C. Cox & Glenn W. Harrison (Eds). Risk Aversion in Experiments (pp. 197–292). Emerald Group Publishing Limited.
Wilcox, N. T. (2011). ‘Stochastically more risk averse:’A contextual theory of stochastic discrete choice under risk. Journal of Econometrics, 162(1), 89–104.
Wollschläger, L. M., & Diederich, A. (2012). The 2N-ary choice tree model for N-alternative preferential choice. Frontiers in Psychology, 3, 189.
Yaari, M. E. (1987). The dual theory of choice under risk. Econometrica, 55(1). 95–115.
Copyright: © 2021. The authors license this article under the terms of the Creative Commons Attribution 3.0 License.
This document was translated from LATEX by HEVEA.